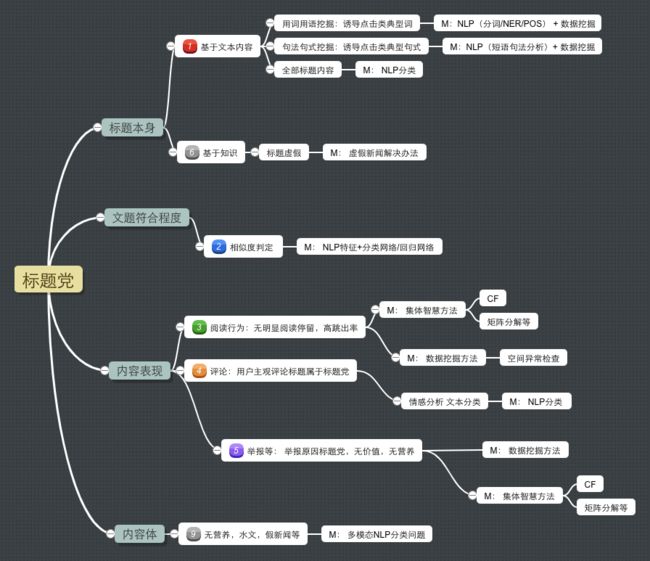
【内容算法】内容质量之标题党
作者丨孙子荀
单位丨腾讯科技专家研究员
业务定义
首先在我们讨论标题党的时候,我们需要定义清楚,我们说的是1 仅标题带来的主观感受,还是 2 通过标题点击进入文章后的阅读感受。
如果是1 :标题的感受。来源于几个indicate 。
a .表征的有: 用词用语 ,句法句样式; (可以看文末【标题党特征举例】)
b .知识层面的有: 标题是否让人主观先验到,大概率是虚假新闻。
如果是2:通过标题后阅读文章的感受。有几个indicate。
a.表征的有:文章直观感受没有信息量如,纯配图,或者纯旧闻,提现在跳出率高,阅读时常低。
b.知识层面的有: 文章是否无营养,文章内容纯在虚假。
我们根据上面的区分,根据使用特征和处理手段,把标题党分成几种问题domain, 希望在解决标题党泛问题之前,先明确定义。
1型 标题型标题党 (基于标题本身)
1.1 使用了诱导性:句法句式
1.2 使用了诱导性:用词用语
1.3 语义本身具有诱导性
通用子问题: 分类模型(SVM,BERT)。 句法分析,
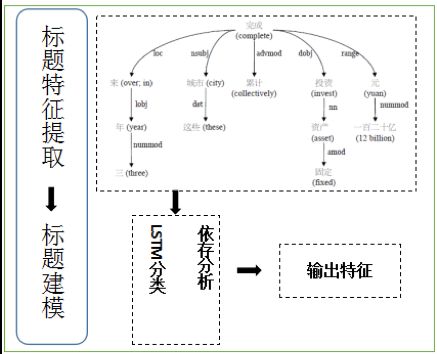
2型 文不对题型标题党 (基于文本和内容匹配情况)
通用子问题:NLP问题中的相似度量办法都可以尝试。
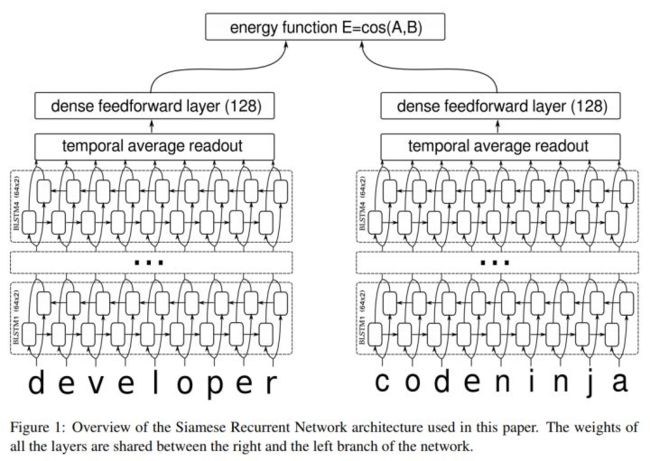
3型 无价值判定标题党 (基于内容表现模型)
如:诱导点击,跳出率高。 用户进入后大部分第一时间跳出。 这里
通用子问题:数据挖掘问题,如空间异常检查。
4型 评论判定标题党 (基于用户文本知识模型)
4.1 基于用户评论分析
通用子问题: NLP情感分析,规则等。
5型 行为判定标题党 (基于用户行为模型)
4.2 基于负反馈行为(举报原因)
通用子问题:1.类似III型,常规数据挖掘问题;
2.建模用户行为,其他集体智慧编程方法(CF,矩阵分解等)。
6型 虚假型标题党
如:标题本身描述是虚假的。可能是主观虚假,也可能是客观虚假。和正文是否虚假无关。
通用子问题:可以参考当前已有的假新闻检测方法: https://www.jiqizhixin.com/articles/2019-02-19-22
9型 整体标题党
严格来说可能不一定是一个标题党问题,只是具有标题党的内容,本身也伴随着这些内容问题,比如水文,无营养判定等内容质量问题等。
备注:
-
以上五个类型,不具备排他性。可以同时符合多个。
-
9型标题党, 可以通过多模态的分类问题直接建模,类似无营养,水文,假新闻等
举例
-
断章取义 (I, II,IV)
-
标题:刘德华演唱会现场耍大牌!怒骂保安场面失控!
-
内容:安保动作过大,刘德华保护歌迷安全
-
-
故作玄虚 (I )
-
标题:插了一夜没拔,结果差点弄出人命!
-
内容:手机充电器夜里爆炸
-
-
-
正题歪做(IV)
-
标题:禽兽!一众男明星艺人竟然对柳岩做这样的事情!
-
内容:包贝尔婚礼,柳岩险被群人推到泳池
-
-
-
侮辱调侃 (I,IV)
-
标题:九寨沟,不震你震谁?
-
内容:九寨沟景区收入过高被仇富
-
-
-
数据无从考证 (IIV )
-
标题:14亿人都不知道的真相,历史的血泪!
-
-
-
虚构名人言论经历 (IIV )
-
标题:李彦宏给年轻人的20句忠告!
-
-
-
道德绑架 (I,III)
-
标题:百度看了会沉默,阿里看了会流泪,不转不是腾讯人!
-
-
-
故弄玄虚(I )
-
标题:4岁孩子得胃癌!看他妈给他吃些什么!!
-
内容:4岁儿童被诊断胃癌,家长称其爱吃烧烤
-
相关论文

-
Clickbait Detection[1]
作者采用了一个通用机器学习问题解决的办法,选择了大量的文本特征来做分类问题。
数据集:
贡献了一套含有2992条Twiiter数据集,包含767条标题党样本。
效果:
LR准确率0.7 ,召回率0.7 ,NB准确率0.71 召回率0.66。二者结合RF准确率0.7 召回率0.73。
方法:
特征模板+分类器
|
存在的问题:
没有考虑标题(此场景下即摘要信息)与正文(此场景下即相关网页)的相关性,基于规则的方法不具有可扩展性,出现新的标题党模式时需要持续优化
From Clickbait to Fake News Detection: An Approach based on Detecting the Stance of Headlines to Articles
论文中说是应用于虚假新闻,但看内容主要还是针对标题党,(类似6型,把标题党和假新闻结合其他看,但事实上该方法并不局限新闻的真假性)
数据集:
First Fake News Challenge (FNC1) on stance detection(2016)。
baseline:79.53%。标注了四个类别:unrelated/【agree/disagree/discuss】-> 属于related大类
方法:
1 首先判断是否related
-
sc = sum(TF*IDF) 对于标题H中的每个词组 / 标题H和正文A中所有的词组数
-
其中TF = (H中第i个词组在H中的词频 + H中第i个词组在A中的词频) * 标题H中所有的词组数
-
词组的长度:1-gram至6-gram,过滤停用词和标点
-
if sc > threshold, then take it as related
2 进一步判断agree/disagree/discuss
-
LR三分类(只用标题)
-
若top1分数与top2分数超过置信阈值,则分为top1
-
否则用三个二分类的分类器(标题+正文)综合打分
效果:
-
二分类93.39%,三分类88.36%,综合89.59%
Machine Learning Based Detection of Clickbait Posts in Social Media
数据:
clickbait challenge 2017 (clickbait-challenge.com),21000多篇文章,每个样本至少有5人标注,保证客观性
效果:
-
RF Regression:Accuracy=0.82, F1-score=0.56
