毕业设计- 基于深度神经网络的语音关键词检出系统-上手currennt-1
今天在服务器上继续跑currennt的试验,作为基本内容,第一波基础知识奉上:
首先currennt是用来借助CUDA的并行计算能力实现回归神经网络的一个工具包,目前编者需要用到其中的speechrecognition即语音识别的currennt样例做实验。
回归神经网络在处理语音识别这种序列(顺序相关)信号时表现出优于普通神经网络的效果。
currennt工具包中定义神经网络结构的方式很简单,直接写入一个json文件并在运行时指定即可,一个典型的网络结构文件示例如下:

(该示例表示了一个使用39维MFCC特征对51个词进行语音识别的神经网络。)
源数据中指定layers内容,其中包含若干层依次对应网络中的各个层级,各层有三到四个属性
size指定节点数;name为其命名;type指定层类型;bias指定偏置量用于调整网络参数,防止过拟合问题。
其中层类型在此特作说明,currennt中的层类型可构建以下几种(来自于README文件):
隐层可设类型如下
tanh作激励函数
*feedforward_tanh = Feed forward layer with tanh as activationfunction
*feedforward_logistic = Feed forward layer with a logistic activationfunction
*feedforward_identity = Feed forward layer with f(x)=x activationfunction
*softmax = Feed forward layer with softmax activationfunction
*lstm = Unidir. LSTM layer with forget gates andpeepholes
*blstm = Bidir. LSTM layer with forget gates andpeepholes
输出层可设
sse;weighted_sse;rmse;ce;binary_classification;multiclass_classification;sse_mask;
具体意思日后用起来慢慢聊,example中采用multiclass_classification用于获取最后输出结果。
(multiclass_classification指多选一型的数据输出)
在网络建立起来之后就可以利用currennt工具将示例程序跑起来,调用命令是运行run.sh中的该条指令(或直接运行.run):
#”$@”返回当前绝对路径,以下命令将当前路径加上配置文件内容作为参数传给currennt程序
../../../build/currennt"$@" --options_file config.cfg 通过指定配置文件将可以跟到currennt命令后的一堆内容存起来,便于使用。而config.cfg当中则指定了程序的运行的具体参数(训练还是测试,初始化方法,最大迭代次数,输入文件,输出文件等内容),
示例config文件内容如下所示
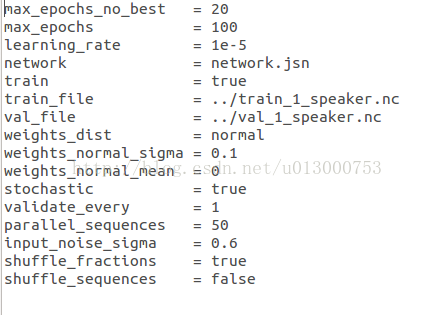
运行结果见下图:


运行结果标示了训练出的网络对以下词的识别效果(带噪)(共51词):
labels ="a","again","at", "b", "bin", "blue", "by", "c", "d", "e","eight", "f", "five", "four", "g","green","h", "i","in","j", "k", "l",
"lay","m", "n","nine","now","o","one","p","place","please","q","r","red","s","set","seven","six","soon","t","three","two","u",
"v","white","with","x","y","z","zero" ;
注:currennt在本机环境下编译仍然存在问题,因为服务器权限有些限制,还是需要把currennt编译搞定便于进行小数据下的试验,防止怒跑三天出坏结果的惨剧==带我完成之日再来记录配置方法。
从README中发现。。做个好用的开源软件分享后在README中写上参考文献TEX代码是个刷引用率的方法,CURRENT作者们便在README中留下了该内容。
明日分析输入,输出的NC文件内容,作为一个语音识别样例,没有直接可以听的文件总感觉不直观。。有必要好好认识下NC文件。
神经网络高大上的内容真的需要大量的人工调参,标数据等各种内容。。。充满着现代科技的违和感~~明日开始用Markdown编辑器写东西。