【计算机基础】Unicode字符集 与 多字节字符集
=======================事情是这样的==========================
在调试某程序时,发生了这样的错误:
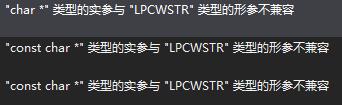
char 与 LPCWSTR 类型不兼容
搜索了一下发现是字符集的原因。
项目>>属性>>字符集>>使用多字节字符集
或者,每个字符串“xxxxx”改为_T("xxxxx"),char类型改为wchar_t 或者 LPCSTR
即可解决。
于是深入探究一下字符集的相关
=======================以下正文==============================
计算机中每一个字符都是由编码表示的。
我们最熟悉的 ASCII码:
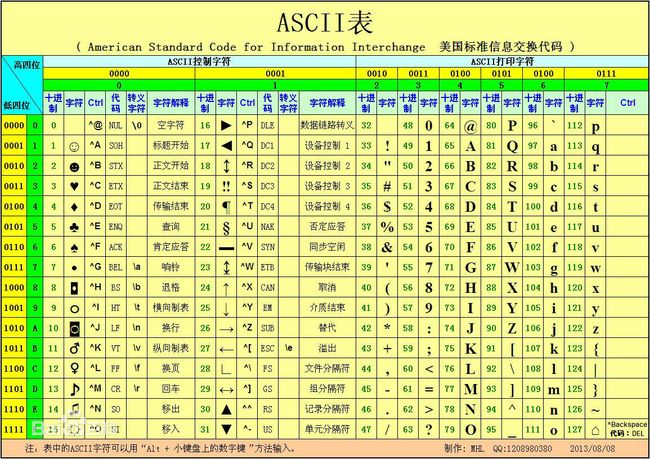
全称:American Standard Code for Information Interchange 美国标准信息交换代码
(一直以为是II是罗马数字2……)
该代码是由是由美国国家标准学会(American National Standard Institute , ANSI )制定的
后来,又进行了扩展,由最初的7位128个字符扩展到8位256个字符:
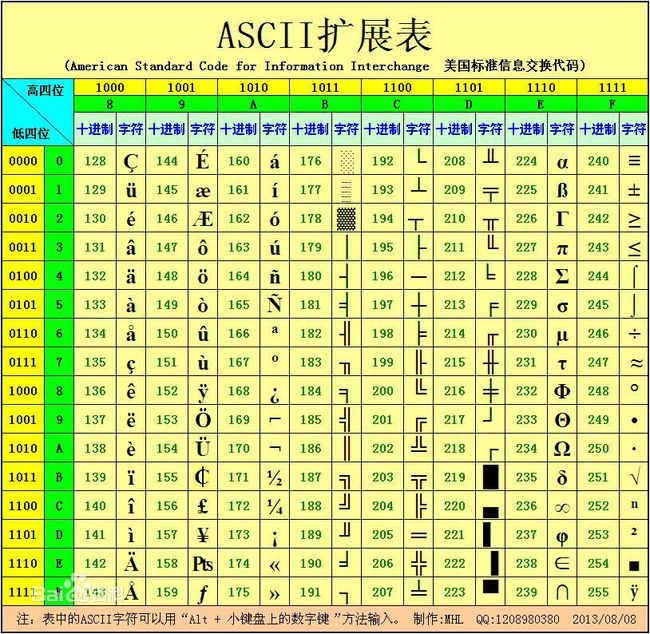
再后来,又有其他国家文字的加入,各国都需要有自己的字符集。
于是他们在ASCII的基础上,制定了自己的字符集,这些由ASCII派生出来的字符集都成为ASCI字符集,(这些字符集都是以7位128个字符的ASCII为基础)
正式的名称:MBCS(Multi-Byte Chactacter System,即多字节字符系统)
最常见的GB_2312就是其中之一。
以GB_2312为例:
GB_2312收录简化汉字及一般符号、序号、数字、拉丁字母、日文假名、希腊字母、俄文字母、汉语拼音符号、汉语注音字母,共7445个图形字符。其中包括6763个汉字,其中一级汉字3755个,二级汉字3008个;包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个全角字符。
(科普:汉字大概6800个)
所谓 多字节字符集 的精髓就是,用多个字节的组合来表示代码。
例如:“连通”两个字的编码为:C1 AC CD A8
C1 AC 表示 “连”,
C1为leading byte 引导字节,可以理解为“区号”,当leading byte 小于128时,自动作为ASCII码进行处理。
AC为实际编码字节,可以理解为“位号”
分区表示:
GB_2312中对所收汉字进行了“分区”处理,每区含有94个汉字/符号。这种表示方式也称为区位码。
各区包含的字符如下:01-09区为特殊符号;16-55区为一级汉字,按拼音排序;56-87区为二级汉字,按部首/笔画排序;10-15区及88-94区则未有编码。
双字节表示
两个字节中前面的字节为第一字节,后面的字节为第二字节。习惯上称第一字节为“高字节”,而称第二字节为“低字节”。
“高位字节”使用了0xA1-0xF7(把01-87区的区号加上0xA0),“低位字节”使用了0xA1-0xFE(把01-94加上0xA0)。
以GB2312字符集的第一个汉字“啊”字为例,它的区号16,位号01,则区位码是1601,在大多数计算机程序中,高字节和低字节分别加0xA0得到程序的汉字处理编码0xB0A1。计算公式是:0xB0=0xA0+16,0xA1=0xA0+1。
==========================================================
然而,由于每种语言都制定了自己的字符集,导致最后存在的各种字符集实在太多,在国际交流中要经常转换字符集非常不便。
Unicode就诞生了。
Unicode(统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。
Unicode是一个编码方案。
从0到一个很大很大的数,每个数表示人类的一个字符,这样的映射组成的一个集合,就是——通用字符集(Universal Character Set, UCS)
???很大很大的数是多少???
