CentOS 基础知识与命令总结
文章目录
- History 命令
- 目录含义
- ll-h显示的信息
- 查看盘符对应UUID
- sed命令
- 查询
- 显示行号
- 不区分大小写
- 识别正则表达式
- 删除
- 修改
- 替换
- 对源文件进行操作
- Find命令
- 用法示例
- find命令的参数详解
- 按文件名查找
- 按路径查找
- 用正则表达式匹配文件或目录名
- 指定文件长度查找
- 按文件类型查找
- 按时间类型查找
- 常用命令
- 给 指定用户 授予 权限
- sort命令
- 对字符串排序
- 去重排序
- 对数值排序
- 对成绩排序
- wc命令
- uniq命令
- awk命令
- 模糊查询
- 指定分割符, 根据下标显示内容
- 指定分割符, 根据下标显示内容
- 调用 awk 提供的函数
- if语句 查询及格的学生信息
- awk的内置字符串函数
- awk常用内置变量
- split命令
- tr命令
- tee命令
- Crontab命令
- SCP远程文件拷贝
- 常用的压缩命令
- 用户、用户组、权限 相关操作
- 用户组的增删改查
- 用户的增删改查
- Linux passwd命令
- 语法
- 如何将用户从一个组中移除?
- usermod的用法
- 权限介绍
- Linux sudo命令总结
- /etc/passwd内容含义
- Linux输出重定向>和>>区别如下:
History 命令
history
列出之前敲过的命令
目录含义
| 目录 | 含义 |
|---|---|
| /bin | 二进制命令所在的目录 |
| /boot | 系统引导程序所需要的文件目录,引导系统开机 |
| /dev | 设备软件目录,磁盘,光驱, |
| /etc | 系统配置,启动程序 |
| /home | 普通用户的家,目录默认数据存放目录 |
| /lib | 启动系统和运行命令所需的共享库文件和内核模块存放 |
| /mnt | 临时挂载储存设备的挂载点,u盘插入光驱无法使用,需要挂载然后使用 |
| /opt | 额外的应用软件包 |
| /proc | 操作系统运行时,进程信息和内核信息存放在这里 |
| /root | Linux超级权限用户root的家目录 |
| /sbin | 和管理系统相关的命令,【超级管理员用】 |
| /tmp | 临时文件目录,这个目录被当作回收站使用 |
| /usr | 用户或系统软件应用程序目录 |
| /var | 存放系统日志的目录 |
ll-h显示的信息
当前用户权限 硬链接(本身) 用户 用户组 大小 月份 日期 时间 文件名称
![]()
d — --- —
一共9个 都是权限
前三个:当前用户
中间三个:当前用户所属组
后边三个:其他人
查看盘符对应UUID
命令:ll /dev/disk/by-uuid/

sed命令
| 命令 | 含义 |
|---|---|
| sed 可选项 目标文件 | 对目标文件 进行 过滤查询 或 替换 |
可选参数
| 可选项 | 英文 | 含义 |
|---|---|---|
| p | 打印 | |
| $ | 代表 最后一行 | |
-n |
仅显示处理后的结果 | |
-e |
expression | 根据表达式 进行处理 |
查询
准备数据
vim 1.txt
文件内容:
111:aaa:bbb:ccc
222:ddd:eee:fff
333:ggg:hhh
444:iii
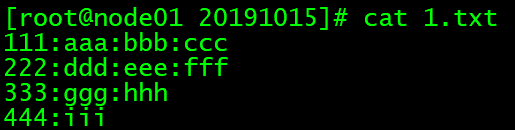
sed -n -e '1,2p' 1.txt
// 列出1到2行的数据

