hadoop集群安装配置
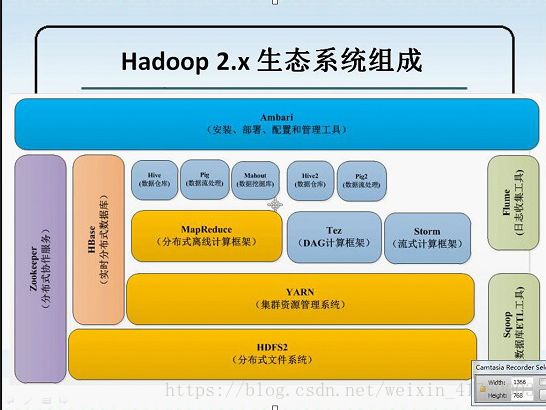
HDFS2分布式文件系统
YARN集群资源管理器来做任务的分发调度
mapReduce分布式离线计算框架,主要做日志分析(java语言编写),storm实时计算框架
Zookcaper高可用系统
一、hadoop单节点配置
1、hadoop安装部署
[root@server1 ~]# id 800
id: 800: No such user
[root@server1 ~]# useradd -u 800 hadoop
[root@server1 ~]# id hadoop
uid=800(hadoop) gid=800(hadoop) groups=800(hadoop)
[root@server1 ~]# ls
3.0.97 hadoop-2.7.3.tar.gz jdk-7u79-linux-x64.tar.gz
[root@server1 ~]# mv * /home/hadoop/
[root@server1 ~]# su - hadoop
[hadoop@server1 ~]$ ls
hadoop-2.7.3.tar.gz jdk-7u79-linux-x64.tar.gz
[hadoop@server1 ~]$ tar zxf jdk-7u79-linux-x64.tar.gz
[hadoop@server1 ~]$ tar zxf hadoop-2.7.3.tar.gz
[hadoop@server1 ~]$ ls
hadoop-2.7.3.tar.gz jdk-7u79-linux-x64.tar.gz
hadoop-2.7.3 jdk1.7.0_79
[hadoop@server1 ~]$ ln -s jdk1.7.0_79/ java
[hadoop@server1 ~]$ ln -s hadoop-2.7.3 hadoop
[hadoop@server1 ~]$ cd hadoop
[hadoop@server1 hadoop]$ ls
bin include libexec NOTICE.txt sbin
etc lib LICENSE.txt README.txt share
[hadoop@server1 hadoop]$ cd etc/hadoop/
[hadoop@server1 hadoop]$ vim hadoop-env.sh
25 export JAVA_HOME=/home/hadoop/java
[hadoop@server1 hadoop]$ ls
capacity-scheduler.xml httpfs-env.sh mapred-env.sh
configuration.xsl httpfs-log4j.properties mapred-queues.xml.template
container-executor.cfg httpfs-signature.secret mapred-site.xml.template
core-site.xml httpfs-site.xml slaves
hadoop-env.cmd kms-acls.xml ssl-client.xml.example
hadoop-env.sh kms-env.sh ssl-server.xml.example
hadoop-metrics2.properties kms-log4j.properties yarn-env.cmd
hadoop-metrics.properties kms-site.xml yarn-env.sh
hadoop-policy.xml log4j.properties yarn-site.xml
hdfs-site.xml mapred-env.cmd
[hadoop@server1 hadoop]$ cd ..
[hadoop@server1 etc]$ cd ..
