1.概述
为什么这份文档里面我们要安装这么多集群呢?我这里大至说一下原因,TIDB4.0我们主要是用于存储大量数据用的,也就是永久化存储,而Spark是面向内存的。这使得Spark能够为多个不同数据源的数据提供近乎实时的处理计算性能,适用于需要多次操作特定数据集的应用场景。进行我们想要的离线计算,然后生成报表再回写到TIDB之中。
2.安装TIDB生成环境硬件要求
| 组件 |
CPU |
内存 |
硬盘类型 |
网络 |
数量(最低要求) |
| TiDB |
16核+ |
32 GB+ |
SAS |
万兆网卡(2块最佳) |
2 |
| PD |
4核+ |
8GB+ |
SSD |
万兆网卡(2块最佳) |
3 |
| TiKV |
16核+ |
32 GB+ |
SSD |
万兆网卡(2块最佳) |
3 |
| TiFlash |
48核+ |
128 GB+ |
1 or more SSDs |
万兆网卡(2 块最佳) |
2 |
| TiCDC |
16 核+ |
64 GB+ |
SSD |
万兆网卡(2 块最佳) |
2 |
| 监控 |
8核+ |
16 GB+ |
SAS |
千兆网卡 |
1 |
|
|
|
|
|
服务器总计 |
13 |
注:
- 生产环境中的 TiDB 和 PD 可以部署和运行在同服务器上,如对性能和可靠性有更高的要求,应尽可能分开部署。
- 生产环境强烈推荐使用更高的配置。
- TiKV 硬盘大小配置建议 PCI-E SSD 不超过 2 TB,普通 SSD 不超过 1.5 TB。
- TiFlash 支持多盘部署。
- TiFlash 数据目录的第一块磁盘推荐用高性能 SSD 来缓冲 TiKV 同步数据的实时写入,该盘性能应不低于 TiKV 所使用的磁盘,比如 PCI-E SSD。并且该磁盘容量建议不小于总容量的 10%,否则它可能成为这个节点的能承载的数据量的瓶颈。而其他磁盘可以根据需求部署多块普通 SSD,当然更好的 PCI-E SSD 硬盘会带来更好的性能。
- TiFlash 推荐与 TiKV 部署在不同节点,如果条件所限必须将 TiFlash 与 TiKV 部署在相同节点,则需要适当增加 CPU 核数和内存,且尽量将 TiFlash 与 TiKV 部署在不同的磁盘,以免互相干扰。
- TiFlash 硬盘总容量大致为:
整个TiKV集群的需同步数据容量/ TiKV副本数* TiFlash副本数。例如整体 TiKV 的规划容量为 1 TB、TiKV 副本数为 3、TiFlash 副本数为 2,则 TiFlash 的推荐总容量为1024 GB / 3 * 2。用户可以选择同步部分表数据而非全部,具体容量可以根据需要同步的表的数据量具体分析。 - TiCDC 硬盘配置建议 200 GB+ PCIE-SSD。
3.安装TIDB的虚拟机硬件环境
处理器:I7系列CPU
内存16G
硬盘:SSD 100G
Vm虚拟机:8个VM虚拟机,每台虚拟配给1G内存,操作系统Centos8上,请确保主机和虚拟机能联上外网
| 机器名 |
IP |
操作系统 |
配置 |
用途 |
| TiDB1 |
192.168.22.36 |
CentOS8 X64 |
20G硬盘空间 |
TiKV+TiSpark |
| TiDB2 |
192.168.22.137 |
CentOS8 X64 |
20G硬盘空间 |
TiKV+TiSpark |
| TiDB3 |
192.168.22.138 |
CentOS8 X64 |
20G硬盘空间 |
TiKV+TiSpark |
| TiDB4 |
192.168.22.139 |
CentOS8 X64 |
20G硬盘空间 |
Mysql5.7+测试工具 |
| TiDB5 |
192.168.22.140 |
CentOS8 X64 |
20G硬盘空间 |
TiDB+PD |
| TiDB6 |
192.168.22.141 |
CentOS8 X64 |
20G硬盘空间 |
TiDB+PD |
| TiDB7 |
192.168.22.142 |
CentOS8 X64 |
20G硬盘空间 |
TiDB+PD |
| TiDB8 |
192.168.22.143 |
CentOS7.4 X64 |
4C+8G+60G |
中控机Tiup一键安装 |
注:在TiDB3,TiDB4,TiDB5,TiDB6,TiDB8都需要进行操作,后面有说到如何用虚拟机挂载EXT4,这也是关键点,如果不设置成EXT4格式后面会发生各种问题
4.解决单点故障问题
通常分布式系统采用主从模式,一个主机连接多个处理节点,主节点负责分发任务,而子节点负责处理业务,当主节点发生故障时,会导致整个系统发故障,我们把这种故障叫做单点故障。
而按照TIDB官方的说法是最少使用3台PD、2台TIDB、3台TIKV就能解决单点故障问题。
5.关于Spark与TiSpark版本问题
目前TIDB的Tisspark与Spark没有办法高版本兼容低版本,必须版本一致才能使用Spark
连接到TIDB数据库,如果版本不一致将会报错,目前TIDB4.0与hadoop-2.7.2、scala-2.13.3、
hive-3.1.2、jdk1.8.0_231、spark-2.4.0
6.安装前的准备工作
在安装TIDB之前先做完好一些准备工作,包括安装环境,IP地址和主机名称等。
注:如果虚拟机是复制的,一定要将虚拟机的MAC地址重新生成一次,不然会出现不
能联网的问题,在生成MAC之前虚拟机系统先要关闭中,生成之后再启动。