sed -n -e '1,$p' 1.txt
// 列出1.txt所有数据

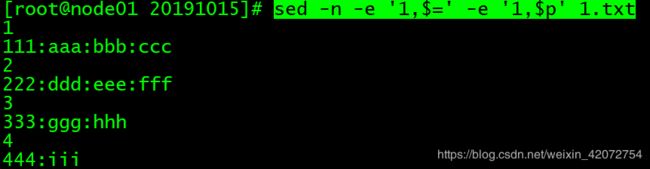
显示行号
| 可选项 | 含义 |
|---|---|
| = | 打印当前行号 |
sed -n -e '1,$=' -e '1,$p' 1.txt
// 显示1.txt所有内容 并显示行号
sed -n -e '/aaa/p' 1.txt
# 显示1.txt中包含aaa的行
![]()
不区分大小写
| 可选项 | 英文 | 含义 |
|---|---|---|
| I | ignore | 忽略大小写 |
识别正则表达式
| 可选项 | 英文 | 含义 |
|---|---|---|
-r |
regexp-extended | 识别正则 |
删除
| 可选项 | 英文 | 含义 |
|---|---|---|
d |
delete | 删除指定内容 |
修改
| 参数 | 英文 | 含义 |
|---|---|---|
| i | insert | 目标前面 插入内容 |
| a | append | 目标后面 追加内容 |
替换
| 英文 | 含义 | |
|---|---|---|
| s/oldString/newString/ | replace | 替换 |
| 选项 | 英文 | |
|---|---|---|
2c 新字符串 |
replace | 使用新字符串 替换 选中的行 |
对源文件进行操作
| 参数 | 英文 | 含义 |
|---|---|---|
| -i | in-place | 替换原有文件内容 |
ifconfig eth0 | grep "inet addr" | sed -e 's/^.*inet addr://' | sed -e 's/Bcast:.*$//'
// 获取ip地址
![]()
Find命令
| 序号 | 命令格式 | 作用 |
|---|---|---|
| 01 | find [路径] -name ‘*.txt’ | 查找指定路径下扩展名是 .txt的文件, 包括子目录 |
如果省略路径, 表示在当前文件夹下查找
find命令后的参数可以有通配符
用法示例
# 示例
find /home/ -name '123.txt'
# 在/home/目录下,查找名为123.txt的文件或目录
find . -name '123.txt'
# 在当前目录下,查找名为123.txt的文件或目录(别忘了点.很小的那个点,仔细看)
find -name '123.txt'
find ./ -name '123.txt'
# 在当前目录下,查找名为123.txt的文件或目录(其实.不写也行,或者写成./也行哦)
find /home/ -name "*123*"
# 在 /home/ 目录下,查找名为以任意多个任意字符开头,中间是123,
# 再以任意多个任意字符结尾的文件或目录
find /home/ -name "*.txt"
# 查找 /home/ 目录下,所有以.txt为扩展名的文件
find /home/ -name "123*"
# 查找 /home/ 目录下,所有以123开头的文件或目录
find命令的参数详解
-
find 查找路径 查找条件 处理动作
-
find 路径 -选项 选项参数 -选项 选项参数 …
后边可以追加很多-选项 选项参数
| 选项 | 选项用法 |
|---|---|
| -name | 按照文件名查找文件。 |
| -perm | 按照文件权限来查找文件。 |
| -empty | 文件为空而且是一个普通文件或者目录。 |
按文件名查找
-name pattern:文件名为pattern的文件。注意如果pattern中包括*等特殊符号的时候,需要加引号。
-iname:name的忽略大小写版本。
-lname pattern:查找符号连接文件名为pattern的文件。
