阿里云ECS7安装搭建:hadoop2.7.6分布式集群
简介
- hadoop是一个分布式系统基础架构,是大数据生态的一个总称;
- 核心设计包括:HDFS和MapReduce,HDFS为海量数据提供了存储,而MapReduce则为海量数据提供了计算;
- 本篇博客则主要描述在阿里云服务器下部署hadoop集群
环境准备
- 两台阿里云服务器(实验环境,正式环境建议使用三台或以上部署集群)centos_7,一台为主,另一台为从;
- 两台服务器分别安装jdk1.8环境;
- 下载hadoop版本安装包:hadoop-2.7.6.tar.gz
配置服务器(两台服务器都配)
1. 修改服务器hosts:vim /etc/hosts
#阿里云使用内网ip,不用外网ip
172.11.111.12 hadoop-master
172.11.111.13 hadoop-slave2. 修改服务器的hostname
方式1:直接修改服务器配置文件:vim /etc/hostname
#删掉localhost
主节点修改成:hadoop-master
从节点修改成:hadoop-slave执行reboot,重启服务器
方式2:在阿里云管理后台修改


重启阿里云服务器,然后hostname生效;
安装java-jdk1.8(两台服务器都安装)
1. 自行下载jdk1.8.0_152.tar.gz(网上一堆资源,不上传),解压至:/root/tools/jdk1.8.0_152
2. 配置环境变量:vim /etc/profile
export JAVA_HOME=/root/tools/jdk1.8.0_152
export PATH=$PATH:$JAVA_HOME/bin3. 执行生效命令:source /etc/profile
4. 测试java版本:java -version

设置服务器ssh免密登录
1. 设置master本机免密登录:
#生成免密key
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
#授权
$ chmod 600 ~/.ssh/authorized_keys
#测试是否成功,如果不需要输入密码则成功
$ ssh localhost(或者hadoop-master)
#退出
$ exit2. 设置hadoop-master免密登录到hadoop-slave:
$ ssh-copy-id hadoop-slave3. 在hasoop-master上测试,如果不需要输入密码,则说明主从免密登录配置成功:
$ ssh hadoop-slave
#退出
$ exit问题及解决:如果使用root用户依旧需要登录密码,则切换成hadoop用户
配置hadoop环境变量(两台服务器都要)
1. 新建hadoop用户(以上操作用的是root用户,以下操作都用hadoop用户)
$ useradd hadoop && echo hadoop | passwd --stdin hadoop
$ echo "hadoop ALL=(ALL) NOPASSWD:ALL" >> /etc/sudoers2. 将hadoop的文件夹权限转换成hadoop
$ sudo chown -R hadoop:hadoop hadoop/3. 将hadoop-2.7.6.tar.gz压缩包上传至:/data/hadoop/hadoop/
4. 解压hadoop到当前文件夹:tar -xzvf hadoop-2.7.6.tar.gz
5. 重命名:mv hadoop-2.7.6 hadoop
6. 切换root用户,配置hadoop的环境变量:vim /etc/profile
export HADOOP_HOME=/data/hadoop/hadoop/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin7. 文件立即生效:source /etc/profile
8. 检验当前的hadoop版本:hadoop version

配置hadoop文件
1. 在hadoop同级目录下新建文件夹:
$ cd /data/hadoop/hadoop
$ mkdir tmp
$ mkdir hdfs
$ mkdir hdfs/data
$ mkdir hdfs/name
2. 切换配置文件路径:cd /data/hadoop/hadoop/hadoop/etc/hadoop
3. 配置core-site.xml:
fs.defaultFS
hdfs://hadoop-master:9000
hadoop.tmp.dir
file:/data/hadoop/hadoop/tmp
io.file.buffer.size
131072
4. 配置hdfs-site.xml
dfs.namenode.name.dir
file:/data/hadoop/hadoop/hdfs/name
dfs.datanode.data.dir
file:/data/hadoop/hadoop/hdfs/data
dfs.replication
1
dfs.namenode.secondary.http-address
hadoop-master:9001
dfs.webhdfs.enabled
true
5. 配置mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
hadoop-master:10020
mapreduce.jobhistory.webapp.address
hadoop-master:19888
6. 配置yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.address
hadoop-master:8032
yarn.resourcemanager.scheduler.address
hadoop-master:8030
yarn.resourcemanager.resource-tracker.address
hadoop-master:8031
yarn.resourcemanager.admin.address
hadoop-master:8033
yarn.resourcemanager.webapp.address
hadoop-master:8088
7. 配置slaves文件(该文件指定datanode从节点所在的服务器ip,这里实验环境只有两台服务器,所以将主节点master也加上去)
hadoop-master
hadoop-slave8. 配置hadoop-env.sh(修改JAVA_HOME映射路径)
export JAVA_HOME=/root/tools/jdk1.8.0_152
同步hadoop到slave节点
1. 如果从节点slave还没有hadoop解压的压缩包,则直接同步所有的hadoop文件:
$ scp -r /data/hadoop/hadoop hadoop-slave:/data/hadoop/hadoop2. 如果已经存在压缩包,则直接将etc/hadoop下的所有改动的配置文件覆盖到slave对应的目录下;
格式化hdfs
1. 在hadoop-master服务器上,切换hadoop用户:su hadoop;
2. 执行命令:hdfs namenode -format;

启动以及关闭hadoop
1. 在hadoop-master节点,切换hadoop用户,执行命令:start-all.sh
2. 在hadoop-master节点执行命令:jps,则会看到以下进程:

3. 在hadoop-slave节点执行命令:jps,则会看到以下进程:
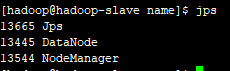
4. 如果发现有关的进程不存在,则可以对应查看相关的日志来查看出错问题,切换日志目录:
$ cd /data/hadoop/hadoop/hadoop/logs
阿里云配置外网访问安全组规则:
允许50070以及8088端口访问:

外网访问hadoop节点状态
1. 8088 查看yarn管理界面: http://47.107.123.266:8088

2. 50070 查看hdfs管理界面: http://47.107.123.266:50070

总结
1. hadoop主要应用于大数据量的生态架构,集群配置在生产环境下,建议至少配4台服务器(一台主节点,三台数据节点);
2. 实践是检验认识真理性的唯一标准,自己动手,丰衣足食~