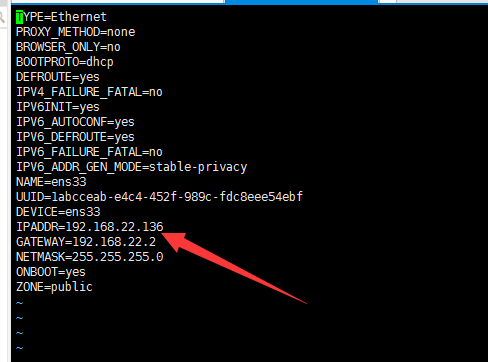
给所有主机分配IP地址
执行 vi /etc/sysconfig/network-scripts/ifcfg-ens33按如下图设置网络环境
其中GATEWAY设的是网关,IPADDR是指定IP地址,必须与现有局域网在同一个网段下
例如:192.168.22.136 NETMASK表示子网掩码
给所有主机重新命名
执行vim /etc/sysconfig/network
添加如下两行
NETWORKING=yes #使用网络
HOSTNAME= TIDB01 #主机名称,主机名称用唯一编号表示

执行vim /etc/hosts
添加如下一行:
192.168.22.136 TIDB01

设好之后重新启动网络
执行
nmcli c reload
nmcli networking on
再使用ping命令ping外网
ping www.baidu.com
如果不通则使用如下命令,先把虚拟IP删除,再添加
Ifconfig ens33 down
Ifconfig ens33 192.168.22.136
再执行
nmcli c reload
nmcli networking on
nmcli c up ens33(虚拟网卡名称)
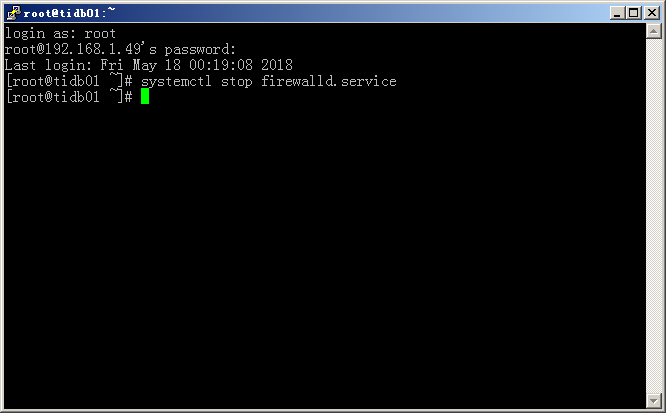
关闭firewalld防火墙
systemctl stop firewalld.service #停止firewall防火墙服务
systemctl disable firewalld.service 关闭防火墙

