Flink官方文档笔记11介绍一下DataStreamAPI
能坚持看到第11篇,那我真的佩服,毕竟我写的稀烂,别急,容我狡辩一下。
先说说我这个Flink官方文档笔记的价值把,省的你们看不下去了。
首先这是最新版的,要学最新版你几乎只能在官网学,第二Flink对于大数据工作者很重要,迟早得学。
第三,现在只是基础的翻译,等我融汇贯通了,这一个系列的笔记我都会重写一遍,重新组织语言,并且用尽可能中文来写,并且尽可能通俗易懂。老铁们我做的对吗?正道的光~~
文章目录
- Intro to the DataStream API 介绍一下DataStreamAPI
- What can be Streamed?什么类型可以被转化为流?
- Java tuples and POJOs Java元组和泡脚类
- Tuples 元组
- POJOs 泡脚类
- Scala tuples and case classes Scala元组和样例类
- A Complete Example 一个完整的例子
- Stream execution environment 流的执行环境
- Basic stream sources 基础的流的数据来源
- Basic stream sinks基本的流的sink
- Debugging 调试错误,改bug
- Hands-on 亲自上手试一试
Intro to the DataStream API 介绍一下DataStreamAPI
The focus of this training is to broadly cover the DataStream API well enough that you will be able to get started writing streaming applications.
此培训的重点是广泛覆盖DataStream API,以便您能够开始编写流媒体应用程序。
What can be Streamed?什么类型可以被转化为流?
Flink’s DataStream APIs for Java and Scala will let you stream anything they can serialize. Flink’s own serializer is used for
Flink为Java和Scala提供的DataStream api将允许您流化任何它们可以序列化的内容。Flink自己的序列化器可以用于以下对象:
basic types, i.e., String, Long, Integer, Boolean, Array
composite types: Tuples, POJOs, and Scala case classes
and Flink falls back to Kryo for other types.
对于其他类型,Flink回落到Kryo。
It is also possible to use other serializers with Flink. Avro, in particular, is well supported.
在Flink中也可以使用其他序列化器。特别是Avro,它得到了很好的支持。
Java tuples and POJOs Java元组和泡脚类
Flink’s native serializer can operate efficiently on tuples and POJOs.
Flink的本机序列化器可以有效地对元组和pojo进行操作。
Tuples 元组
For Java, Flink defines its own Tuple0 thru Tuple25 types.
Tuple2<String, Integer> person = Tuple2.of("Fred", 35);
// zero based index!
String name = person.f0;
Integer age = person.f1;
POJOs 泡脚类
Flink recognizes a data type as a POJO type (and allows “by-name” field referencing) if the following conditions are fulfilled:
如果满足以下条件,Flink将数据类型识别为POJO类型(并允许“by-name”字段引用):
The class is public and standalone (no non-static inner class)
类是公共的和独立的(没有非静态的内部类)
The class has a public no-argument constructor
该类有一个公共无参数构造函数
All non-static, non-transient fields in the class (and all superclasses) are either public (and non-final) or have public getter- and setter- methods that follow the Java beans naming conventions for getters and setters.
类中的所有非静态、非瞬态字段(以及所有超类)要么是公共的(并且是非final的),要么具有公共的getter和setter方法,这些方法遵循Java bean的getter和setter命名约定。
Example:
public class Person {
public String name;
public Integer age;
public Person() {};
public Person(String name, Integer age) {
. . .
};
}
Person person = new Person("Fred Flintstone", 35);
Flink’s serializer supports schema evolution for POJO types.
Flink的序列化器支持POJO类型的模式演化。
Scala tuples and case classes Scala元组和样例类
These work just as you’d expect.
它们会正如你所期望的那样正常运行。
A Complete Example 一个完整的例子
This example takes a stream of records about people as input, and filters it to only include the adults.
这个示例将关于人员的记录流作为输入,并过滤它以只包括成年人。
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.api.common.functions.FilterFunction;
public class Example {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Person> flintstones = env.fromElements(
new Person("Fred", 35),
new Person("Wilma", 35),
new Person("Pebbles", 2));
DataStream<Person> adults = flintstones.filter(new FilterFunction<Person>() {
@Override
public boolean filter(Person person) throws Exception {
return person.age >= 18;
}
});
adults.print();
env.execute();
}
public static class Person {
public String name;
public Integer age;
public Person() {};
public Person(String name, Integer age) {
this.name = name;
this.age = age;
};
public String toString() {
return this.name.toString() + ": age " + this.age.toString();
};
}
}
Stream execution environment 流的执行环境
Every Flink application needs an execution environment, env in this example. Streaming applications need to use a StreamExecutionEnvironment.
每个Flink应用都需要一个执行环境,在这个例子里的环境,流应用需要使用一个StreamExecutionEnvironment。
The DataStream API calls made in your application build a job graph that is attached to the StreamExecutionEnvironment.
在应用程序中进行的DataStream API调用将构建一个附加到StreamExecutionEnvironment的作业图。
When env.execute() is called this graph is packaged up and sent to the JobManager, which parallelizes the job and distributes slices of it to the Task Managers for execution.