[hadoop@server1 hadoop]$ ls
bin include libexec NOTICE.txt sbin
etc lib LICENSE.txt README.txt share
####################################################测试一下
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ mkdir input
[hadoop@server1 hadoop]$ ll -d input/
drwxrwxr-x 2 hadoop hadoop 4096 Jul 21 09:52 input/
[hadoop@server1 hadoop]$ cp etc/hadoop/* input/
[hadoop@server1 hadoop]$ ls
bin include lib LICENSE.txt README.txt share
etc input libexec NOTICE.txt sbin
[hadoop@server1 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar grep input output 'dfs[a-z.]+' ##过滤input表中以dfs开头的文件,cp到output表中
[root@server1 hadoop]# ls output/
part-r-00000 _SUCCESS
二、伪分布式hadoop配置
1、配置hadoop
[hadoop@server1 hadoop]$ cd etc/hadoop/
[hadoop@server1 hadoop]$ vim core-site.xml
fs.defaultFS
hdfs://172.25.12.1:9000
[hadoop@server1 hadoop]$ vim slaves
172.25.12.1
[hadoop@server1 hadoop]$ vim hdfs-site.xml
dfs.replication
1
2、配置ssh免密
[hadoop@server1 hadoop]$ ssh-keygen
[hadoop@server1 hadoop]$ cd
[hadoop@server1 ~]$ cd .ssh/
[hadoop@server1 .ssh]$ cp id_rsa.pub authorized_keys
[hadoop@server1 .ssh]$ ssh localhost
[hadoop@server1 ~]$ logout
[hadoop@server1 .ssh]$ ssh 172.25.12.1
[hadoop@server1 ~]$ logout
[hadoop@server1 .ssh]$ ssh server1
[hadoop@server1 ~]$ logout
[hadoop@server1 .ssh]$ ssh 0.0.0.0
[hadoop@server1 ~]$ logout
3、格式化hdfs
[hadoop@server1 ~]$ pwd
/home/hadoop
[hadoop@server1 ~]$ cd hadoop
[hadoop@server1 hadoop]$ bin/hdfs namenode -format
[hadoop@server1 hadoop]$ ls /tmp/
hadoop-hadoop hsperfdata_hadoop
4、启动dfs
[hadoop@server1 hadoop]$ sbin/start-dfs.sh
Starting namenodes on [server1]
server1: starting namenode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-namenode-server1.out
172.25.12.1: starting datanode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-server1.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-secondarynamenode-server1.out
5、配置环境变量
[hadoop@server1 ~]$ vim .bash_profile
PATH=$PATH:$HOME/bin:~/java/bin
[hadoop@server1 ~]$ source .bash_profile
[hadoop@server1 ~]$ jps
2032 Jps
1646 NameNode
1922 SecondaryNameNode
1739 DataNode
配置完成后,可以查看到相关端口
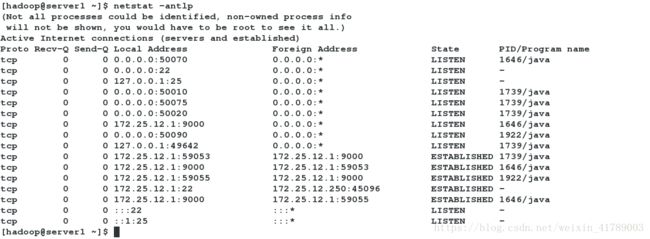
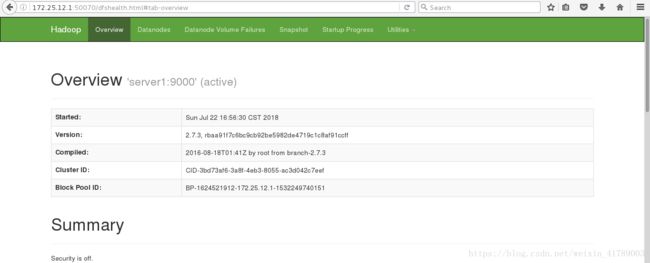
此时可以在浏览器中用ip+port方式访问:

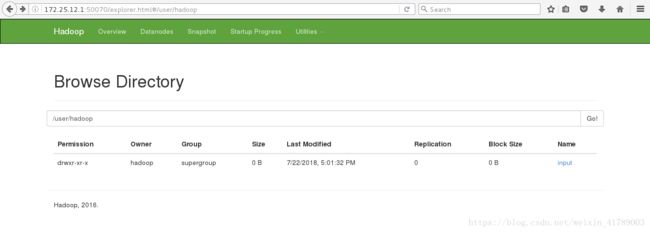
[hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir /user
[hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir /user/hadoop
[hadoop@server1 hadoop]$ mkdir input
[hadoop@server1 hadoop]$ cp etc/hadoop/* input/
[hadoop@server1 hadoop]$ bin/hdfs dfs -put input/
[hadoop@server1 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount input output ##统计input表中的单词的数量,并导入到output中
此时网页访问,可以看到内容
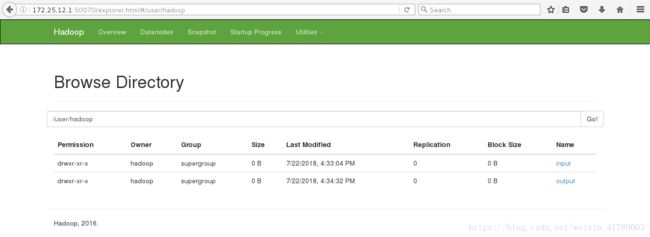
三、完全分布式hadoop部署
| hostname | ip | 角色 |
|---|---|---|
| server1 | 172.25.12.1 | master |
| server2 | 172.25.12.2 | slave |
| serave3 | 172.25.12.3 | slave |
注意:需要关闭伪分布式时打开的dfs重新配置
