中文ocr技术调研
文章目录
- Ocr实现技术调研
- 基于传统方法的ocr实现技术
- 基于深度学习的OCR实现技术
- 文字检测
- CTPN
- TextBoxes/TextBoxes++
- EAST
- PixelLink
- FTSN
- RRPN
- PSENET
- WordSup
- 文字识别
- CRNN模型
- RARE模型
- CNN + softmax
- CNN + RNN + attention
- CNN + stacked CNN + CTC
- 端到端的模型识别
- LSTM+CTC 识别方法
- FOTSR Rotation-Sensitive Regression
- STN-OCR模型
- 参考链接:
基于上篇ocr数据集介绍, 本文将简单记录目前常用的ocr技术, 以及每个不同的技术方案解决的应用场景.
Ocr实现技术调研
文字识别可根据待识别的文字特点采用不同的识别方法,一般分为定长文字、不定长文字两大类别。
定长文字(例如验证码),由于字符数量固定,采用的网络结构相对简单,识别也比较容易;
不定长文字(例如印刷文字、广告牌文字等),由于字符数量是不固定的,因此需要采用比较复杂的网络结构和后处理环节,识别也具有一定的难度。
本文主要调研的是不定长文字的检测和识别.
不定长文字在现实中大量存在,例如印刷文字、广告牌文字等,由于字符数量不固定、不可预知,因此,识别的难度也较大,这也是目前研究文字识别的主要方向。在这样的图像中,字符部分可能出现在弯曲阵列、曲面异形、斜率分布、皱纹变形、不完整等各种形式中,并且与标准字符的特征大不相同,因此难以检测和识别图像字符。对于文字识别,实际中一般首先需要通过文字检测定位文字在图像中的区域,然后提取区域的序列特征,在此基础上进行专门的字符识别。但是随着CV发展,也出现很多端到端的End2End OCR。
下面介绍不定长文字识别的常用方法:传统的检测识别方法、两阶段的ocr检测和识别的方法以及一阶段的端到端的ocr实现方式.
基于传统方法的ocr实现技术
传统的OCR技术通常使用opencv算法库,通过图像处理和统计机器学习方法从图像中提取文本信息,包括二值化、噪声滤波、相关域分析、AdaBoost等。传统的OCR技术根据处理方法可分为三个阶段:图像准备、文本识别和后处理。
- 图像准备预处理:
文字区域定位:连通区域分析、MSER
文字矫正:旋转、仿射变换
文字分割:二值化、过滤噪声 - 文字识别:
分类器识别:逻辑回归、SVM、Adaboost - 后处理:规则、语言模型(HMM等)
针对简单场景下的图片,传统OCR已经取得了很好的识别效果。传统方法是针对特定场景的图像进行建模的,一旦跳出当前场景,模型就会失效。随着近些年深度学习技术的迅速发展,基于深度学习的OCR技术也已逐渐成熟,能够灵活应对不同场景。
基于深度学习的OCR实现技术
目前来说基于深度学习的场景文字识别主要包括两种方法, 第一种是分为两阶段的文件检测和文字十倍的方法; 第二种是端到端的模型一次性完成文字检测和识别.
文字检测
目前已经有很多文字检测方法,包括:EAST/CTPN/SegLink/PixelLink/TextBoxes/TextBoxes++/TextSnake/MSR/DMPNet/FTSN/ RRPN/PSENET…等
CTPN
CTPN是ECCV 2016提出的一种文字检测算法,由Faster RCNN改进而来,结合了CNN与LSTM深度网络,其支持任意尺寸的图像输入,并能够直接在卷积层中定位文本行。CTPN由检测小尺度文本框、循环连接文本框、文本行边细化三个部分组成,具体实现流程为:
• 使用VGG16网络提取特征,得到conv5_3的特征图;
• 在所得特征图上使用3*3滑动窗口进行滑动,得到相应的特征向量;
• 将所得特征向量输入BLSTM,学习序列特征,然后连接一个全连接FC层;
最后输出层输出结果, 具体的网络形式如图1所示。

整个过程主要分为六个步骤:
第一步:输入3×600(h)×900(w)的图像,使用VGG16进行特征的提取,得到conv5_3(VGG第5个block的第三个卷积层)的特征作为feature map,大小为512×38×57;
第二步:在这个feature map上做滑窗,窗口大小是3×3,即512×38×57变为4608×38×57(512按3×3卷积展开);
第三步:将每一行的所有窗口对应的特征输入到RNN(BLSTM,双向LSTM)中,每个LSTM层是128个隐层,即57×38×4608变为57×38×128,Reverse-LSTM同样得到的是57×38×128,合并后最终得到结果为 256×38×57;
第四步:将RNN的结果输入到FC层(全连接层),FC层是一个256×512的矩阵参数,得到512×38×57的结果;
第五步:FC层特征输入到三个分类或者回归层中。第一个2k vertical coordinate和第三个k side-refinement是用来回归k个anchor的位置信息(可以简单理解为是要确定字符位置的小的矩形框,上面示意图中的红色小长框,宽度固定,默认为16),第二个2k scores 表示的是k个anchor的类别信息(是字符或不是字符);
第六步:使用文本构造的算法,将得到的细长的矩形框,将其合并成文本的序列框。其中文本构造算法的主要的思路为:每两个相近的候选区组成一个pair,合并不同的pair直到无法再合并为止。
CTPN模型最大的亮点是引入RNN来进行检测。先用CNN得到深度特征,然后用固定宽度的anchor(固定宽度的,细长的矩形框)来检测文本区域,将同一行anchor对应的特征串成序列,然后输入到RNN当中,再用全连接层来做分类或回归,最后将小的候选框进行合并,从而得到了文本所在的完整区域。这种把RNN和CNN无缝结合的方法有效地提高了检测精度。CTPN是基于Anchor的算法,在检测横向分布的文字时能得到较好的效果。此外,BLSTM的加入也进一步提高了其检测能力
网络具体架构参考链接
TextBoxes/TextBoxes++
TextBoxes和TextBoxes++模型都来自华中科技大学的白翔老师团队,其中TextBoxes是改进版的SSD,而TextBoxes++则是在前者的基础上继续扩展, 网络结构如图2所示。

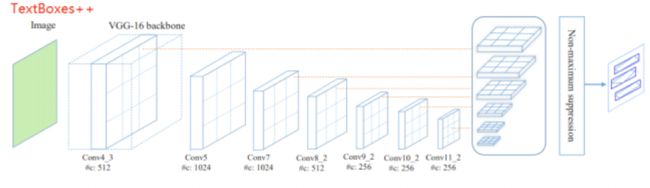
TextBoxes++保留了TextBoxes的基本框架,只是对卷积层的组成进行了略微调整,同时调整了default box的纵横比和输出阶段的卷积核大小,使得模型能够检测任意方向的文字。将标注数据改为了旋转矩形框和不规则四边形的格式;对候选框的长宽比例、特征图层卷积核的形状都作了相应调整, 具体框架如图3所示。
EAST
EAST算法首先使用全卷积网络(FCN)生成多尺度融合的特征图,然后在此基础上直接进行像素级的文本块预测。该模型中,支持旋转矩形框、任意四边形两种文本区域标注形式。对应于四边形标注,模型执行时会对特征图中每个像素预测其到四个顶点的坐标差值。对应于旋转矩形框标注,模型执行时会对特征图中每个像素预测其到矩形框四边的距离、以及矩形框的方向角, 具体的网络结构如图4所示。

PixelLink
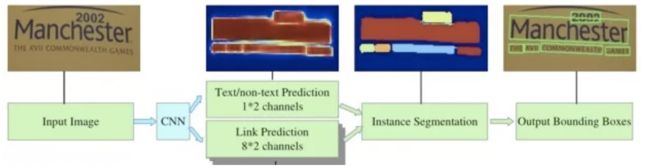
自然场景图像中一组文字块经常紧挨在一起,通过语义分割方法很难将它们识别开来,所以PixelLink模型尝试用实例分割方法解决这个问题。
该模型的特征提取部分,为VGG16基础上构建的FCN网络。模型执行流程如下图所示。首先,借助于CNN 模块执行两个像素级预测:一个文本二分类预测,一个链接二分类预测。接着,用正链接去连接邻居正文本像素,得到文字块实例分割结果。然后,由分割结果直接就获得文字块边框, 而且允许生成倾斜边框, 检测效果如图7所示。
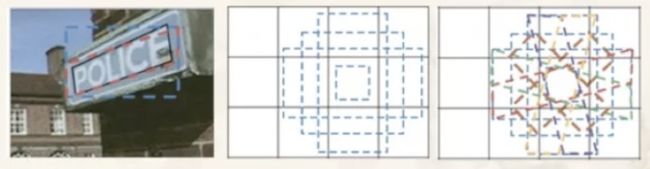
如下图8所示,它使用滑动窗口在特征图上获取文本区域候选框,候选框既有正方形的、也有倾斜四边形的。接着,使用基于像素点采样的Monte-Carlo方法,来快速计算四边形候选框与标注框间的面积重合度。然后,计算四个顶点坐标到四边形中心点的距离,将它们与标注值相比计算出目标loss。文章中推荐用Ln loss来取代L1、L2 loss,从而对大小文本框都有较快的训练回归(regress)速度。
FTSN
Dai ,Huang 等人在2018年提出了FTSN(Fused Text Segmentation Networks)模型,使用分割网络支持倾斜文本检测
它使用Resnet-101做基础网络,使用了多尺度融合的特征图。标注数据包括文本实例的像素掩码和边框,使用像素预测与边框检测多目标联合训练。
基于文本实例间像素级重合度的Mask-NMS, 替代了传统基于水平边框间重合度的NMS算法。下图左边子图是传统NMS算法执行结果,中间白色边框被错误地抑制掉了。下图右边子图是Mask-NMS算法执行结果, 三个边框都被成功保留下来, 如图9所示。
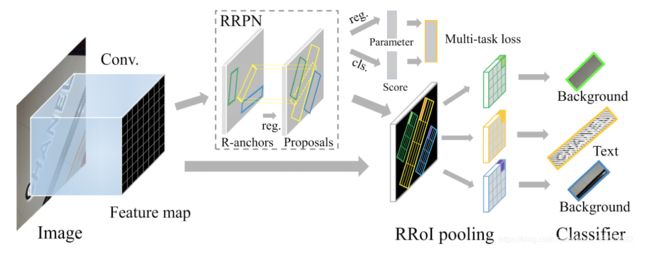
RRPN
基于旋转区域候选网络(RRPN, Rotation Region Proposal Networks)的方案,将旋转因素并入经典区域候选网络(如Faster RCNN)。这种方案中,一个文本区域的ground truth被表示为具有5元组(x,y,h,w,θ)的旋转边框, 坐标(x,y)表示边框的几何中心, 高度h设定为边框的短边,宽度w为长边,方向是长边的方向。训练时,首先生成含有文本方向角的倾斜候选框,然后在边框回归过程中学习文本方向角,具体的网络框架如图10所示。
PSENET
基于分割的办法,能检测任意形状的文字
在此基础上提出了一种渐进扩张算法,能有效分割位置很近的文本
每个文本实例(目标区域)有多个预测的分割实例(如何整合得到输出的?)
为了得到最后的文本区域采用了Breadth-First-Search (BFS)。从最小的预测分割实例开始扩张的。因为最小的分割实例map中文字之间的距离是比较大的,容易分割, 具体分割如图11所示。

具体介绍可以参考博客
WordSup
如下图13-1所示,在数学公式图文识别、不规则形变文本行识别等应用中,字符级检测模型是一个关键基础模块。由于字符级自然场景图文标注成本很高、相关公开数据集稀少,导致现在多数图文检测模型只能在文本行、单词级标注数据上做训练。WordSup提出了一种弱监督的训练框架, 可以文本行、单词级标注数据集上训练出字符级检测模型。
如下图13-2所示,WordSup弱监督训练框架中,两个训练步骤被交替执行:给定当前字符检测模型,并结合单词级标注数据,计算出字符中心点掩码图; 给定字符中心点掩码图,有监督地训练字符级检测模型.
