语音识别初探——一文读懂语音识别技术原理
语音识别是十年来发展最快的技术之一,随着AI的不断发展,深度学习让语音识别技术得到了质的飞跃,开始从实验室走向市场,并逐步走到人们的生活中。
我们现在所用的语音输入法,以及以语音为智能交互入口的智能家居,背后都涉及到语音识别技术。
文章目录
- 01语音识别技术的发展历程
- 02 语音识别的技术原理
- 03 语音识别技术的典型应用
01语音识别技术的发展历程
语音识别技术是指机器自动将人的语音的内容转成文字,又称 Automatic Speech Recognition,即ASR技术。
语音识别是一门交叉的、非常复杂的学科,需要具备生理学、声学、信号处理、计算机科学、模式识别、语言学、心理学等相关学科的知识。
语音识别的研究是个漫长而且艰难的过程,它的发展可以追溯到20世纪50年代,1952年贝尔实验室首次实现Audrey英文数字识别系统,这个系统当时可以识别单个数字0~9的发音,并且对熟人的准确度高达90%以上。
在同时期,MIT、普林斯顿相继推出少量词的独立词识别系统。

1971年美国国防部研究所(DARPA)赞助了五年期限的语音理解研究项目,推动了语音识别的一次大发展。DARPA在整个科技的发展过程中扮演了非常重要的角色,它专门给高科技研究项目提供资金支持,包括无人机、卫星等等。
在DARPA的支持下,IBM、卡内基梅隆大学(CMU)、斯坦福等学术界和工业界非常顶级的研究机构也都加入到语音识别的研究中去。
其中,卡耐基梅隆大学研发出harpy语音识别系统,该系统能够识别1011个单词,在这个时期大词汇量的孤立词识别取得实质性进展。

到了1980年,语音识别技术已经从从孤立词识别发展到连续词识别,当时出现了两项非常重要的技术:隐马尔科夫模型( HMM )、N-gram语言模型。
1990年,大词汇量连续词识别持续进步,提出了区分性的模型训练方法MCE和MMI,使得语音识别的精确度日益提高,尤其适用于长句子的情况下,与此同时,还提出了模型自适应方法MAP和MLLR。
在工业方面,剑桥推出首个开源的语音识别训练工具HTK,在商业方面,Nuance发布了首个消费级产品Dragon Dictate。
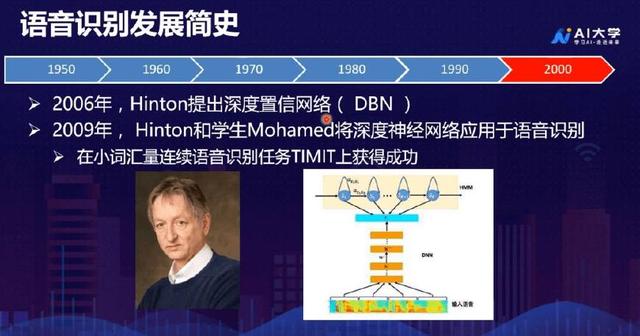
到了21世纪,随着深度学习的不断发展,神经网络之父Hinton提出深度置信网络( DBN ),2009年, Hinton和学生Mohamed将深度神经网络应用于语音识别,在小词汇量连续语音识别任务TIMIT上获得成功。
02 语音识别的技术原理
从20世纪80年代开始,现在语音识别采用模式识别的基本框架,分为数据准备、特征提取、模型训练、测试应用这4个步骤,在这里我们主要来讲解下模型训练和测试应用。
模型经过训练之后,一段待测的语音需要经过信号处理和特征提取,然后利用训练好的声学模型和语言模型,分别求得声学模型和语言模型得分,然后综合这2个得分,进行候选的搜索,最后得出语言识别的结果。
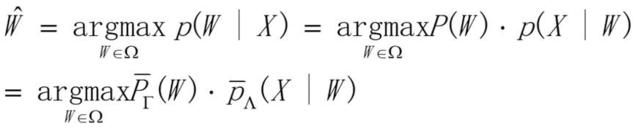
公式表达如图所示
接下来我们来看下语言模型,语言模型的物理意义反映字词出现的先验概率,比如“郝”和“好”,这两个字发音相同,但“郝”相对于“好”来说,出现的概率较低,一般都会出现在姓氏里。
除此之外,语言模型的物理意义还在于反映词顺序是否符合语言习惯和反映词的语义信息。
了解了语言模型的物理意义,我们来看下语言模型的建模,传统语言模型采用N-gram的做法,语言模型是对文本序列的先验概率进行建模,用以下公式表示:
()=(1 2 …w )=(1 )(2│1 )…( |(1:1))
我们按照全概率空间展开,可以表示为第一个词出现的概率(1)乘以第一个词出现之后,第二个词的概率(2│1 ),以此类推一直到第n个词。