Centos最小安装之后需要安装的Yum
安装额外yum源
yum install epel-release
更新Centos系统
yum update可以将Centos更新至最新版
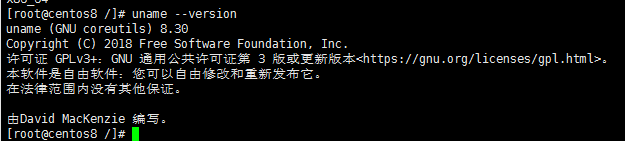
查看Centos版本号信息
uname --version
查看linux内核版本
cat /proc/version
![]()
查看系统是不是64位

给虚拟机添加新的虚拟磁盘空间并转换为EXT4格式
TiDB3,TiDB4,TiDB5,TiDB6,TiDB8都需要进行操作都需要进行操作挂载EXT4数据盘,操作如下:
在VM左侧窗口中对着虚拟主机单击右键设置->硬盘->添加->硬盘-SCSI->创建新虚拟磁盘



然后打开终端:看一下磁盘,sudo fdisk -l
此处的/dev/sdb就是我们新加的磁盘,我们要将其加进来。

给新加的硬盘分区,执行如下命令:
sudo fdisk /dev/sdb

键入m,可看到帮助信息
再键入n表示新分区
再键入p选择基本分区
再键入1表示建一个分区
回车
回车,再回车
键入w ,再回车
格式化磁盘分区
用ext4格式对/dev/sdb进入格式化
mkfs.ext4 /dev/sdb
挂载分区
创建新的挂载点
mkdir /home
将新磁盘分区挂载到/ home目录下
mount -t ext4 /dev/sdb /home
查看挂载
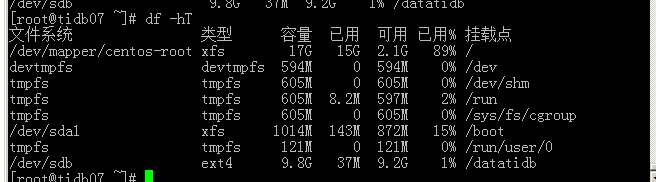
df –hT
可以看到新加的硬盘:/dev/sdb 并且格式是ext4
设置开机自动挂载数据盘ext4参数
TiDB1,TiDB2,TiDB3都需要进行操作挂载EXT4数据盘,操作如下:
修改文件
vi /etc/fstab
加入一行:
/dev/sdb /home ext4 defaults,nodelalloc,noatime 0 0
卸载目录并重新挂载
umount /home
mount -a
确认是否生效,如果生效了会多出nodelalloc
TiDB3,TiDB4,TiDB5,TiDB6,TiDB8都需要进行操作:
mount -t ext4

在TIDB8服务器添加用户
useradd tidb
passwd tidb

设置免密配置文件
visudo
将tidb ALL=(ALL) NOPASSWD: ALL加入到最后一行并保存
登录192.168.22.143虚拟机配置ssh互信免密码登录
执行如下合令:
su - root
ssh-keygen -t rsa 然后一路回车
这时当前用户home目录下面会生成一对密钥,id_rsa 为私钥,id_rsa.pub 为公钥

通过 ssh-copy-id 进行传输公钥
执行下面命令:
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.22.136
然后输入密码

其它虚拟主机一样操作:
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.22.137
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.22.138
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.22.139
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.22.140
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.22.141
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.22.142
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.22.143 #中控机也要这样做
关闭SELinux
所有虚拟主机都需要进操作:
vim /etc/selinux/config
将SELINUX=enforcing改为SELINUX=disabled
设置后需要重启才能生效

安装YUM源默认官方的MySQL客户端
yum install mysql
7. 在中控机上安装 TiUP 组件一键布署
执行如下命令安装 TiUP 工具:
curl --proto '=https' --tlsv1.2 -sSf https://tiup-mirrors.pingcap.com/install.sh | sh
确认 TiUP 工具是否安装:
which tiup
安装 TiUP cluster 组件:
tiup cluster
如果已经安装,则更新 TiUP cluster 组件至最新版本:
tiup update --self && tiup update cluster
预期输出 “Update successfully!” 字样。
验证当前 TiUP cluster 版本信息。执行如下命令查看 TiUP cluster 组件版本
tiup --binary cluster
编译初始化配置文件
指行如下命令:
cd /
vi topology.yaml
按如下进行配置:
# # Global variables are applied to all deployments and used as the default value of
# # the deployments if a specific deployment value is missing.
global:
user: "tidb"
ssh_port: 22
deploy_dir: "/tidb-deploy"
data_dir: "/tidb-data"
pd_servers:
- host: 192.168.22.137
tidb_servers:
- host: 192.168.22.136
tikv_servers:
- host: 192.168.22.138
- host: 192.168.22.139
- host: 192.168.22.140
tiflash_servers:
- host: 192.168.22.141
data_dir: /tidb-data/tiflash-9000
deploy_dir: /tidb-deploy/tiflash-9000
cdc_servers:
- host: 192.168.22.142
monitoring_servers:
- host: 192.168.22.143
grafana_servers:
- host: 192.168.22.143
alertmanager_servers:
- host: 192.168.22.143
执行部署命令
tiup cluster deploy tidb-test v4.0.0 ./topology.yaml --user root
#注:tidb-test是给集群取个名称
等待自动布署完成之后执行如下命令查看集群环境:
tiup cluster list