-
RF Classifier:Accuracy=0.78, F1-score=0.61
方法:
总结了已有的特征(大多在上上篇论文中已使用)
|
Clickbaits Revisited: Deep Learning on Title + Content Features to Tackle Clickbaits
-
Github源码:https://github.com/abhishekkrthakur/clickbaits_revisited
数据:
各个新闻网站的文章爬取,约50000个样本,其中标题党样本数约25000
方法:
-
数据清洗和特征抽取(启示:对标题党和非标题党样本,部分特征可视化来呈现对比)
-
Size of the HTML (in bytes)
-
Length of HTML
-
Total number of links
-
Total number of buttons
-
Total number of inputs
-
Total number of unordered lists
-
Total number of ordered lists
-
Total number of lists (ordered + unordered)
-
Total Number of H1 tags
-
Total Number of H2 tags
-
Full length of all text in all H1 tags that were found
-
Full length of all text in all H2 tags that were found
-
Total number of images
-
Total number of html tags
-
Number of unique html tags
-
-
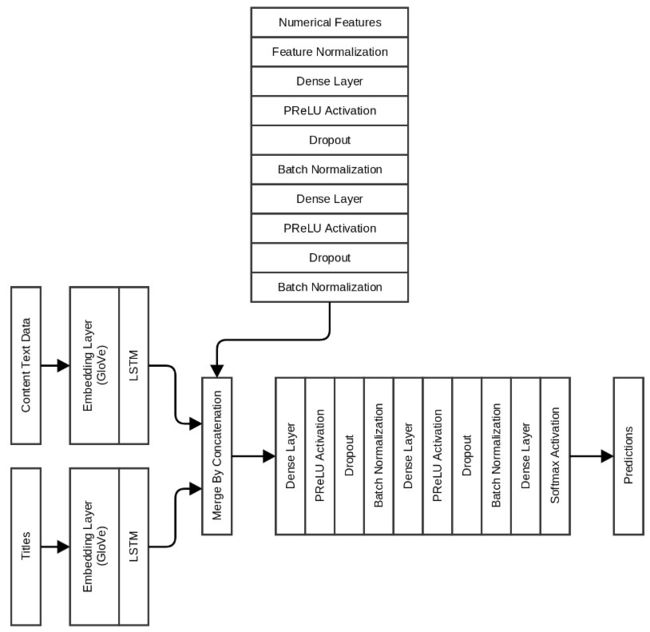
深度学习模型
-
快速模型:只是用标题文本,Embedding+LSTM+3层Dense(包括PReLU、Dropout和BN)+Softmax,最后进行二分类预测
-
精确模型:标题文本和正文文本分别使用Embedding+LSTM,然后合并feature至下一层
-
优化1:使用GloVe初始化embedding层(效果不明显)
-
优化2:加入上述特征,进行Normalization+2层Dense(包括PReLU、Dropout和BN)
-
效果:
验证集Accuracy=99.6%,测试集Accuracy=99.2%
-
Clickbait Detection using Deep Learning
数据:
从Reddit、Facebook和Twitter上爬取的2300多个样本,包含800多个标题党样本
方法:
-
CNN
-
Embedding(同样使用GloVe初始化,比直接用原始文本训练的w2v效果稍好一些)
-
分别使用大小为3-5的filter生成features并合并
-
Max-over-time pooling + Reshape + Softmax
-
结果:
准确率85%,召回率88%
-
Learning to Identify Ambiguous and Misleading News Headlines
-
将模糊类和误导类分开识别
-
数据:
-
爬取了40000篇文章,包含留个不同领域(国内/国际/社会/娱乐/体育/科技)
