hadoop之Wordcount实验解析
-
一、概述
单词计数是最简单也最能体现MapReduce思想的程序之一,单词计数的主要功能在于:统计一系列文本文件总每个但系出现的次数。本次实验预通过分析WordCount源码来进一步明确MapReduce程序的基本结构和运行机制。
二、环境准备
系统环境:Ubuntu 16.0
软件环境:Java 1.8.0
Hadoop 3.0
三、map和reduce工作原理简介:
从HDFS内部看,一个文件储存到HDFS后,被分成一个或多个数据块(block),这些数据块存储在Datenode上。数据块与MapReduce的处理单位split相对应:

1.map任务处理
(a)读取文件内容,解析成key、value对。对输入文件的每一行,解析成key、value对。每一个键值对调用一个map函数。
(b)在map函数中可以编写自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
(c)对输出的key、value进行分区。
(d)对不同分区的数据,按照key进行排序、分组。相同key的value放到一个集合中。
2.reduce任务处理
(a)对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点。
(b)对多个map任务的输出进行合并、排序。写reduce函数自己的逻辑,对输入的key、reduce处理,转换成新的key、value输出。
(c)把reduce的输出保存到文件中。

对于最能体现MapReduce思想的实验Wordcount而言,其主要完成了map任务的“分块”任务,将整个文件分成若干个“简单的任务”进行执行。

四、实例开发
在Linux系统桌面上新建一个文件夹,用作本次文件的存放。初学者可以手动创建,本次实验创建的java程序名称为:WordCoun.java。创建的文件名为:wordcount。文件创建好后,可以在终端检查文件是否创建成功。

在文件夹和java程序创建好后,进行java包的编译,编译整个包里的文件。编译过程如若出现错误:

则需要重新设置环境变量:
·export功能说明:设置或显示环境变量。export可新增,修改或删除环境变量,供后续执行的程序使用。
·$():这个小括号里放的是命令,和``反引号作用一样,执行这个命令。
(对比补充:${}:这里面放的是变量,用来引用的)
·$HADOOP_HOME/bin/hadoop classpath:在此修改hadoop的环境变量,其中bin为命令保存目录。
·source命令通常用于重新执行刚修改的初始化文件,使之立即生效,而不必注销并重新登录。即使/etc/profile文件修改后立即生效 。
环境变量设置方法:
/etc/profile :在登录时,操作系统定制用户环境时使用的第一个文件,此文件为系统的每个用户设置环境信息,当用户第一次登录时,该文件被执行。
或设置成永久变量:
1.环境变量配置中,要先删除.bash_profile中的三行关于.bashrc的 定义,然后把环境变量配置在.bashrc中
2.选择要使用的java环境:update-alternatives –config java
3.要使得刚修改的环境变量生效:source .bashrc
4.查看环境变量:env
环境变量设置好后需要重新编译java包:
(c表示打包,v表示输出整个过程的详细信息,f表示后面要跟上输出文件名称)
将本地文件上传到hadoop上,并检查是否传入成功:
·其语法为:Hdfs dfs -put 本地文件 /HDFS集群上的文件
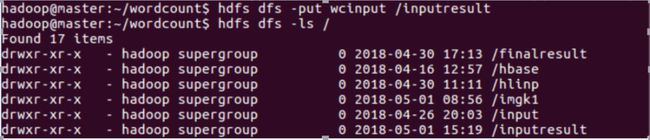
上传文件后,设置文件输出路径
![]()
建立输出路径:hadoop jar 压缩包.jar WordCount 输入路径 输出路径
注意:做mapreduce计算时候,输出一般是一个文件夹,而且该文件夹是不能存在,而且这个检查做的很早,当我们提交job时候就会进行,mapreduce之所以这么设计是保证数据可靠性,如果输出目录存在reduce就搞不清楚你到底是要追加还是覆盖,不管是追加和覆盖操作都会有可能导致最终结果出问题,mapreduce是做海量数据计算,一个生产计算的成本很高,例如一个job完全执行完可能要几个小时,因此一切影响错误的情况mapreduce是零容忍的。
重查找输入内容:

随后hadoop将会运行map和reduce任务:

当map 100% reduce 100%时说明任务运行完成。此后可以进行结果的输出:
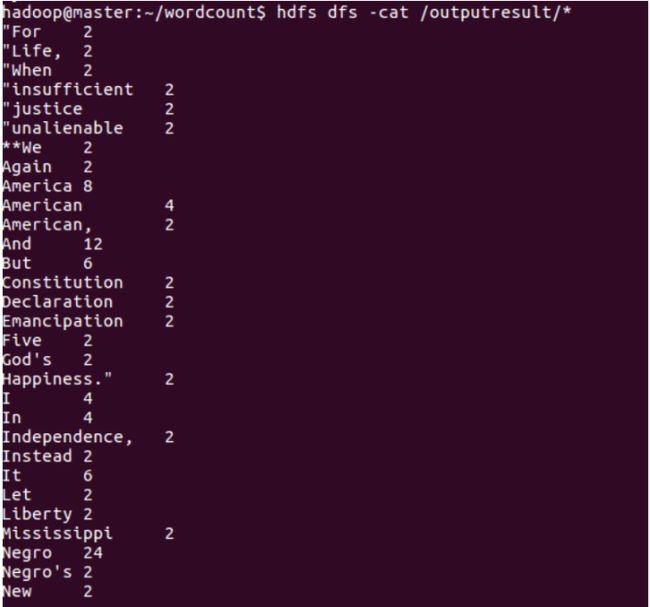


附件:Wordcount的Java源码。
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}