-ilname:lname的忽略大小写版本。
按路径查找
-path pattern:根据完整路径查找文件名为pattern的文件。
-ipath:path的忽略大小写版本。
用正则表达式匹配文件或目录名
-regex pattern
-iregex:regex的忽略大小写版本。
指定文件长度查找
| 可选单位 | 含义 | 简称 |
|---|---|---|
| c | 字节单位。 | 字节 |
| b | 块为单位,块大小为512字节,这个是默认单位。 | 比特 byte |
| w | 以words为单位,words表示两个字节。 | word 俩字节 |
| k | 以1024字节为单位。 | KB |
| M | 以1048576字节为单位。 | MB |
| G | 以1073741824字节温单位。 | GB |
按文件类型查找
c可以选择的类型为:
| 类型 | 含义 |
|---|---|
| b | 块设备文件 |
| c | 字符设备文件 |
| d | 目录文件 |
| p | 管道文件 |
| l | 符号链接文件(小写的L) |
| s | 套接字文件 |
| f | 普通二五年间 |
按时间类型查找
| 类型 | 含义 | 单位 |
|---|---|---|
| -atime | 访问时间(access time),指的是文件最后被读取的时间 | 天 |
| -ctime | 变更时间(change time),指的是**文件本身(权限、所属组、位置…)**最后被变更的时间 | 天 |
| -mtime | 修改时间(modify time),指的是文件内容最后被修改的时间 | 天 |
| -amin | 访问时间(access time) | 分钟 |
| -cmin | 变更时间(change time) | 分钟 |
| -mmin | 修改时间(modify time) | 分钟 |
常用命令
关机 halt
重启 reboot
su + 用户名 切换用户
su zhangsan
# 切换到zhangsan用户
su -u root
# 切换到root用户(有严重的安全隐患)
sudo 命令用来以其他身份来执行命令, 预设的身份为 root
给 指定用户 授予 权限
vim /etc/sudoers
# 默认存在: root用户 具备所有的权限
root ALL=(ALL) ALL
# 授予 zhangsan 用户 所有的权限
zhangsan ALL=(ALL) ALL
- 时间和日期
date查看系统时间cal查看日历
- 磁盘和目录空间
dfdu
- 进程信息
ps进程列表top实时CPU占用表(退出top直接输入q)kill杀死某个进程
| 序号 | 命令 | 作用 |
|---|---|---|
| 01 | ps aux | process status 查看进程的详细情况 |
| 02 | top | 动态显示运行中进程并且排序 |
| 03 | kill [-9] 进程代号 | 终止指定代号的进程 -9 表示强行终止 |
sort命令
sort针对文本文件的内容,以行为单位排序
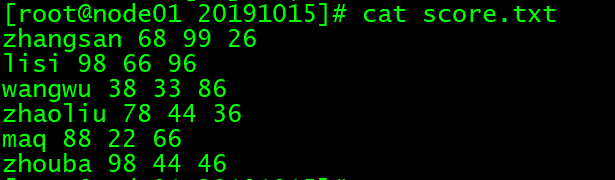
# 开始前在当前目录下创建如下的几个文件
vim score.txt
# 文件内容:
zhangsan 68 99 26
lisi 98 66 96
wangwu 38 33 86
zhaoliu 78 44 36
maq 88 22 66
zhouba 98 44 46
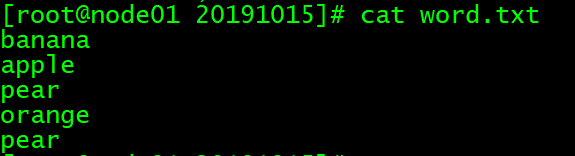
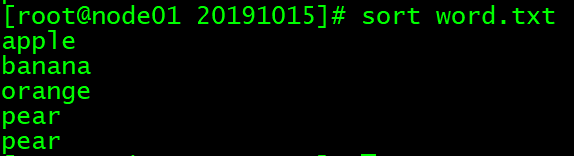
vim word.txt
# 文件内容:
banana
apple
pear
orange
pear
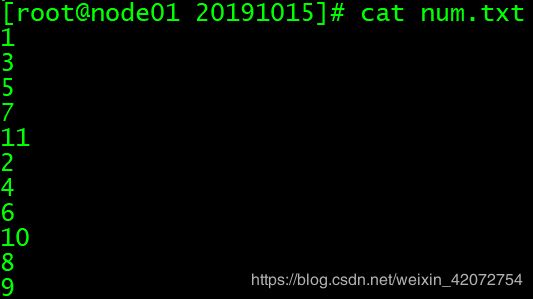