-
数据来源:新浪、网易、腾讯和头条
-
标注:随机选择了2900多篇文章,6人标注,每篇文章至少由3人标注,需要具体标注是否为模糊类和误导类,对于误导类文章,凡是有争议的全部弃用。最终得到645篇模糊性文章,2279篇非模糊性文章;843篇误导性文章,1765篇非误导性文章。(感慨一下比例之高)
-
未标注数据用于协同训练(co-training)
方法:
-
对于模糊类的标题党,之前一些文章中选取的标题特征主要基于词本身,缺乏句子结构和序列信息,因此作者使用了另一种特征:分类序列规则(class sequential rules, CSR),将基本特征与CSR特征一起用于训练SVM。
-
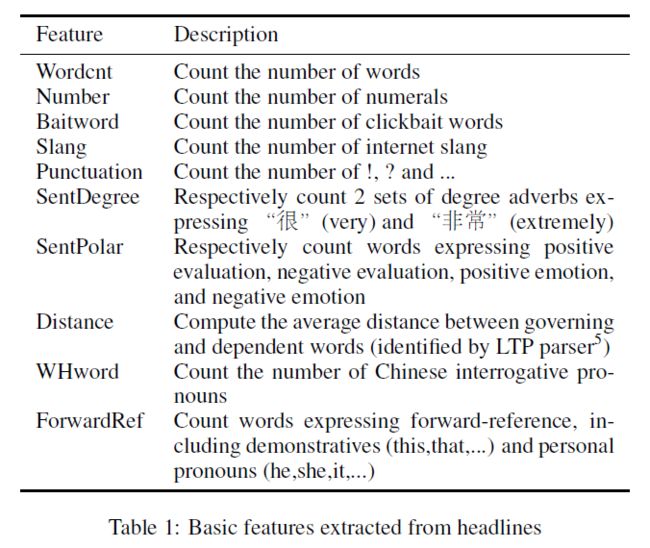
文本基本特征提取所涉及到的一些资源:
-
英文的标题党词表(翻译并人工纠正):http://downworthy.snipe.net/
-
中英文情感分析词汇:http://www.keenage.com/html/e_index.html
-
搜狗输入法词库(匹配网络用语):http://pinyin.sogou.com/dict/
-
-
-
CSR特征的挖掘比较复杂,详细需要看论文
-
每个标题看做一个序列,序列中的每个词对应一个label,共12个不同的label(除了Table 1中提到的前接词、WH词外,还包括2类时序副词,分别表示过去和现在,以及9类不同的连词)【备注:时序副词常常用于对比,而连词能够通过引出假设、对比等意图来增加内容的吸引力。】
-
通过设置阈值来提取出标题中常见的模式,每种模式作为一个特征。
-
比如例句:“她是曾经的世界冠军,但现在为工作发愁。”对应的模式为
-
-
对于误导类的标题党,决定其是否具有误导性的因素当然是标题对应的正文到底在说什么,因此单独从标题和正文中提取出的特征并不能说明问题。因此此类问题的特征构造尤其需要提取标题和正文的关联性。
-
标题单独的特征:Table 1中特征,但不需要前接词
-
正文单独的特征:
-
信息类:网络用语词频,标题党特色词词频,以及正文的长度等
-
情感类:正面/负面评价、正面/负面情绪以及中性词的词频
-
-
关联性特征:
-
标题与正文的信息类特征的绝对差值
-
标题与正文的情感类特征的绝对差值
-
相似度
-
抽取出在标题中但未出现在正文中的所有实体词
-
对于标题中除上述实体词外的每个词,从正文中找出与之最相近的词,最后取平均
-
使用TFIDF计算标题与正文摘要的整体相似度
-
-
识别文字蕴含(Recognizing Textual Entailment,RTE)
-
定义:如果H的含义能够从T中通过常识推断得到,那么T就蕴含了H
-
通过依存树可以得到句子的结构信息,通过匹配governing and dependent words(决定了句子的主要结构)来计算RTE分数
-
主要在正文中搜索与标题中对应的从属子句
-
对同义词、反义词、上位词、下位词赋予不同的权重
-
-
-
Co-training:一种半监督的训练方法
-

结果

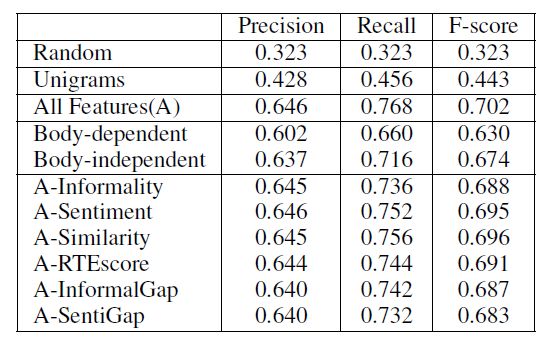
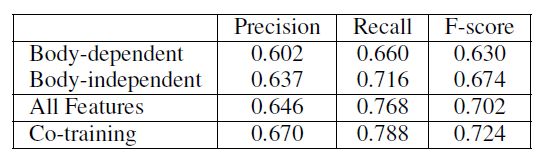
-
一些有趣的数据:娱乐和社会新闻是重灾区
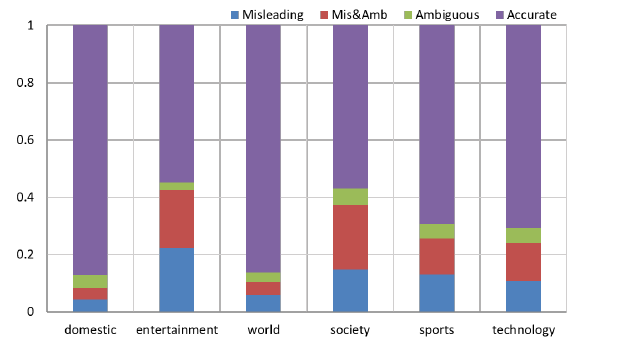
