JavaScript的内存机制
JavaScript内存空间并不是一个经常被提及的概念,很容易被大家忽视。包括我自己,可是我发现由于对它们的模糊认知,导致了很多东西理解得并不明白。比如最基本的引用数据类型为什么会叫引用数据类型?浅复制与深复制有什么不同?还有闭包,原型等等。 了解JavaScript内存机制有助于开发人员能清晰的认识到自己写的代码在执行的过程中发生过什么,也能够提高项目的代码质量。
JS的内存空间分为栈、堆、池(一般也会归类为栈中)。
其中栈存放变量,堆存放复杂对象,池存放常量,所以也叫常量池。
栈数据结构
栈是一种特殊的列表,栈内的元素只能通过列表的一端访问,这一端称为栈顶。 栈被称为是一种后入先出的数据结构。 由于栈具有后入先出的特点,所以任何不在栈顶的元素都无法访问。 为了得到栈底的元素,必须先拿掉上面的元素。

像上图中的乒乓球,最顶层的5号乒乓球,它是最后被放进去的,但是可以最先被使用,但是如果我们想要使用最底层的1号乒乓球,我们必须将上面的4个乒乓球取出来,才可以被使用。
堆数据结构
堆是一种经过排序的树形数据结构,每个结点都有一个值。堆的存取是随意,这就如同我们在图书馆的书架上取书, 虽然书的摆放是有顺序的,但是我们想取任意一本时不必像栈一样,先取出前面所有的书, 我们只需要关心书的名字或者书的序号,就可以取到想要的书。
变量类型与内存的关系
基本数据类型
基本数据类型共有6种:
-
Sting
-
Number
-
Boolean
-
null
-
undefined
-
Symbol(ES6 引入了一种新的原始数据类型Symbol,表示独一无二的值。它是 JavaScript 语言的第七种数据类型。有兴趣了解:https://www.jianshu.com/p/f40a77bbd74e)
基本数据类型保存在栈内存中,因为基本数据类型占用空间小、大小固定,通过按值来访问,属于被频繁使用的数据。但是闭包中的基本数据类型变量不保存在栈内存中,而是保存在堆内存中。
let num1 = 1; let num2 = 1;

引用数据类型
Array,Function,Object...可以认为除了上面提到的基本数据类型以外,所有类型都是引用数据类型。
引用数据类型存储在堆内存中,因为引用数据类型占据空间大、大小不固定。 如果存储在栈中,将会影响程序运行的性能; 引用数据类型在栈中存储了指针,该指针指向堆中该实体的起始地址。 当解释器寻找引用值时,会首先检索其在栈中的地址,取得地址后从堆中获得实体。
// 基本数据类型-栈内存
let a1 = 0;
// 基本数据类型-栈内存
let a2 = 'this is string';
// 基本数据类型-栈内存
let a3 = null;
// 对象的指针存放在栈内存中,指针指向的对象存放在堆内存中
let b = { m: 20 };
// 数组的指针存放在栈内存中,指针指向的数组存放在堆内存中
let c = [1, 2, 3];

因此当我们要访问堆内存中的引用数据类型时,实际上我们首先是从变量中获取了该对象的地址指针, 然后再从堆内存中取得我们需要的数据。
以上的存储概念清晰的话,就可以很好的解释一些常见的问题了:
1.ES6中的const可以被“重新赋值”
ES6语法中的 const 声明一个只读的常量。一旦声明,常量的值就不能改变。但是下面的代码可以改变 const 的值:
const foo = {}; foo.prop = 123; foo.prop // 123
foo = {}; // Identifier 'foo' has already been declared
这是因为foo存储在占内存中,存的值始终是一个对象的地址,改变对象值的时候,对foo存储的值没有影响。
2.变量复制
基本数据类型的复制
let a = 20; let b = a; b = 30; console.log(a); // 此时a的值是多少,是30?还是20?
答案是:20
在这个例子中,a、b 都是基本类型,它们的值是存储在栈内存中的,a、b 分别有各自独立的栈空间, 所以修改了 b 的值以后,a 的值并不会发生变化。
从下图可以清晰的看到变量是如何复制并修改的。