对于这样一个全概率空间,我们对它进行N-阶马尔科夫假设,即每个词出现的概率只和最近的N个历史词有关,根据这样一个假设,上面表示先验概率中的每一项都可以做这样一个近似:
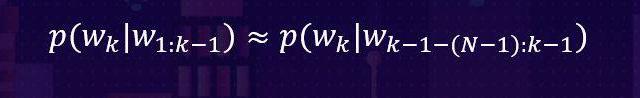
比如我们需要求1-阶马尔科夫假设,用以下公式即可很方便的算出结果:
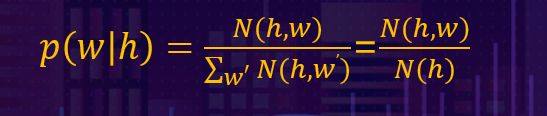
这样一种看似很简单的非参数的计算方法,却从20世纪的80年代一直沿用到今天。
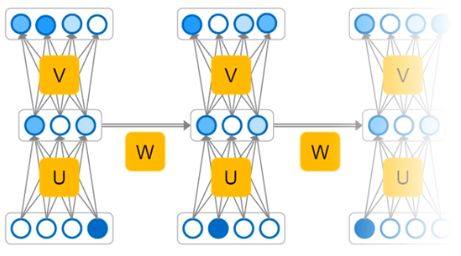
在深度学习出现之后,逐渐出现了另一种语言模型——RNNLM。
RNNLM语言模型的流程,之前我们提到过先验概率可以按照全概率空间进行展开,我们对公式中间的每一项都采用同一种深度学习模型来建模,就可以表达成如下结构:
说完了语言模型建模,接下来我们来说下声学模型建模,给定了相应的文本序列之后,生成相应的语音,这是语音识别技术中最核心的也是最复杂的部分。
为了减少同音词的数据共享问题,首先我们会将文本序列转化成它的发音序列,做这一步的目的就是加强建模单元的共享性。
在我们对每一个发音单元,比如“xue”里面的韵母做建模的时候,我们的语音具有不定长的特性,我们说的快和说的慢的时候,语音帧的时长是不一样的,对于这种不定长的语音建模,这个时候就需要引入HMM模型。
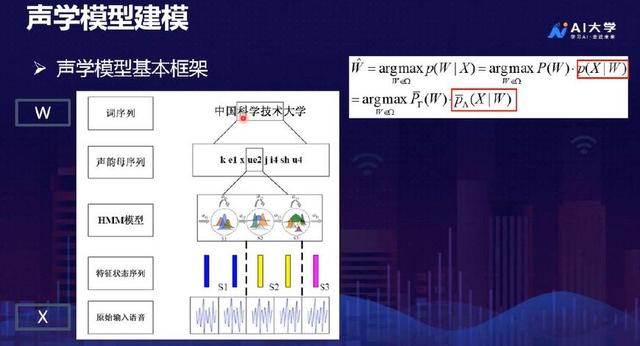
HMM模型每一个语音帧让我们的每一个语音帧都对应到HMM模型中的每一个状态,不论多长的语音都能够表达为HMM模型的一个状态序列。
最后只要将HMM模型中的序列和我们语音中的每一帧进行一一对应。再将这个对应关系,用一个概率来表达就可以了。
我们知道语音其实是非常复杂多变的,不同的人在说同样的句子的时候,会表现出非常大的差异性。
1980年代的时候,由于计算条件的限制,业内一般采用GMM声学模型,到了2010年深度学习技术兴起,DNN声学建模开始取代GMM声学建模。
03 语音识别技术的典型应用
语音识别技术早期的应用主要是语音听写,用户说一句,机器识别一句。后来发展成语音转写,随着AI的发展,语音识别开始作为智能交互应用中的一环。
下面我们就来一一介绍这些应用:
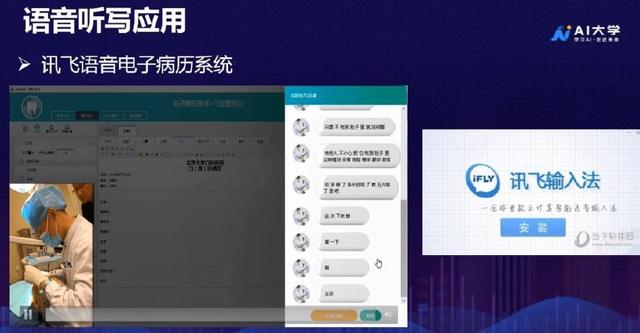
首先我们来看下语音听写,语音听写中最为典型的案例就是讯飞输入法,除此之外,语音听写的应用还有语音病例系统。
医生佩戴上讯飞定制的麦克风,在给病人诊断时,会将病情、用药、需要注意事项等信息说出来,机器将医生说的话自动识别出来,生成病例。
关于语音转写的应用,另外两个产品的例子,一是讯飞语记,另一个是讯飞听见。
讯飞语记是一款APP,它能够将我们所说的语音记录成文字,讯飞听见会议系统能够实时的根据演讲者所说的内容准确识别出来,并且实时投影在我们的大屏幕上。
关于语音交互的产品有很多,比如讯飞推出的讯飞翻译机、能够和小朋友进行互动的阿法蛋、以及可以进行聊天交流的叮咚音箱等。
参考文章:https://baijiahao.baidu.com/s?id=1605133369887843752&wfr=spider&for=pc