检查部署的 TiDB 集群情况:
tiup cluster display tidb-test #注:tidb-test是集群名称
启动集群:
tiup cluster start tidb-test
验证集群运行状态:
tiup cluster display tidb-test
预期结果输出,注意 Status 状态信息为 Up 说明集群状态正常
执行如下命令登录数据库:
mysql -u root -h 10.0.1.4 -P 4000
关闭集群:
tiup cluster stop tidb-test
销毁集群:
销毁集群操作会关闭服务,清空数据目录和部署目录,并且无法恢复,需要谨慎操作
tiup cluster destroy tidb-test
8.Hadoop集群的布署
部署结构:
| 机器名 |
IP |
部署内容 |
| TIDB01 |
192.168.22.136 |
NameNode,DataNode,NodeManager |
| TIDB02 |
192.168.22.137 |
SecondaryNameNode,DataNode,NodeManager |
| TIDB03 |
192.168.22.143 |
DataNode,NodeManager,ResourceManager 和 MapReduce-JobHistoryServer |
SecondaryNameNode和NameNode可以在一台,推荐在两台,防止意外。(有条件的NameNode应该单独一台,为了性能。那么SecondaryNameNode也应该单独一台)
ResourceManager可以在1号服务器,也可以在其他服务器,比如放在3号服务器,看起来平衡。但是,从1号服务器启动yarn时,在3号服务器启动不了ResourceManager,会报错。可以在3号服务器启动hdfs和yarn。JobHistoryServer需要单独启动,如果配置不指定主机或IP,在哪台服务器都可以启动。如果指定了服务器,就在指定服务器启动。在其他服务器启动会报错。
我把JobHistoryServer和ResourceManager部署在一个节点上。
NodeManager一般和DataNode在一起
安装Hadoop所需的Java SDK
转到java官网下载java安装包
https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html
注意:目前JAVA官网要先注册才能下载


192.168.22.136、37、43三台 IP虚拟主机都需要进行下面的操作:
su - root
scp jdk-8u172-linux-x64.tar.gz [email protected]:136:/opt/jdk/ #注:如果是36和43没/optjdk
scp jdk-8u172-linux-x64.tar.gz [email protected]:/opt/jdk/ 目录,需要用mkdir先创建
使用root切换到36、37、43三台虚拟机上,进行jdk解压,并进行环境变量配置。以36为例:
ssh 192.168.22.136
su – root
cd /opt/jdk
tar –zxvf jdk-8u172-linux-x64.tar.gz
vi /etc/profile
注:下面的配置是把hadoop、java、scala、spark、信息全部配置了
在文件的最后位置增加JDK配置。
export JAVA_HOME=/opt/jdk1.8.0_231
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/opt/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export SCALA_HOME=/opt/scala-2.13.3
export PATH=$SCALA_HOME/bin:$PATH
export SPARK_HOME=/opt/spark-2.4.0
export PATH=$PATH:$SPARK_HOME/sbin
export SPARKS_HOME=/opt/spark-2.4.0
export PATH=$PATH:$SPARKS_HOME/bin
export SCALA_HOME=/opt/scala-2.13.3
export PATH=${SCALA_HOME}/bin:$PATH
export HIVE_HOME=/opt/hive-3.1.2
export PATH=$PATH:$HIVE_HOME/bin
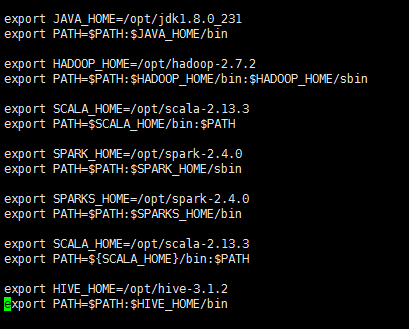
验证JDK安装是否成功:
source /etc/profile
java -version
su - tidb
java -version
其它两台虚拟机一样操作
下载hadoop-2.7.2
打开Hadoop官网地址
https://archive.apache.org/dist/hadoop/common/
选择2.7.2版本