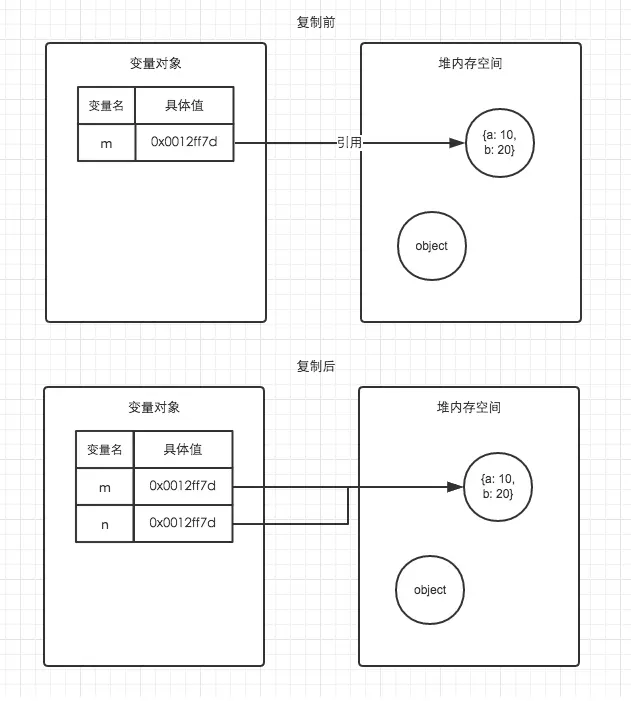
引用数据类型的复制
let m = { a: 10, b: 20 };
let n = m;
n.a = 15;
console.log(m.a) //此时m.a的值是多少,是10?还是15?
答案是:15
在这个例子中,m、n都是引用类型,栈内存中存放地址指向堆内存中的对象, 引用类型的复制会为新的变量自动分配一个新的值保存在变量中, 但只是引用类型的一个地址指针而已,实际指向的是同一个对象, 所以修改 n.a 的值后,相应的 m.a 也就发生了改变。
内栈内存和堆内存的垃圾回收
有些语言(比如 C 语言)必须手动释放内存,程序员负责内存管理。这很麻烦,所以大多数语言提供自动内存管理,减轻程序员的负担,这被称为"垃圾回收机制"。栈内存中变量一般在它的当前执行环境结束就会被销毁被垃圾回收制回收, 而堆内存中的变量则不会,因为不确定其他的地方是不是还有一些对它的引用。 堆内存中的变量只有在所有对它的引用都结束的时候才会被回收。
内存泄露
什么是内存泄漏?对于持续运行的服务进程,必须及时释放不再用到的内存。否则,内存占用越来越高,轻则影响系统性能,重则导致进程崩溃。 不再用到的内存,没有及时释放,就叫做内存泄漏。
闭包的内存泄漏问题
闭包中的变量并不保存在栈内存中,而是保存在堆内存中。 这也就解释了函数调用之后为什么闭包还能引用到函数内的变量。
function A() {
let a = 1;
function B() {
console.log(a);
}
return B;
}
let res = A();
函数 A 返回了一个函数 B,并且函数 B 中使用了函数 A 的变量,函数 B 就被称为闭包。
函数 A 弹出调用栈后,函数 A 中的变量这时候是存储在堆上的,所以函数B依旧能引用到函数A中的变量。
原因就在于A是B的父函数,而B被赋给了一个全局变量res,这导致B始终在内存中,而B的存在依赖于A,因此A也始终在内存中,不会在调用结束后,被垃圾回收机制回收。
那么垃圾回收机制是怎样的呢?
以下是JavaScript垃圾回收机制中如何判断内存中已经不再使用了的两种算法:
1.引用计数算法
引用其实就是指向某一物体的指针,也可简单将引用视为一个对象访问另一个对象的路径。
引用计数算法定义“内存不再使用”的标准很简单,就是看一个对象是否有指向它的引用。如果没有其他对象指向它了,说明该对象已经不再需了。
// 创建一个对象person,他有两个指向属性age和name的引用
var person = {age: 12, name: 'aaaa'};
// 虽然设置为null,但因为person对象还有指向name的引用,因此name不会回收
person.name = null;
var p = person;
//原来的person对象被赋值为1,但因为有新引用p指向原person对象,因此它不会被回收
person = 1;
//原person对象已经没有引用,很快会被回收
p = null;
2.标记清除算法
现代浏览器通用的大多是基于标记清除算法的某些改进算法,和引用记数算法总体思想都是一致的。
标记清除算法将“不再使用的对象”定义为“无法达到的对象”。
简单来说,就是从根部(在JS中就是全局对象)出发定时扫描内存中的对象。凡是能从根部到达的对象,都是还需要使用的。那些无法由根部出发触及到的对象被标记为不再使用,稍后进行回收。
从这个概念可以看出,无法触及的对象包含了没有引用的对象这个概念(没有任何引用的对象也是无法触及的对象)。但反之未必成立。
email.message = document.createElement(“div”); displayList.appendChild(email.message); displayList.removeAllChildren();
div元素已经从DOM树中清除,也就是说从DOM树的根部无法触及该div元素了。但是请注意,div元素同时也绑定了email对象。所以只要email对象还存在,该div元素将一直保存在内存中。
总结
虽然JavaScript提供了垃圾回收机制,但是还是会存在内存泄漏的问题。如果你的引用只包含少量JS交互,那么内存管理不会对你造成太多困扰。但是如果你的引用包含大量JS交互,那么就应当在写代码时候多考虑内存泄露的问题了。不要满足于写出能运行的程序,也不要认为机器的升级就能解决问题,要从根源上解决问题还得从代码开始。
参考:
1.https://juejin.im/post/5b10ba336fb9a01e66164346#heading-14
2.https://juejin.im/post/5d116a9df265da1bb47d717b
3.http://www.ruanyifeng.com/blog/2017/04/memory-leak.html