-
基于主题句相似度的标题党新闻鉴别技术研究
解决的case:题文不符
数据:
100篇国内新闻网站文章
结果:
准确率72%
方法
-
新闻正文进行句子分割,统计正文句子
-
如果正文句子数大于10,则按本文中提出的方法进行主题句抽取,得到新闻主题句集合TS,否则直接将正文内容作为TS
-
新闻标题与新闻正文主题句集合TS进行句子相似度计算,得到相似度值P
-
将得到的P值与阈值T比较,即可判断一篇新闻是否为标题党新闻
-
基于监督学习的新闻“标题党”识别技术研究
-
引用标题党的三个特征
-
标题内容相关度不高
-
断章取义,扭曲原文的上下文语境
-
标题使用夸张极端的词汇,设置悬念,故弄玄虚
-
-
解决的case:
-
以上三类标题党
-
-
数据:爬取800多篇今日头条文章,包含10个频道
-
结果:J48准确率73.6%,召回率71.3%
-
方法:特征模板+分类器
-
标题党文章的高频词统计
-
使用Gensim建立bow TFIDF LSI模型对文本相似度计算
-
构建特征模板
-
评论数,标签数
-
标题长度,正文长度
-
是否原创
-
标题是否含有数字、特殊符号
-
标题是否含有“标题党”高频词汇
-
标题与正文的相似度
-
-
训练分类器:J48,随机森林
-
-
业内方案
FB
-
定义:
-
蓄意隐藏重要信息
-
“她掀开沙发垫子看见这个……令人发指!”
-
“临睡前把大蒜放进鞋子里,结果令人难以置信!”
-
“狗对着邮递员狂吠,他的反应是无价的”
-
“当你看过这些图片,就再也无法直视芭比娃娃了!”
-
-
夸大内容误导受众
-
“一名学生录音承认家庭犯罪,但他们必须要生存……”
-
“我们不敢相信,并两次确认了事实。现在让我们谈谈如何让它震惊全球。”
-
“他因为一个可怕的原由改名换姓,现在终于道出了原委。”
-
-
-
方法:
-
脸书表示他们开发的这套算法系统与垃圾邮件过滤器的运行方式有几分相似,都是通过“标题党”中常见的短语去识别此类文章,从而下调该文章在消息流中的排序。而脸书的这套算法不但可以识别发布这类内容的原始页面,还具有学习能力。一旦该页面停止发布这类“标题党”文章,其他文章的发布将不会受到影响。目前这一系统已将数万个标题归类为“标题党”。不过目前该系统并未实现全自动化,仍需要人工团队进行分类工作。
-
Facebook在面对“标题党”和假新闻时,依赖于用户举报。
-
如果用户在页面停留时间长,说明内容有价值,而打开链接后又马上返回Facebook,说明是标题党。
-
如果点击量很高,而分享数很少,就说明内容缺乏价值。
-
头条
-
方法:
-
很多“标题党”常用的内容元素其实都是可以在文本层面进行总结的,交由机器处理的效率会更高。“正则表达式”就是定义一系列与“标题党”相关的词汇来维护一些规则,进而使用这些规则来检测每一篇文章。今日头条实际有数百人的审核队伍,建立起了一套比较完善的规则,并利用机器算法对每天几十万篇的新进文章进行筛选。由此,得到这些文章评级的高低,并对文章的标题和内容进行判断。
-
让用户对文章进行评论以及点击“不喜欢”按钮来表达个体意见,通过一些按钮来收集用户行为,再对文章的标题和内容质量进行判断,从而把内容质量不高或是存在“标题党”行为的推送限制在很小的范围内。
-
过滤停留时间短的点击
-
拆分标题里面单个词,并形成权重分数,同时也会拆分对词组,并自动打分。分数超过阈值就被认为是“标题党”。
-
在号主发文时提供标题检测和警示功能。
-