关于数据统计
前言
当我们拿到一批数据的时候,除了明确目的、方法。更重要的是对数据进行分析,只有分析清楚数据的特点,才能选择合适的处理方法以得到合适的数据集feed the network.
相关资料:
1.dicom数据处理示例
https://www.kaggle.com/akh64bit/full-preprocessing-tutorial
2.文档读取写入
(1)pandas 库
(2)xlrd、xlwt
1.文档的读取与写入
(1)安装必须的第三方库:
pip install xlrd
pip install xlwt
(2)示例code
def write_file(data,column):
book = xlwt.Workbook('excelfile.xls') # 创建Workbook,相当于创建Excel,若有原数据会被覆盖
# 创建sheet,Sheet1为表的名字,cell_overwrite_ok为是否覆盖单元格
sheet1 = book.add_sheet(u'SA', cell_overwrite_ok=True)
r = 1
for item in data1: # i表示data中的key,j表示data中的value
sheet1.write(r,column,item[0])
sheet1.write(r, column+1, item[1])
r += 1 # 行数
book.save("excelfile.xls")
2.结合上篇pandas的处理直接对数据处理
#读取txt
data_txt= pd.read_csv('presidential_polls.txt',sep='\t')
print(data_txt)
#按照字段分组.得到一个分组对象
state=data_txt.groupby('state').mean()
#获取所有分组字典
print(state)
#导出数据到Excel文件
# writer=pd.ExcelWriter("presidential_polls_trump_state_mean.xlsx", engine='xlsxwriter')
# state.to_excel(writer,"Sheet1")
# writer.save()
可以存入字典中,然后调用plt绘制直方图
name_list=[“1”,“2”,“3”]
num_list=[4,5,6]
plt.bar(range(len(num_list)), num_list,color='rgb',tick_label=name_list)
plt.show()
3.手写一个统计的代码
if A[0]:
img_shape = np.array(A[2][0][-1])[0].shape
pixelspacing = np.array(A[2][0][-1])[2]
pixelspacing_list.append(pixelspacing)
img_shape_list.append(img_shape)
i = 0
# 统计像素
if not unique_pixel:
unique_pixel.append([pixelspacing[0]])
if not dic_pix:
dic_pix.setdefault(pixelspacing[0])
for item in unique_pixel:
if pixelspacing[0] != item[0]:
i = i + 1
if pixelspacing[0] == item[0]:
if dic_pix.get(pixelspacing[0]):
dic_pix.update({pixelspacing[0]: dic_pix.get(pixelspacing[0]) + 1})
else:
dic_pix.update({pixelspacing[0]: 1})
if i == len(unique_pixel):
unique_pixel.append([pixelspacing[0]])
dic_pix.setdefault(pixelspacing[0])
注意
1.python变量名相当于标签名
list2 = list1, 直接赋值,实质上指向的是同一个内存值。任意一个变量(list1 or list2)发生改变,都会影响另外一个
>>> list1=[1,2,3,4,5,6]
>>> list2=list1
>>> list1[2]=88
>>> list1
[1, 2, 88, 4, 5, 6]
>>> list2
[1, 2, 88, 4, 5, 6]
2.array类型的数据进行拷贝时,和list类型有一点区别。
(1)直接 “ = ”
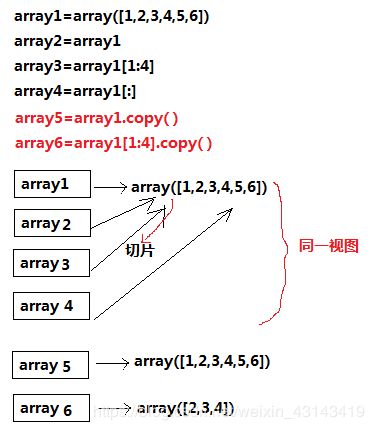
数组切片是原始数组的视图,这意味着数据不会被复制,视图上的任何修改都会被直接反映到源数组上。array1, array2, array3, array4实际指向同一个内存值,任意修改其中的一个变量,其他变量值都会被修改。
(2)若想要得到的是array切片的一份副本而非视图,就需要显式的进行复制操作函数copy()。
array5 = array1.copy() # 对原始的array1的复制
array6 = array[1:4].copy() # 对切片array[1:4]的复制
那么,修改array5或array6,就不会影响array1