利用nutch、hbase和solr搭建搜索引擎
我感觉搜索引擎是互联网界最伟大的技术,它让我们在网上查询变得异常方便。
公司近期需要搭建一个站内搜索引擎,用来方便客户查询数据。借此机会学习下搜索引擎的搭建和原理。
开源界最完善的开源环境就是利用nutch、hbase与solr搭配的。nutch用来爬取数据,hbase存取数据,solr建立索引并支持在线搜索。
由于nutch只能在类unix操作系统下运行,所以建议安装linux操作系统或其他类unix操作系统。我安装的是linuxmint17。
配置nutch相关的项目都需要依赖jdk,所以要自己安装jdk,从oracle官网下载相关jdk,建议使用jdk1.7版本。安装及配置环境变量请从网络上查找,不再赘述。
1、hbase环境搭建
从官网下载hbase安装包:http://www.apache.org/dyn/closer.cgi/hbase/
我下载的版本为hbase-0.94.27,解压到指定目录下,我在我的home目录下建立App目录,把自己解压安装的绿色软件放到此目录下。
我们把hbase的主目录成为$HBASE_HOME。
解压后,需要修改配置文件$HBASE_HOME/conf/hbase-site.xml,在节点
hbase.rootdir
file://$HBASE_HOME/data/hbase
hbase.zookeeper.property.dataDir
$HBASE_HOME/data/zookeeper
切换到$HBASE_HOME目录下,执行服务启动命令:
./bin/start-hbase.sh
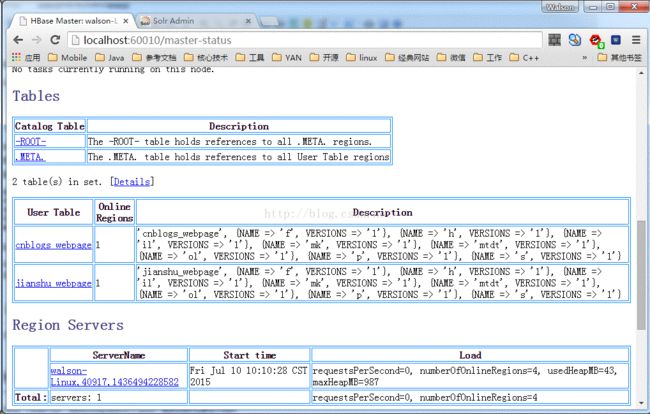
即可启动服务,通过浏览器,访问如下网址:http://localhost:60010/master-status
若可以访问如下页面,说明启动成功:

hbase有自己的shell,可以通过shell来对数据进行操作,进入shell的命令如下:
首先要进入$HBASE_HOME主目录,然后执行命令
./bin/hbase shelldisable 'table_name'drop 'table_name'2、nutch-2.3环境搭建
当前版本为nutch-2.3,2.x版本没有已编译好的安装包,仅有源代码,需要自己编译。可能是因为在编译之前需要修改配置文件,而编译好的很多文件都依赖于修改的配置文件。nutch的编译需要ant,所以需要安装ant并配置环境变量。
从官方下载源代码:http://nutch.apache.org/downloads.html
解压到指定目录下,在此把nutch主目录称为$NUTCH_HOME。
nutch是通过ivy来管理包的依赖的,通过命令行进入$NUTCH_HOME,通过vim打开ivy.xml文件
vim ./ivy/ivy.xml保存: :wq
然后打开配置文件:./conf/gora.properties
vim ./conf/gora.propertiesgora.datastore.default=org.apache.gora.hbase.store.HBaseStore
保存 :wq打开配置文件./conf/nutch-site.xml
添加如下内容:
storage.data.store.class
org.apache.gora.hbase.store.HBaseStore
Default class for storing data
http.agent.name
Your Nutch Spider
http.accept.language
zh-cn, en-us,en-gb,en;q=0.7,*;q=0.3
*
parser.character.encoding.default
utf-8
*
storage.data.store.class
org.apache.gora.sql.store.SqlStore
*
generate.batch.id
*
保存。
配置完成,编译nutch,在主目录下,运行如下命令:
ant runtime编译好后,主目录下就会多了两个目录build和runtime。
编译好的程序在runtime目录下,并且此目录下有两个文件夹:deploy和local,分别代表两种模式:部署模式和本地模式。
我们这里仅使用本地模式,部署模式请参考:http://blog.csdn.net/jediael_lu/article/details/42058553
3、solr环境搭建
从官网下载solr安装包:http://archive.apache.org/dist/lucene/solr/
由于nutch-2.3的$NUTCH_HOME/conf/schema.xml中指定支持solr4.x的版本,所以我下载的版本为:solr-4.9.1
解压到指定目录,我们把solr主目录称为$SOLR_HOME。
首先备份配置文件$SOLR_HOME/example/solr/collection1/conf/schema.xml
然后把$NUTCH_HOME/runtime/local/conf/schema.xml拷贝到$SOLR_HOME/example/solr/collection1/conf目录下,覆盖schema.xml文件。
此文件主要是抓取的数据结构定义。
配置完成后,就可以启动solr服务了。进入$SOLR_HOME/example下,执行如下命令:
java -jar start.jar
在昨天的core Selector中选择collection1,里面有通过solr执行查询和编辑功能。
清除索引
1、打开documents,在页面里选择Document Type 为XML,然后在Documents里输入:
清除指定索引:
id:1 清除所有索引:
*:* 4、开启服务
hbase 服务和solr服务都启动后,就可以通过nutch抓取数据了。
在目录$NUTCH_HOME/runtime/local下建立urls文件夹,并在此文件夹下建议seed.txt文件,里面保存的是要抓取的网站地址,例如:http://www.cnblogs.com
然后执行./bin/crawl命令抓取数据,命令格式如下:
Usage: crawl []
:放置种子文件的目录
:抓取任务的ID
:用于索引及搜索的solr地址
:迭代次数,即抓取深度 例如:
./bin/crawl ./urls cnblogs http://localhost:8983/solr 2
在solr站点可以搜索相应数据,如下图: