redis基本数据结构的源码实现
redis是在业界常用的NoSQL数据库,它以简单,高效,支持丰富的数据结构而著称,下面就简单介绍下redis中各种数据结构的底层实现。
1.String
string是redis中最基础的数据结构,redis是由c实现的,但是redis中的string却不是由char完成的,而是redis自定义了一种sds(Simple Dynamic String)的数据结构。sds的基本数据结构如下:
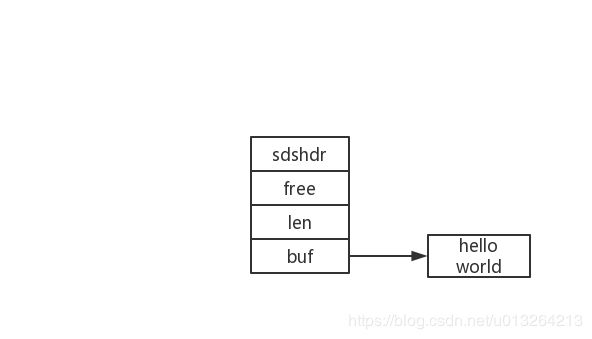
其中shshdr是一个结构体,可以理解为sds的头部,用于描述string的一些信息,比如长度,剩余空间等,具体如下:
struct sdshdr {
// buf 已占用长度
int len;
// buf 剩余可用长度
int free;
// 实际保存字符串数据的地方
char buf[];
};
sdshdr是指向头部地址的指针,len表示字符串buf已经使用的长度,free表示字符串剩余的未使用的长度,因为redis的字符串是预分配内存的,所以往往会有一些剩余内存的存在,至于为什么这样做,下文会解释。buf则指向字符串的实际地址。从头部结构可以看出,redis获取字符串长度的时间复杂度是O(1),如果用C语言的char实现redis的话,则获取时间复杂度是O(n)。另外Redis的字符串是二进制安全的,即redis不仅可以处理可见的ASCII码,也可以处理不可见的ASCII码,这也为string支持bitmap的用法埋下伏笔。
下面以sds的创建和追加操作为例来讲解redis的部分源码。
首先是创建,源码如下:
/* Create a new sds string starting from a null terminated C string. */
sds sdsnew(const char *init) {
size_t initlen = (init == NULL) ? 0 : strlen(init);
return sdsnewlen(init, initlen);
}
这个方法是创建一个新的sds,通过传入一个字符串指针,调用sdsnewlen创建,然后看下sdsnewlen方法。
sds sdsnewlen(const void *init, size_t initlen) {
void *sh;
sds s;
char type = sdsReqType(initlen);
/* Empty strings are usually created in order to append. Use type 8
* since type 5 is not good at this. */
if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8;
int hdrlen = sdsHdrSize(type);
unsigned char *fp; /* flags pointer. */
sh = s_malloc(hdrlen+initlen+1);
if (init==SDS_NOINIT)
init = NULL;
else if (!init)
memset(sh, 0, hdrlen+initlen+1);
if (sh == NULL) return NULL;
s = (char*)sh+hdrlen;
fp = ((unsigned char*)s)-1;
switch(type) {
case SDS_TYPE_5: {
*fp = type | (initlen << SDS_TYPE_BITS);
break;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
}
if (initlen && init)
memcpy(s, init, initlen);
s[initlen] = '\0';
return s;
}
首先是根据传入的字符串长度判断头部结构属于哪种类型,这些头部的类型定义见sds.h文件,如果长度是0则按SDS_TYPE_8处理。然后是获取头部长度。根据头部长度和字符串长度获取分配长度,这里加1的原因是C语言是\0结尾。
另外介绍下追加,函数是:
sds sdscat(sds s, const char *t) {
return sdscatlen(s, t, strlen(t));
}
可以看到,追加函数是直接调用sdscatlen,函数实现如下:
sds sdscatlen(sds s, const void *t, size_t len) {
size_t curlen = sdslen(s);
s = sdsMakeRoomFor(s,len);
if (s == NULL) return NULL;
memcpy(s+curlen, t, len);
sdssetlen(s, curlen+len);
s[curlen+len] = '\0';
return s;
}
首先算一下当前字符串的长度,然后分配空间,这里调用s = sdsMakeRoomFor(s,len);这行代码实现空间分配,具体实现如下:
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
size_t avail = sdsavail(s);
size_t len, newlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
/* Return ASAP if there is enough space left. */
if (avail >= addlen) return s;
len = sdslen(s);
sh = (char*)s-sdsHdrSize(oldtype);
newlen = (len+addlen);
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
type = sdsReqType(newlen);
/* Don't use type 5: the user is appending to the string and type 5 is
* not able to remember empty space, so sdsMakeRoomFor() must be called
* at every appending operation. */
if (type == SDS_TYPE_5) type = SDS_TYPE_8;
hdrlen = sdsHdrSize(type);
if (oldtype==type) {
newsh = s_realloc(sh, hdrlen+newlen+1);
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
/* Since the header size changes, need to move the string forward,
* and can't use realloc */
newsh = s_malloc(hdrlen+newlen+1);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1);
s_free(sh);
s = (char*)newsh+hdrlen;
s[-1] = type;
sdssetlen(s, len);
}
sdssetalloc(s, newlen);
return s;
}
这个方法比较核心,主要说的是分配空间的策略,首先看下当前sds的剩余空间是否够追加字符串的空间,如果够的话则直接返回,如果不够,则需要重新分配,判断下新的字符传长度是否大于1M,如果不是,则直接长度double,如果是,则追加1M,另外对应的头结点也需要改变。