[hadoop@server1 hadoop]$ sbin/stop-dfs.sh
Stopping namenodes on [server1]
server1: stopping namenode
172.25.12.1: stopping datanode
Stopping secondary namenodes [0.0.0.0]
0.0.0.0: stopping secondarynamenode
1、server1配置nfs
登出到root用户
[root@server1 ~]# yum install -y nfs-utils
[root@server1 ~]# /etc/init.d/rpcbind start
Starting rpcbind: [ OK ]
[root@server1 ~]# vim /etc/exports
/home/hadoop *(rw,anonuid=800,anongid=800)
[root@server1 ~]# /etc/init.d/nfs start
Starting NFS services: [ OK ]
Starting NFS mountd: [ OK ]
Starting NFS daemon: [ OK ]
Starting RPC idmapd: [ OK ]
[root@server1 ~]# exportfs -v
/home/hadoop (rw,wdelay,root_squash,no_subtree_check,anonuid=800,anongid=800)
[root@server1 ~]# exportfs -rv
exporting *:/home/hadoop
2、server2和server3配置
[root@server2 ~]# yum install -y nfs-utils
[root@server2 ~]# /etc/init.d/rpcbind start
Starting rpcbind: [ OK ]
[root@server2 ~]# showmount -e 172.25.12.1
Export list for 172.25.12.1:
/home/hadoop *
[root@server2 ~]# useradd -u 800 hadoop
[root@server2 ~]# mount 172.25.12.1:/home/hadoop/ /home/hadoop/
[root@server2 ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/VolGroup-lv_root 19134332 930624 17231728 6% /
tmpfs 510188 0 510188 0% /dev/shm
/dev/vda1 495844 33463 436781 8% /boot
172.25.12.1:/home/hadoop/ 19134336 1940096 16222336 11% /home/hadoop
[root@server2 ~]# su - hadoop
3、配置
[root@server1 ~]# su - hadoop
[hadoop@server1 ~]$ cd hadoop/etc/
[hadoop@server1 etc]$ vim hadoop/slaves
172.25.120.2
172.25.120.3
[hadoop@server1 etc]$ vim hadoop/hdfs-site.xml
dfs.replication
2
[hadoop@server1 etc]$ cd /tmp/
[hadoop@server1 tmp]$ rm -fr *
测试免密
[hadoop@server1 tmp]$ ssh server2
[hadoop@server2 ~]$ logout
[hadoop@server1 tmp]$ ssh server3
[hadoop@server3 ~]$ logout
[hadoop@server1 tmp]$ ssh 172.25.120.2
[hadoop@server2 ~]$ logout
[hadoop@server1 tmp]$ ssh 172.25.120.3
[hadoop@server2 ~]$ logout
重新格式化
[hadoop@server1 hadoop]$ bin/hdfs namenode -format
再次打开dfs,namenode和datanode将会分来
[hadoop@server1 hadoop]$ sbin/start-dfs.sh
Starting namenodes on [server1]
server1: starting namenode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-namenode-server1.out
172.25.12.2: starting datanode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-server2.out
172.25.12.3: starting datanode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-server3.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-secondarynamenode-server1.out
[hadoop@server1 hadoop]$ jps
3504 Jps
3207 NameNode
3395 SecondaryNameNode
server2节点
[hadoop@server2 ~]$ jps
1594 DataNode
1667 Jps
server3节点
[hadoop@server3 ~]$ jps
1576 DataNode
1650 Jps
web页面可以直接看到datanode节点
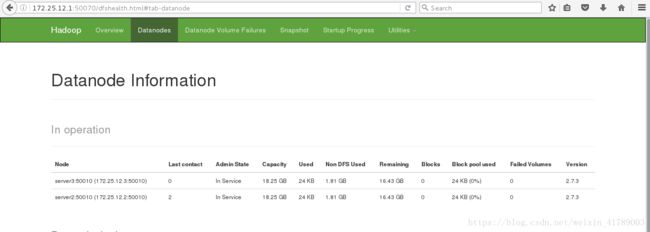
文件处理
[hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir /user
[hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir /user/hadoop
[hadoop@server1 hadoop]$ bin/hdfs dfs -put etc/hadoop/ input
web页面访问