如下图14所示,训练好字符检测器后,可以在数据流水线中加入合适的文本结构分析模块,以输出符合应用场景格式要求的文本内容。该文作者例举了多种文本结构分析模块的实现方法。

文字识别
图文识别任务中充当特征提取模块的基础网络,可以来源于通用场景的图像分类模型。例如,VGGNet,ResNet、InceptionNet、DenseNet、Inside-Outside Net、Se-Net等。
图文识别任务中的基础网络,也可以来源于特定场景的专用网络模型。例如,擅长提取图像细节特征的FCN网络,擅长做图形矫正的STN网络。
文本识别模型的目标是从已分割出的文字区域中识别出文本内容。目前常用的文本识别模型有以下几种。
CRNN模型
CRNN(Convolutional Recurrent Neural Network)是目前较为流行的图文识别模型,可识别较长的文本序列。是华中科技大学在发表的论文《An End-to-End Trainable Neural Network for Image-based Sequence Recognition and ItsApplication to Scene Text Recognition》提出的一个识别文本的方法,该模型主要用于解决基于图像的序列识别问题,特别是场景文字识别问题, 具体网络框架如图15所示。
CRNN的主要特点是:
(1)可以进行端到端的训练;
(2)不需要对样本数据进行字符分割,可识别任意长度的文本序列
(3)模型速度快、性能好,并且模型很小(参数少)
它包含CNN特征提取层和BLSTM序列特征提取层,能够进行端到端的联合训练。 它利用BLSTM和CTC部件学习字符图像中的上下文关系, 从而有效提升文本识别准确率,使得模型更加鲁棒。预测过程中,前端使用标准的CNN网络提取文本图像的特征,利用BLSTM将特征向量进行融合以提取字符序列的上下文特征,然后得到每列特征的概率分布,最后通过转录层(CTC rule)进行预测得到文本序列。
CRNN模型主要由以下三部分组成:
卷积层:从输入图像中提取出特征序列;
循环层:预测从卷积层获取的特征序列的标签分布;
转录层:把从循环层获取的标签分布通过去重、整合等操作转换成最终的识别结果。
卷积层
① 预处理
CRNN对输入图像先做了缩放处理,把所有输入图像缩放到相同高度,默认是32,宽度可任意长。
② 卷积运算
由标准的CNN模型中的卷积层和最大池化层组成,结构类似于VGG,如下图16所示:
从上图可以看出,卷积层是由一系列的卷积、最大池化、批量归一化等操作组成。
③ 提取序列特征
提取的特征序列中的向量是在特征图上从左到右按照顺序生成的,用于作为循环层的输入,每个特征向量表示了图像上一定宽度上的特征,默认的宽度是1,也就是单个像素。由于CRNN已将输入图像缩放到同样高度了,因此只需按照一定的宽度提取特征即可。如下图17所示
循环层
循环层由一个双向LSTM循环神经网络构成,预测特征序列中的每一个特征向量的标签分布。
由于LSTM需要有个时间维度,在本模型中把序列的 width 当作LSTM 的时间 time steps。
其中,“Map-to-Sequence”自定义网络层主要是做循环层误差反馈,与特征序列的转换,作为卷积层和循环层之间连接的桥梁,从而将误差从循环层反馈到卷积层。
转录层
转录层是将LSTM网络预测的特征序列的结果进行整合,转换为最终输出的结果。
在CRNN模型中双向LSTM网络层的最后连接上一个CTC模型,从而做到了端对端的识别。所谓CTC模型(Connectionist Temporal Classification,联接时间分类),主要用于解决输入数据与给定标签的对齐问题,可用于执行端到端的训练,输出不定长的序列结果。
由于输入的自然场景的文字图像,由于字符间隔、图像变形等问题,导致同个文字有不同的表现形式,但实际上都是同一个词,如下图18:

而引入CTC就是主要解决这个问题,通过CTC模型训练后,对结果中去掉间隔字符、去掉重复字符(如果同个字符连续出现,则表示只有1个字符,如果中间有间隔字符,则表示该字符出现多次)
RARE模型
RARE(Robust text recognizer with Automatic Rectification)模型在识别变形的图像文本时效果很好。如下图19所示,模型预测过程中,输入图像首先要被送到一个空间变换网络中做处理,矫正过的图像然后被送入序列识别网络中得到文本预测结果。
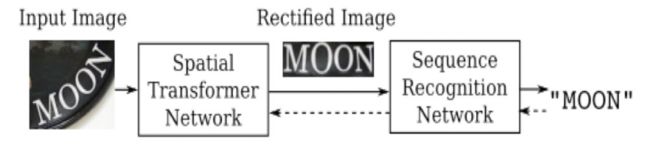
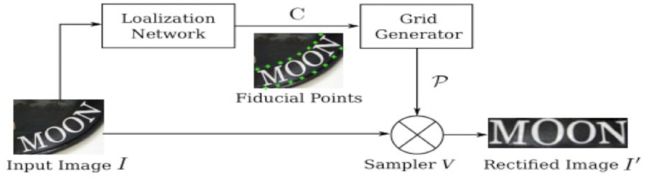
如下图20所示,空间变换网络内部包含定位网络、网格生成器、采样器三个部件。经过训练后,它可以根据输入图像的特征图动态地产生空间变换网格,然后采样器根据变换网格核函数从原始图像中采样获得一个矩形的文本图像。RARE中支持一种称为TPS(thin-plate splines)的空间变换,从而能够比较准确地识别透视变换过的文本、以及弯曲的文本.