执行如下命令:
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.7.2/hadoop-2.7.2.tar.gz
tar –zxvf hadoop-2.7.2.tar.gz
mv hadoop-2.7.2 /opt/
修改hadoop-env配置文件
执行如下命令:
vim /opt/hadoop-2.7.2/etc/hadoop/hadoop-env.sh #注:如果没有vim命令,可以使用
export HADOOP_PID_DIR=${HADOOP_PID_DIR} yum install vim进行安装
export HADOOP_SECURE_DN_PID_DIR=${HADOOP_PID_DIR}
# A string representing this instance of hadoop. $USER by default.
export HADOOP_IDENT_STRING=$USER
export JAVA_HOME=/opt/jdk1.8.0_231
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
修改core-site.xml配置文件
执行如下命令:
vim /opt/hadoop-2.7.2/etc/hadoop/core-site.xml
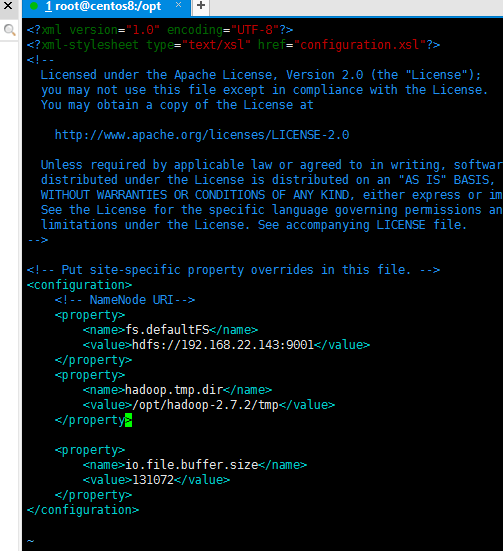
配置HDFS属性hdfs-site.xml
执行如下命令:
vim /opt/hadoop-2.7.2/etc/hadoop/hdfs-site.xml
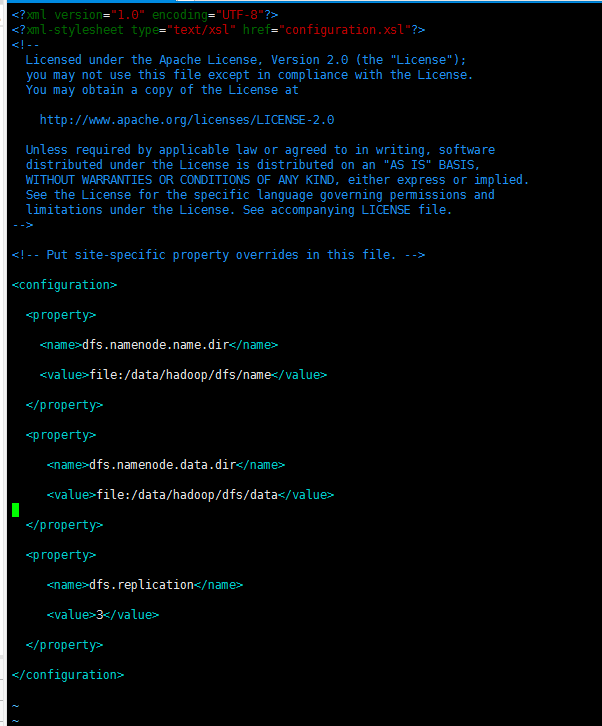
配置yarn属性
执行如下命令:
vim /opt/hadoop-2.7.2/etc/hadoop/yarn-site.xml