vim num.txt
# 文件内容:
1
3
5
7
11
2
4
6
10
8
9
对字符串排序
sort word.txt
# 对2.txt排序,默认以a,b,c这种ASC码正序排序,排序后显示如下:
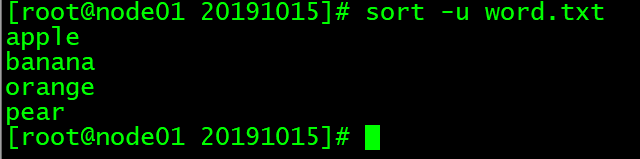
去重排序
| 参数 | 英文 | 含义 |
|---|---|---|
-u |
unique | 在输出行中去除重复行 |
sort -u word.txt
# 对2.txt排序,去除重复内容
# 与上面结果对比可以发现,重复的一个pear被去掉了
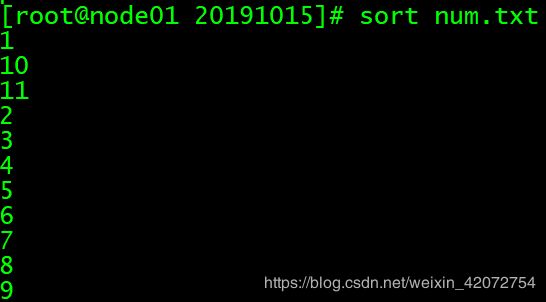
对数值排序
| 参数 | 英文 | 含义 |
|---|---|---|
-n |
numeric-sort | 按照数值大小排序 |
-r |
reverse | 使次序颠倒 |
sort num.txt
# 默认按照字符串排序规则排序
sort -n num.txt
# 按数值大小排序
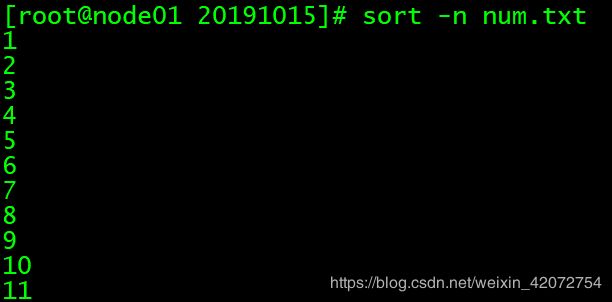
sort -n -r num.txt
# 按数值排序,然后颠倒顺序(reverse)
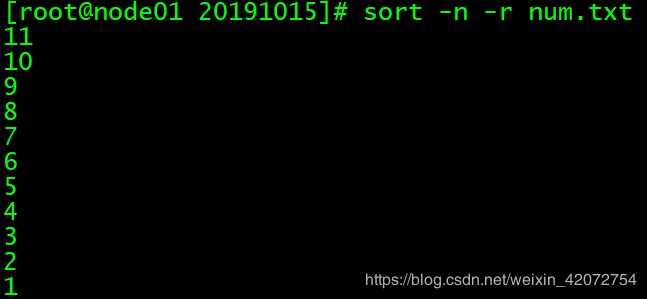
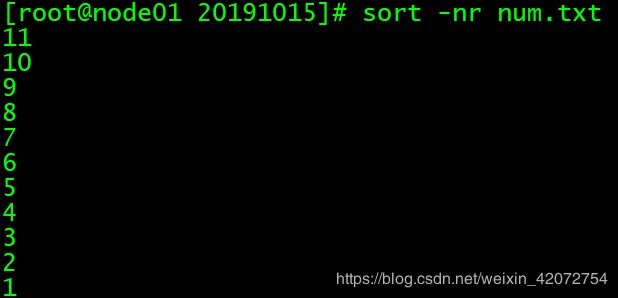
sort -nr num.txt
# 同上面一样,因为命令是可以连用的,所以这里作为演示
对成绩排序
| 参数 | 英文 | 含义 |
|---|---|---|
-t |
field-separator | 指定字段分隔符 |
-k |
key | 根据那一列排序 |
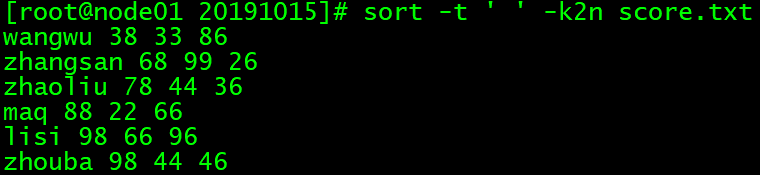
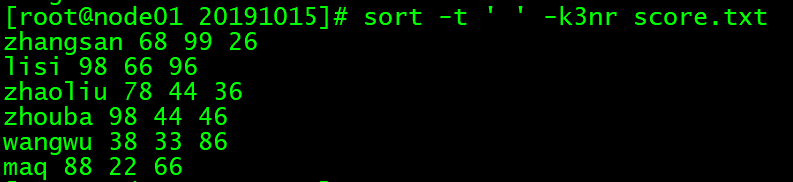
sort -t ' ' -k2n score.txt
# 用空格把数据分为几列,以第二列为准,按数字从小到大排序所有行
# -t 和 -k 通常是一起使用的
sort -t ' ' -k3nr score.txt
# 用空格把数据分为几列,以第三列为准,按数字从大到小排序所有行
-b 忽略每行前面开始空出的空格字符
-c 检查文件是否已经按照顺序排序
-d 排序时,处理英文字母、数字及空格字符外,忽略其他的字符
-f 排序时,将小写字母视为大写字母
-i 排序时,除了040至176之间的ASCII字符外,忽略其他的字符
-m 将几个排序号的文件进行合并
-M 将前面3个字母依照月份的缩写进行排序
-o <输出文件> 将排序后的结果存入制定的文件
wc命令
wc命令可以显示指定文件的 字节数, 单词数, 行数 等信息
准备数据:
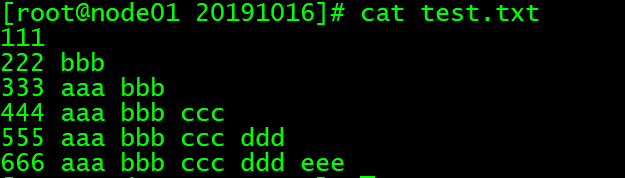
vim test.txt
文件内容:
111
222 bbb
333 aaa bbb
444 aaa bbb ccc
555 aaa bbb ccc ddd
666 aaa bbb ccc ddd eee
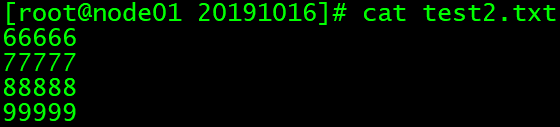
vim test2.txt
文件内容:
66666
77777
88888
99999
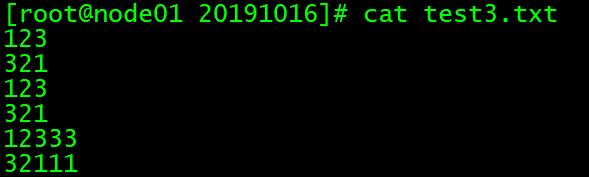
vim test3.txt
文件内容:
123
321
123
321
12333
32111
| 参数 | 英文 | 含义 |
|---|---|---|
-c |
bytes | 字节数 |
-w |
words | 单词数 |
-l |
lines | 行数 |
-m |
lines | 字符数 不能与-c一起用 |
wc -c test.txt
# 显示test.txt的字节数

wc -w test.txt
# 显示test.txt含有的单词数(两个空格之间的内容是单词)

wc -l test.txt
# 显示test.txt总共的行数

wc test.txt
# 依次显示文件的 行数,单词数,字节数,文件名

wc test.txt test2.txt
# 同时统计多个文件的 行数,单词数,字节数,并显示总量

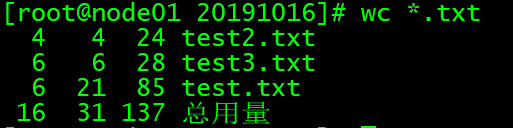
wc *.txt
# 统计当前目录下,所有以.txt为后缀名的文件的 行数,单词数,字节数,并显示总量
# 管道用法:
ls /etc | wc -w
# 统计管道内单词数量
# ls /etc 返回一堆文件名,符合单词形式
# | 把它们压入管道
# wc -w 统计管道内单词数

uniq命令
uniq 命令用于检查及删除文本文件中重复出现的行,一般与 sort 命令结合使用。
| 命令 | 英文 | 含义 |
|---|---|---|
uniq [参数] 文件 |
unique 唯一 | 去除重复行 |
准备内容
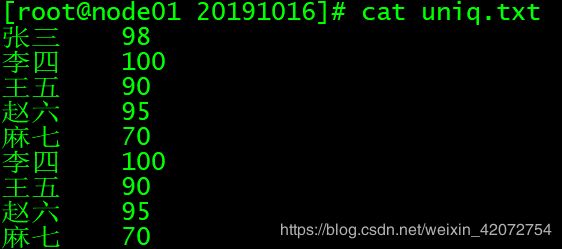
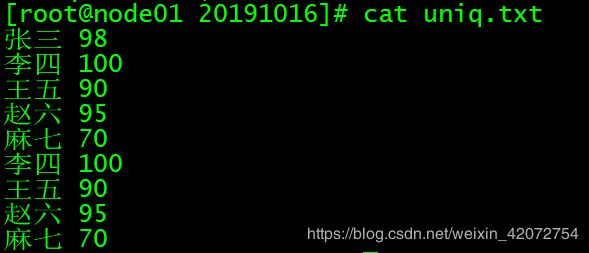
vim uniq.txt
文件内容:
张三 98
李四 100
王五 90
赵六 95
麻七 70
李四 100
王五 90
赵六 95
麻七 70
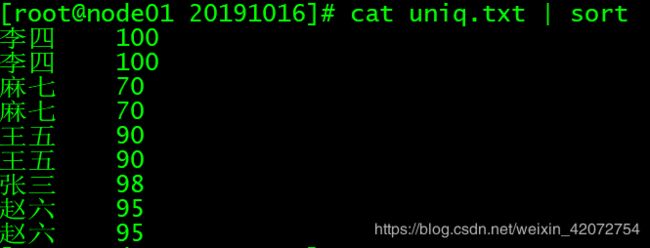
cat uniq.txt | sort
# 排序uniq.txt的内容再展示,这时还没去重
cat uniq.txt | sprt | uniq
# 排序uniq.txt的内容再展示,这时去重了

| 参数 | 英文 | 含义 |
|---|---|---|
-c |
count | 统计每行内容出现的次数 |
cat uniq.txt | sort | uniq -c
# 排序uniq.txt的内容再展示,这时去重了,而且把重复的次数标出来了

awk命令
| 选项 | 英文 | 含义 |
|---|---|---|
-F ',' |
field-separator | 使用 指定字符 分割 |
$ + 数字 |
获取第几段内容 | |
$0 |
获取 当前行 内容 | |
NF |
field | 表示当前行共有多少个字段 |
$NF |
代表 最后一个字段 | |
$(NF-1) |
代表 倒数第二个字段 | |
NR |
代表 处理的是第几行 |
模糊查询
准备数据
vim score.txt
文件内容:
zhangsan 68 99 26
lisi 98 66 96
wangwu 38 33 86
zhaoliu 78 44 36
maq 88 22 66
zhouba 98 44 46

awk '/zhangsan|lisi/' score.txt

指定分割符, 根据下标显示内容
准备数据
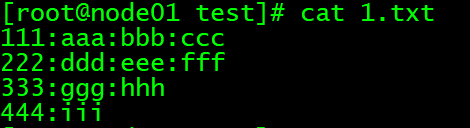
vim 1.txt
文件内容:
111:aaa:bbb:ccc
222:ddd:eee:fff
333:ggg:hhh
444:iii
awk -F ':' '{print $1,$2,$3}' 1.txt
# 操作1.txt文件, 根据冒号分割, 打印 第一段 第二段 第三段 内容
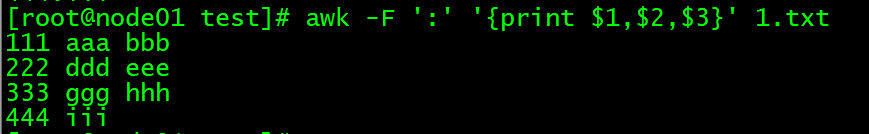
指定分割符, 根据下标显示内容
| 选项 | 英文 | 含义 |
|---|---|---|
OFS="字符" |
output field separator | 向外输出时的段分割字符串 |
awk -F ':' '{OFS="---"}{print $1,$2,$3}' 1.txt
# 同上,但是用---作为分隔符

调用 awk 提供的函数
| 函数名 | 含义 | 作用 |
|---|---|---|
| toupper() | upper | 字符 转成 大写 |
| tolower() | lower | 字符 转成小写 |
| length() | length | 返回 字符长度 |
awk -F ':' '{print toupper($2)}' 1.txt
# 展示以:分割的第二段,并用toupper函数转换成大写

if语句 查询及格的学生信息
| 参数 | 含义 |
|---|---|
| if($0 ~ “aa”) print $0 | 如果这一行包含 “aa”, 就打印这一行内容 |
| if($1 ~ “aa”) print $0 | 如果**第一段 **包含 “aa”, 就打印这一行内容 |
| if($1 == “lisi”) print $0 | 如果第一段 等于 “lisi”, 就打印这一行内容 |
awk -F ' ' '{if($4 > 60) print $1,$4}' score.txt

awk -F ' ' '{if($4 > 60) print $1,$4,"及格";else print $1,$4,"不及格"}' score.txt

求平均分
| 命令 | 含义 |
|---|---|
| awk ‘BEGIN{初始化操作}{每行都执行} END{结束时操作}’ 文件名 | BEGIN{ 这里面放的是执行前的语句 } {这里面放的是处理每一行时要执行的语句} END {这里面放的是处理完所有的行后要执行的语句 } |
awk -F ' ' 'BEGIN{}{total=total+$4}END{print total,NR,(total/NR)}' score.txt
![]()
awk的内置字符串函数
gsub(r,s) 在整个$0中用s替代r
gsub(r,s,t) 在整个t中用s替代r
index(s,t) 返回s中字符串t的第一位置
length(s) 返回s长度
match(s,r) 测试s是否包含匹配r的字符串
split(s,a,fs) 在fs上将s分成序列a
sprint(fmt,exp) 返回经fmt格式化后的exp
sub(r,s) 用$0中最左边最长的子串代替s
substr(s,p) 返回字符串s中从p开始的后缀部分
substr(s,p,n) 返回字符串s中从p开始长度为n的后缀部分
awk常用内置变量
FS:输入字符风隔符,默认为空白字符
OFS:输出字段分隔符,默认为空白 字符
RS:输入记录分隔符(输入换行符),指定输入时的额换行符
NF:number of Field,当前行的字段的个数,字段数量
NR:行号,当前处理的文本行的行号
FNR:各文件分别计数的行号
FILENAME:当前文件名
ARGC:命令行参数的个数
ARGV:数组,保存的是命令行所给定的各参数
匹配的正则:
| ^$ | 匹配空行 |
split命令
| 命令 | 英文 | 含义 |
|---|---|---|
| split -l 1000 文件 | lines | 将大文件切分成若干1000行 的小文件 |
| 命令 | 英文 | 含义 |
|---|---|---|
| split -b 10k 文件 | byte | 将大文件切分成若干10KB的小文件 |
准备数据
vim score.txt
文件内容:
zhangsan 68 99 26
lisi 98 66 96
wangwu 38 33 86
zhaoliu 78 44 36
maq 88 22 66
zhouba 98 44 46
split -b 10 score.txt
# 把score.txt分成10个大小为10字节的文件,多余的部分单独形成一个文件

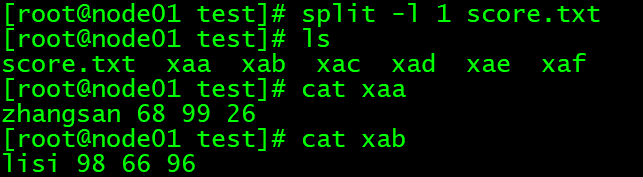
split -l 1 score.txt
# 把score.txt 分成若干个1行的小文件
-d: 使用数字后缀
tr命令
tr 命令用于 替换 或 删除 文件中的字符。
| 命令 | 英文 | 含义 |
|---|---|---|
| 命令结果 | tr 被替换的字符 新字符 | translate | 实现 替换效果 |
echo 'hello' | tr 'h' 'H'
# 把展示的小写的h替换为大写的H
echo 'hello' | tr '[a-z]' '[A-Z]'
# 把展示的小写的hello替换为大写的HELLO
echo 'HELLO' | tr '[A-Z]' '[a-z]'
# 把展示的大写的HELLO替换为小写的hello
| 命令 | 英文 | 含义 |
|---|---|---|
| 命令结果 | tr -d 被删除的字符 | delete | 删除指定的字符 |
echo 'a1b2c3d4' | tr -d '[0-9]'
# 删除a1b2c3d4中的数字
tee命令
| 命令 | 含义 |
|---|---|
| 命令结果 | tee 文件1 文件2 文件3 | 通过 tee 可以将命令结果 通过管道 输出到 多个文件中 |
准备内容
vim uniq.txt
文件内容:
张三 98
李四 100
王五 90
赵六 95
麻七 70
李四 100
王五 90
赵六 95
麻七 70
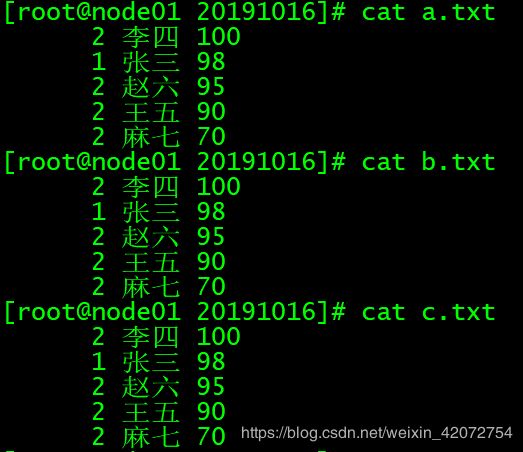
cat uniq.txt | sort -t ' ' -k2nr | uniq -c |tee a.txt b.txt c.txt
# 根据第二行的数字,从大到小排序,去重并显示重复次数,然后展示
# 展示完还要把展示的结果分别写入a.txt b.txt c.txt

Crontab命令
crontab可以做到定时执行某某脚本,某某命令,慎用!。
crontab -e
# 打开定时任务列表(可编辑的任务列表,慎重修改)
crontab -l
# 显示所有的定时任务
crontab -r (轻则服务器崩溃,重则工作不保)
# 删除所有的定时任务
cat /etc/crontab
# 查看5个*的解释
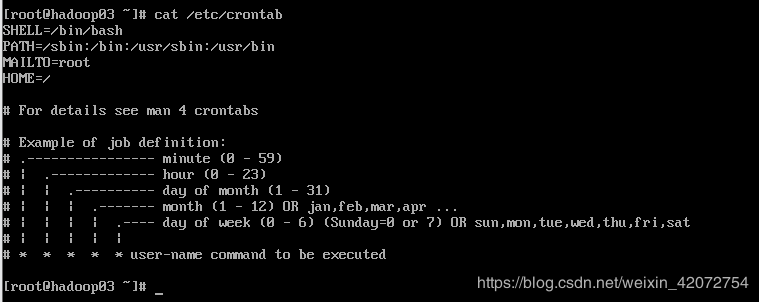
| 含义 | 范围 | |
|---|---|---|
| 第一个 * | 一小时当中的第几分钟 | 0~59 |
| 第二个 * | 一天当中的第几小时 | 0~23 |
| 第三个 * | 一个月当中的第几天 | 1~31 |
| 第四个 * | 一年当中的第几月 | 1~12 |
| 第五个 | 一周当中的星期几 | 0~7(0和7都代表星期日) |
例子
| 命令 | 含义 |
|---|---|
| * * * * * command | 实例1:每1分钟执行一次command |
| 3,15 * * * * command | 实例2: 每小时的第3和第15分钟执行 |
| 3,15 8-11 * * * command | 实例3: 在上午8点到11点的第3和第15分钟执行 |
| 3,15 8-11 */2 * * command | 实例4: 每隔两天的上午8点到11点的第3和第15分钟执行 |
| 3,15 8-11 * * 1 command | 实例5: 每个星期一的上午8点到11点的第3和第15分钟执行 |
| 30 21 * * * /etc/init.d/smb restart | 实例6: 每晚的21:30重启smb |
| 45 4 1,10,22 * * /etc/init.d/smb restart | 实例7: 每月1、10、22日的4 : 45重启smb |
| 10 1 * * 6,0 /etc/init.d/smb restart | 实例8:每周六、周日的1 : 10重启smb |
| 0,30 18-23 * * * /etc/init.d/smb restart | 实例9:每天18 : 00至23 : 00之间每隔30分钟重启smb |
SCP远程文件拷贝
scp是 remote file copy program 的缩写
同时开启node01 和 node02 虚拟机
在node01里输入如下命令:
cd /tmp
# 切换到/tmp目录
touch 123.txt
# 创建一个123.txt文件
scp 123.txt hadoop02:/tmp/
# 把当前目录下的123.txt传到hadoop02(192.168.100.202)的/tmp/目录下
这里它会询问hadoop02的root密码
(如果你是第一次往hadoop02传东西,还会问你是否连接,你输入yes回车,就会问你hadoop02的root密码)