当调用env.execute()时,此图被打包并发送到JobManager,后者将作业并行化,并将作业的各个部分分发给任务管理器执行。
Each parallel slice of your job will be executed in a task slot.
作业的每个并行切片都将在一个任务槽(TaskSlot)中执行。
Note that if you don’t call execute(), your application won’t be run.
注意,如果你不调用execute()方法,你的应用就跑不起来。
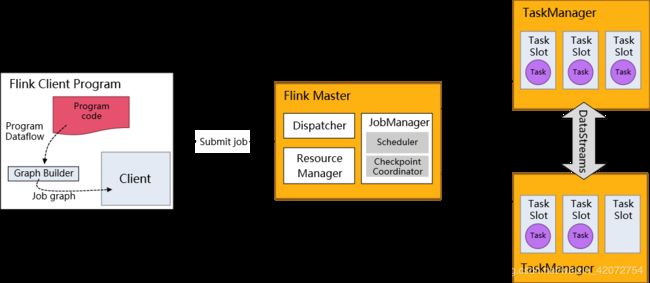
This distributed runtime depends on your application being serializable.
这个分布式运行时取决于您的应用程序是否可序列化。
It also requires that all dependencies are available to each node in the cluster.
它还要求集群中的每个节点都可以使用所有依赖项。
Basic stream sources 基础的流的数据来源
The example above constructs a DataStream using env.fromElements(...). This is a convenient way to throw together a simple stream for use in a prototype or test.
上面的例子使用env.fromElements(…)构造了一个DataStream。这是在原型或测试中创建简单流的一种方便方法。
There is also a fromCollection(Collection) method on StreamExecutionEnvironment. So instead, you could do this:
StreamExecutionEnvironment上还有一个fromCollection(Collection)方法。所以,你也可以这样做:
List<Person> people = new ArrayList<Person>();
people.add(new Person("Fred", 35));
people.add(new Person("Wilma", 35));
people.add(new Person("Pebbles", 2));
DataStream<Person> flintstones = env.fromCollection(people);
Another convenient way to get some data into a stream while prototyping is to use a socket
在原型设计时,另一种方便的方法是使用socket监听端口来获取数据
DataStream<String> lines = env.socketTextStream("localhost", 9999)
or a file
或者是从文件获取数据
DataStream<String> lines = env.readTextFile("file:///path");
In real applications the most commonly used data sources are those that support low-latency, high throughput parallel reads in combination with rewind and replay – the prerequisites for high performance and fault tolerance – such as Apache Kafka, Kinesis, and various filesystems.
在真实的应用程序中,最常用的数据源是那些支持低延迟、高吞吐量并行读并支持倒带和重放(高性能和容错的先决条件)的数据源,比如Apache Kafka、Kinesis和各种文件系统。
REST APIs and databases are also frequently used for stream enrichment.
REST api和数据库也经常用于充实流。
Basic stream sinks基本的流的sink
The example above uses adults.print() to print its results to the task manager logs (which will appear in your IDE’s console, when running in an IDE).
上面的示例使用adult .print()将结果打印到任务管理器日志(当在IDE中运行时,它将出现在IDE的控制台)。
This will call toString() on each element of the stream.
这将在流的每个元素上调用toString()。
The output looks something like this
输出看起来是这样的
1> Fred: age 35
2> Wilma: age 35
where 1> and 2> indicate which sub-task (i.e., thread) produced the output.
其中1>和2>表示哪个子任务(即(线程)生成输出。
In production, commonly used sinks include the StreamingFileSink, various databases, and several pub-sub systems.
在生产中,常用的接收器包括StreamingFileSink、各种数据库或者几个pub-sub系统。
Debugging 调试错误,改bug
In production, your application will run in a remote cluster or set of containers. And if it fails, it will fail remotely.
在生产环境中,您的应用程序将运行在远程集群或一组容器中。如果它失败了,它将远程失败。
The JobManager and TaskManager logs can be very helpful in debugging such failures, but it is much easier to do local debugging inside an IDE, which is something that Flink supports. You can set breakpoints, examine local variables, and step through your code.
JobManager和TaskManager日志在调试此类故障时非常有用,但在IDE中进行本地调试要容易得多,这是Flink支持的。您可以设置断点、检查本地变量和单步执行代码。
(出bug了可以在idea设断点调,或者看日志文件找错)
You can also step into Flink’s code, which can be a great way to learn more about its internals if you are curious to see how Flink works.
您还可以深入了解Flink的源代码,如果您想了解Flink是如何工作的,那么这是了解其内部内容的好方法。
(去github上啃源代码,放心,Flink用的多了你迟早得看源码,毕竟有时候源码就是看了凉的明白,不看怎么凉的都不知道)
Hands-on 亲自上手试一试
At this point you know enough to get started coding and running a simple DataStream application.
至此,您已经了解了足够的知识,可以开始编写和运行一个简单的DataStream应用程序了。
Clone the flink-training repo, and after following the instructions in the README, do the first exercise: Filtering a Stream (Ride Cleansing).
克隆flink-training repo,并按照README中的说明执行第一个练习:过滤流(骑行清理)。
就是你可以跑一下github上源码里自带的小案例,来体验一下Flink!