配置MapReduce属性
执行如下命令:
vim /opt/hadoop-2.7.2/etc/hadoop/mapred-site.xml
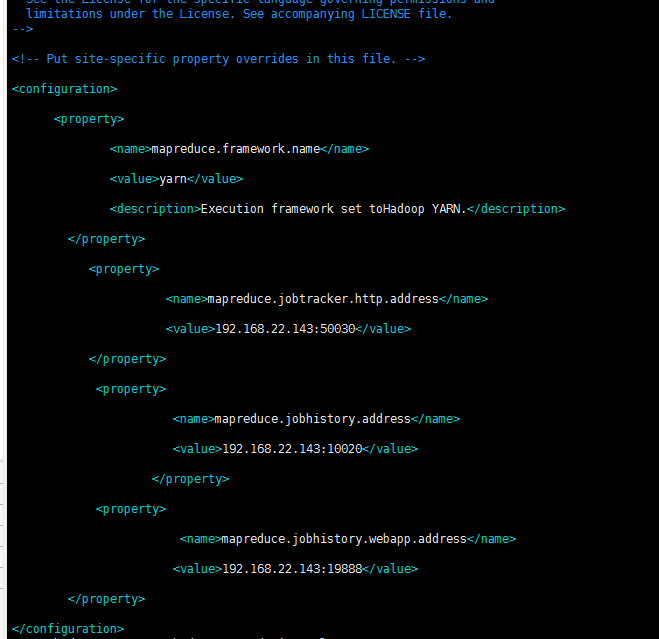
配置workers
在hadoop 2.x中这个文件叫slaves,配置所有datanode的主机地址,只需要把所有的datanode主机名填进去就好了
执行如下命令:
vim /opt/hadoop-2.7.2/etc/hadoop/slaves
192.168.22.136
192.168.22.137
192.168.22.143

将Hadoop目录复制到36和37虚拟机
执行如下命令:
scr -r /opt/hadoop-2.7.2/ [email protected]:/opt/
scr -r /opt/hadoop-2.7.2/ [email protected]:/opt/
格式化hdfs
在namenode所在服务器执行,也就是43虚拟机执行:
hdfs namenode -format

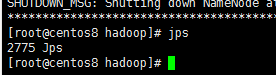
启动dfs
在43虚拟机启动
start-dfs.sh
在136、137、143虚拟机分别执行如下命令,查看服务是否已经启动
jps
启动yarn
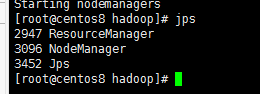
在指定yarn服务器启动yarn,也就是43虚拟机执行如下命令:
start-yarn.sh

在136、137、143虚拟机分别执行如下命令,查看服务是否已经启动
jps
启动MapReduce JobHistoryServer
在指定的服务器启动,也就是43虚拟机执行如下命令:
mapred --daemon start historyserver

在136、137、143虚拟机分别执行如下命令,查看服务是否已经启动:
jps


重新format namenode后,datanode无法正常启动
由于测试需求,重新format namenode后,导致datanode无法正常启动。如果无法启动
服务,先将集群服务所有关闭,然后将hdfs/data/底下的current目录删除,注意:是所有节点服务器都要将current目录删除,再重新启动集群
9.Spark 2.4.0集群的安装布署
我们spark的环境布署分别如下:
192.168.22.143 master节点
192.168.22.136 slaves 节点
192.168.22.137 slaves 节点
进入官网下载Spark
打开https://archive.apache.org/dist/spark/
选择spark-2.4.0版本

然后执行如下命令:
wget https://archive.apache.org/dist/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.7.tgz
tar –zxvf spark-2.4.0-bin-hadoop2.7.tgz
mv spark-2.4.0-bin-hadoop2.7 /opt/spark-2.4.0
修改Spark 配置文件
执行如下命令:
cd /opt/spark-2.4.0
此处需要配置的文件为两个
spark-env.sh和slaves
首先我们把缓存的文件spark-env.sh.template改为spark识别的文件spark-env.sh
cp conf/spark-env.sh.template conf /spark-env.sh
修改spark-env.sh文件
vi conf/spark-env.sh
在最后加入:
export JAVA_HOME=/opt/jdk1.8.0_231
export SCALA_HOME=/opt/scala-2.13.3
export HADOOP_HOME=/opt/hadoop-2.7.2
export HADOOP_CONF_DIR=/opt/hadoop-2.7.2/etc/hadoop
export SPARK_MASTER_IP=192.168.22.143
export SPARK_WORKER_MEMORY=1g
export SPARK_WORKER_CORES=2
export SPARK_WORKER_INSTANCES=1
变量说明:
- JAVA_HOME:Java安装目录
- SCALA_HOME:Scala安装目录
- HADOOP_HOME:hadoop安装目录
- HADOOP_CONF_DIR:hadoop集群的配置文件的目录
- SPARK_MASTER_IP:spark集群的Master节点的ip地址
- SPARK_WORKER_MEMORY:每个worker节点能够最大分配给exectors的内存大小
- SPARK_WORKER_CORES:每个worker节点所占有的CPU核数目
- SPARK_WORKER_INSTANCES:每台机器上开启的worker节点的数目
修改slaves文件
vi conf/slaves
在最后面修成为
192.168.22.143
192.168.22.136
192.168.22.137