CNN + softmax
此方法主要用于街牌号识别,对每个字符识别的架构为:先使用卷积网络提取特征,然后使用N+1个softmax分类器对每个字符进行分类。具体流程如下图21所示:
使用此方法可以处理不定长的简单文字序列(如字符和字母),但是对较长的字符序列识别效果不佳。
CNN + RNN + attention
本方法是基于视觉注意力的文字识别算法, 网络框架如下图22所示。主要分为以下三步:
• 模型首先在输入图片上运行滑动CNN以提取特征;
• 将所得特征序列输入到推叠在CNN顶部的LSTM进行特征序列的编码;
• 使用注意力模型进行解码,并输出标签序列。
本方法采用的attention模型允许解码器在每一步的解码过程中,将编码器的隐藏状态通过加权平均,计算可变的上下文向量,因此可以时刻读取最相关的信息,而不必完全依赖于上一时刻的隐藏状态。
CNN + stacked CNN + CTC
上面提到的CNN + RNN + attention方法不可避免的使用到RNN架构,RNN可以有效的学习上下文信息并捕获长期依赖关系,但其庞大的递归网络计算量和梯度消失/爆炸的问题导致RNN很难训练。基于此,有研究人员提出使用CNN与CTC结合的卷积网络生成标签序列,没有任何重复连接, 网络框架如23所示。
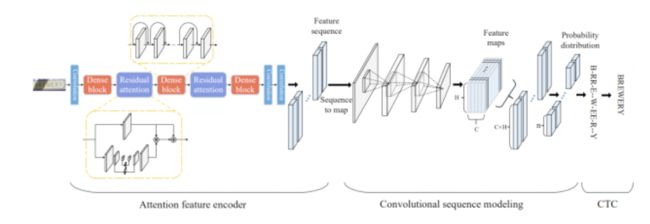
这种方法的整个网络架构如下图所示,分为三个部分:
• 注意特征编码器:提取图片中文字区域的特征向量,并生成特征序列;
• 卷积序列建模:将特征序列转换为二维特征图输入CNN,获取序列中的上下文关系;
• CTC:获得最后的标签序列。
该方法基于CNN算法,相比RNN节省了内存空间,且通过卷积的并行运算提高了运算速度。
端到端的模型识别
LSTM+CTC 识别方法
为了实现对不定长文字的识别,就需要有一种能力更强的模型,该模型具有一定的记忆能力,能够按时序依次处理任意长度的信息,这种模型就是“循环神经网络”(Recurrent Neural Networks,简称RNN)。
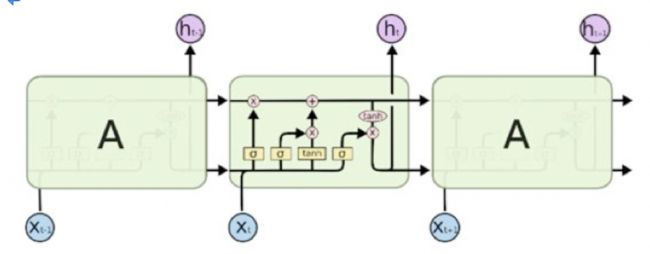
LSTM(Long Short Term Memory,长短期记忆网络)是一种特殊结构的RNN(循环神经网络),用于解决RNN的长期依赖问题,也即随着输入RNN网络的信息的时间间隔不断增大,普通RNN就会出现“梯度消失”或“梯度爆炸”的现象,这就是RNN的长期依赖问题,而引入LSTM即可以解决这个问题。LSTM单元由输入门(Input Gate)、遗忘门(Forget Gate)和输出门(Output Gate)组成,具体的技术原理的工作过程详见之前的文章(文章:白话循环神经网络(RNN)),LSTM的结构如下图24所示。
CTC(Connectionist Temporal Classifier,联接时间分类器),主要用于解决输入特征与输出标签的对齐问题。例如下图,由于文字的不同间隔或变形等问题,导致同个文字有不同的表现形式,但实际上都是同一个文字。在识别时会将输入图像分块后再去识别,得出每块属于某个字符的概率(无法识别的标记为特殊字符”-”),如上述图18所示.