输入密码后,传输成功!
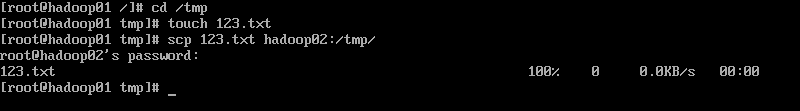
常用的压缩命令
Linux压缩与解压缩
tar z/j cvf 包的名称 [文件名称或路径]
| 参数 | 含义 |
|---|---|
| z/j | 指定解压格式 |
| -c | 创建包 |
| v | 显示详细信息 |
| f | 文件名 |
tar z/jxvf 包名 [-C 解压缩的路径]
| 参数 | 含义 |
|---|---|
| -x | 表示解压 |
| -C | 文件解压后写入的路径 |
| 打包压缩 | 解压缩 |
|---|---|
| tar -zcvf 打包之后的文件名.tar.gz | tar -zxvf 打包之后的文件名.tar.gz [ -c 指定解包位置] |
| tar -jcvf 打包之后的文件名.tar.bz2 | tar -jxvf 打包之后的文件名.tar.bz2 [ -c 指定解包位置] |
| tar -cvf 打包之后的文件名.tar | tar -xvf 打包之后的文件名.tar [ -c 指定解包位置] |
老版本Compress压缩
compress [-dfvcV],[-b maxbits],[文件名称或路径]
参数列表:
| c | 输出结果至标准输出设备(一般指荧幕) |
| f | 强迫写入档案,若目的档已经存在,则会被覆盖 (force) |
| v | 将程序执行的讯息印在荧幕上 (verbose) |
| b | 设定共同字串数的上限,以位元计算,可以设定的值为 9 至 16 bits 。由于值越大,能使用的共同字串就 越多,压缩比例就越大,所以一般使用预设值 16 bits (bits) |
| d | 将压缩档解压缩 |
| V | 列出版本讯息 |
用户、用户组、权限 相关操作
用户组的增删改查
| 添加组 | groupadd 组名 |
| 查看组 | cat /etc/group |
| 删除组 | groupdel 组名 |
| 修改文件所属的组 | chgrp 目标组名 文件/目录 |
创建用户时,若未指定用户所属的组,那么系统会创建一个与用户名相同的组,该用户所属的组与用户名完全相同
用户的增删改查
| 查看当前系统有哪些用户 | cat /etc/passwd |
| 增加用户 | useradd 用户名 |
| 为用户设置密码 | passwd 用户名 + 回车 |
| 查看root用户所属的组 | id root |
| 查看系统登录的用户 | who |
| 查看当前用户 | whoami |
| 删除用户 | userdel |
| 修改用户 | usermod |
用户的相关数据包含如下几项:
用户基本信息:存储在 /etc/passwd 文件中;
用户密码信息:存储在 /etc/shadow 文件中;
用户群组基本信息:存储在 /etc/group 文件中;
用户群组信息信息:存储在 /etc/gshadow 文件中;
用户个人文件:主目录默认位于 /home/用户名,邮箱位于 /var/spool/mail/用户名。
Linux passwd命令
Linux passwd命令用来更改使用者的密码
语法
passwd [-k] [-l] [-u [-f]] [-d] [-S] [username]
参数列表
| -d | 删除密码 |
| -f | 强制执行 |
| -k | 更新只能发送在过期之后 |
| -l | 停止账号使用(锁定) |
| -S | 显示密码信息 |
| -u | 启用已被停止的账户(解锁) |
| -x | 设置密码的有效期 |
| -g | 修改群组密码 |
| -i | 过期后停止用户账号 |
| –help | 显示帮助信息 |
| –version | 显示版本信息 |
如何将用户从一个组中移除?
gpasswd -d userName groupName
usermod的用法
usermod [-LU][-c <备注>][-d <登入目录>][-e <有效期限>][-f <缓冲天数>][-g <群组>][-G <群组>][-l <帐号名称>][-s ][-u ][用户帐号]
| -c<备注> | 修改用户帐号的备注文字。 |
| -d登入目录> | 修改用户登入时的目录。 |
| -e<有效期限> | 修改帐号的有效期限。 |
| -f<缓冲天数> | 修改在密码过期后多少天即关闭该帐号。 |
| -g<群组> | 修改用户所属的群组。 |
| -G<群组> | 修改用户所属的附加群组。(把用户添加到某组) |
| -l<帐号名称> | 修改用户帐号名称。 |
| -L | 锁定用户密码,使密码无效。 |
| -s | 修改用户登入后所使用的shell。 |
| -u | 修改用户ID。 |
| -U | 解除密码锁定。 |
权限介绍
| drwxr-xr-x | 2 root group01 4096 9月 27 12:24 dir1 |
|---|---|
| d | 类型 d为目录 -为文件 |
| rwx | 用户对这个目录或文件的操作权限 |
| r-x | 用户所属的组对这个目录或文件的操作权限 |
| r-x | 其它用户所属对这个目录或文件的操作权限 |
| root | 文件所属的用户 |
| group01 | 文件所属的用户所属的组 |
| 4096 | 文件的大小 |
Linux sudo命令总结
第一步:使用普通用户登陆系统,进入root用户所属的目录创建文件夹001,mkdir001
创建时报错“权限不足”
第二步:临时使用超级管理员权限进行创建。命令:sudo mkdir 001 报错“zhangsan不在sudoers文件中”
第三步:在/etc/sudoers文件中添加zhangsan信息 zhangsan ALL=(ALL) ALL 最后强制保存退出(wq!)
第四步:重新创建目录“sudo mkdir 001”(需要输入zhangsan的密码)
/etc/passwd内容含义

用户名:密码(x表示加密的密码):UID(用户标志):GID(组标志):用户全名或本地账号:家目录:
登录使用的Shell,就是登录之后,使用的终端命令
chmod 777 路径
更改权限
sudo 临时使用管理员权限
Linux输出重定向>和>>区别如下:
>: 会重写文件,如果文件里面有内容会覆盖。
>>这个是将输出内容追加到目标文件中。如果文件不存在,就创建文件。
>>:追加文件,也就是如果文件里面有内容会把新内容追加到文件尾。
> 是定向输出到文件,如果文件不存在,就创建文件;
> 如果文件存在,就将其清空。一般我们备份清理日志文件的时候,
> 就是这种方法:先备份日志,再用`>`,将日志文件清空(文件大小变成0字节)。