将spark目录复制到其它两台虚拟IP服务器上
scp –r /opt/spark-2.40 [email protected]:/opt
scp –r /opt/spark-2.40 [email protected]:/opt
下载Tispark的jar包到Spark目录
打开TIDB官网
https://docs.pingcap.com/zh/tidb/stable/tispark-overview#tispark-%E7%94%A8%E6%88%B7%E6%8C%87%E5%8D%97
点击TiSpark Releases 页面超链接

下载TiSpark 2.3.1版本
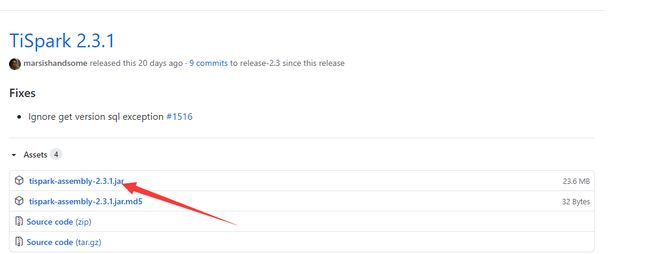
执行如下命令:
wget https://github.com/pingcap/tispark/releases/download/v2.3.1/tispark-assembly-2.3.1.jar
mv tispark-assembly-2.3.1.jar /opt/spark-2.4.0/jars
配置spark-defaults.conf
执行如下命令:
cd /opt/spark-2.4.0/conf/
vim spark-defaults.conf
添加如下两行:
spark.sql.extensions org.apache.spark.sql.TiExtensions
spark.tispark.pd.addresses 192.168.22.137:2379

10. 安装hive-3.1.2
打开 http://archive.apache.org/dist/hive/hive-3.1.2/
下载hive 3.1.2版本

执行如下命令:
wget http://archive.apache.org/dist/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz
tar –zxvf apache-hive-3.1.2-bin.tar.gz
mv apache-hive-3.1.2-bin /opt/hive-3.1.2
修改hive-site.xml
执行如下命令:
cd /opt/hive-3.1.2/conf
vim hive-site.xml
在配置文件中添加以下配置信息:
注意:这里的连接MYSQL密码不能设为空的,空密码会出现连接上的错误

11. 安装scala-2.13.3
打开https://www.scala-lang.org/download/ 官网地址

下载scala-2.13.3.tgz版本

执行如下命令:
wget https://downloads.lightbend.com/scala/2.13.3/scala-2.13.3.tgz
tar –zxvf scala-2.13.3.tgz
mv scala-2.13.3 /opt/
12. 启动Spark集群
执行如下命令:
start-all.sh

start-master.sh #启动spark主节点
start-slaves.sh #启动spark从节点
spark-shell --master spark://192.168.22.143:7077 #连接到TIDB的PD节点
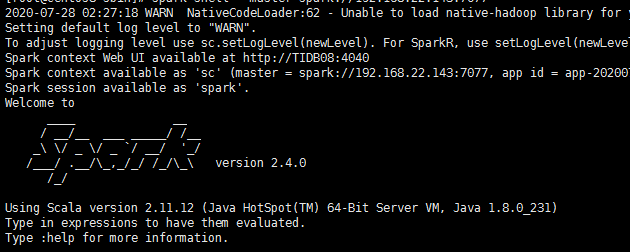
在scala下运行下面一条命令
spark.sql(“show databases”).show
如果能显示如下图的结果表示spark连接TIDB成功