由于字符变形等原因,导致对输入图像分块识别时,相邻块可能会识别为同个结果,字符重复出现。因此,通过CTC来解决对齐问题,模型训练后,对结果中去掉间隔字符、去掉重复字符(如果同个字符连续出现,则表示只有1个字符,如果中间有间隔字符,则表示该字符出现多次),如下图25所示

具体的代码实现可以参照
FOTSR Rotation-Sensitive Regression
大多数文本检测与识别是分开的任务,但是FOTS可以做到端到端,如下图所示,FOTS相比其他检测和识别分开的任务,速度提高一倍以上。检测和识别任务共享卷积特征层,既节省了计算时间,也比两阶段训练方式学习到更多图像特征。引入了旋转感兴趣区域(RoIRotate), 可以从卷积特征图中产生出定向的文本区域,从而支持倾斜文本的识别.
作者提出了RoIRotate,可以在检测和识别之间共享卷积特征,使得FOTS相比基线模型基本上没有任何计算开销,且性能上也非常棒。在ICDAR2015的文本检测任务中,FOTS保持了之前最先进网络22.6fps的检测速度,score却提升5%以上。FOTS的网络结构包括四个部分:共享卷积模块、文本检测模块、RoIRotate和文本识别模块, 识别效果如下图26所示。

具体网络的内容可以参考链接
STN-OCR模型
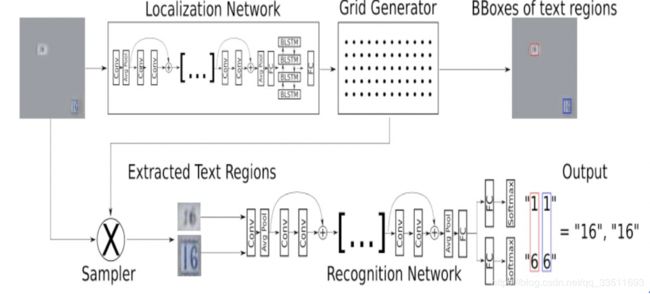
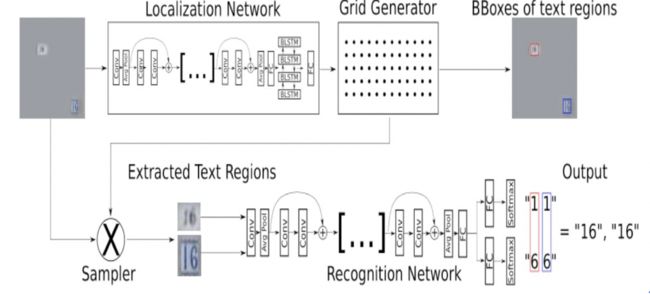
Bartz, Yang等人在2017年提出了STN-OCR模型[11],STN-OCR是集成了了图文检测和识别功能的端到端可学习模型。在它的检测部分嵌入了一个空间变换网络(STN)来对原始输入图像进行仿射(affine)变换。利用这个空间变换网络,可以对检测到的多个文本块分别执行旋转、缩放和倾斜等图形矫正动作,从而在后续文本识别阶段得到更好的识别精度。在训练上STN-OCR属于半监督学习方法,只需要提供文本内容标注,而不要求文本定位信息。作者也提到,如果从头开始训练则网络收敛速度较慢,因此建议渐进地增加训练难度。STN-OCR已经开放了工程源代码和预训练模型, 具体框架如下27所示。
参考链接:
https://msd.misuland.com/pd/3255818100674659652(200行代码实现滑动验证码)
https://blog.csdn.net/imPlok/article/details/95041472
https://www.jianshu.com/p/7a2b227896a8
https://mp.weixin.qq.com/s/jHOkFQiGjcAeUdEPdwiv6g
https://mp.weixin.qq.com/s/vXnD4FUuZHtfxcustUspqA
https://mp.weixin.qq.com/s/8xiE9pQQNuiPSjgZINP9og
https://mp.weixin.qq.com/s/37DLcW2JfJe3VBFDlSSVwg
https://mp.weixin.qq.com/s/P08W5zecG3oghLT6Ip9Xfg
https://mp.weixin.qq.com/s/Hq75doBEvy9kjHR47r7I8w