0x0000 至 0x10FFFF
目前Unicode字符分为17组,也称17个平面,每个平面有2^16=65536个码位,一共有17*65536=1114112个。
写成十六进制:
0x00 0x00 0x00 0x00 ———— 0x00 0x10 0xFF 0xFF
前两个为高位字节从0x0000到0x0010共有17个数,表示17个平面。
低位两个字节表示每个平面的码位。
???什么是UCS-2和UCS-4???
2和4表示所占字节数。
平面0被称作BMP(Basic Multilingual Plane)——基础多语言平面。
范围是:
0x00 0x00 0x00 0x00 ———— 0x00 0x00 0xFF 0xFF
发现前两个字节全都是0,于是拿掉他们,就成了只占2个字节的字符集:
0x00 0x00 ———— 0xFF 0xFF
???人类已经定义了多少字符???
在Unicode 5.0.0版本中,已定义的码位只有238605个,分布在平面0、平面1、平面2、平面14、平面15、平面16。
其中平面15和16上只是定义了两个各占65534个码位的专用区PUA(Private Use Area),分别是0xF0000-0xFFFFD和0x100000-0x10FFFD。
所谓专用区,就是保留给大家放自定义字符的区域。
举个栗子:
3 0x0051
届 0x5c4a
N 0x004e
B 0x0042
A 0x0041
冠 0x51a0
军 0x519b
转换成二进制:
3 0000 0000 0101 0001
届 0101 1100 0100 1010
N 0000 0000 0100 1110
B 0000 0000 0100 0010
A 0000 0000 0100 0001
冠 0101 0001 1010 0000
军 0101 0001 1001 1011
这样计算机在读取的时候会出现一些问题。
当以字节为单位读取的时候,结果就变成了:
3 \ J N B A 3 3
因为,对于一些字符,双字节组合在一起才能准确表示映射关系,单字节读取会导致映射错乱。
然而,当以双字节为单位读取的时候,发现数字和字母的前一个字节全都是0!
这是对资源的浪费。
如何才能避免?
首先想到就是对字符集进行分段处理,数字小的只取后两位,数字大的再取高位的数,最后用统一的格式写出。
这就是:
UTF(Unicode Transformation Format)—— Unicode字符集转换格式。
UTF分为UTF-8 , UTF-16 , UTF-32 这几种类型,8、16、32这几个数字分别代表,以多少个二进制位为一个单位。
==========================================================
UTF-8:
UTF-8 以一个字节为单位。
分段表示如下:

右边可以理解为一种模板,将数字转换为二进制,再拆分填入模板的x中。
3 0000 0000 0101 0001 >>>> 0101 0001
届 0101 1100 0100 1010 >>>> 1110 0101 1011 0001 1000 1010
N 0000 0000 0100 1110 >>>> 0100 1110
B 0000 0000 0100 0010 >>>> 0100 0010
A 0000 0000 0100 0001 >>>> 0100 0001
冠 0101 0001 1010 0000 >>>> 1110 0101 1000 0110 1010 0000
军 0101 0001 1001 1011 >>>> 1110 0101 1000 0110 1001 1011
所占空间由原来的14个字节变成了13个字节。
当然占空间不是最主要的原因,这里举得例子也是具有一定的特殊性。
如果全是汉字,那么UTF-8所占空间并没有多大的优势。
然而可以发现,以这样的格式改写之后,在以单字节为单位读取的时候,每个字节的前几位都有固定的数字,计算机可以更加精确的识别。
这是最主要的原因。
这也是UTF最主要的作用。
==========================================================
UTF-16:
UTF-16则是以两个字节为单位进行读取,需要满足如下的格式:
| Unicode编码(十六进制) | UTF-16字节流(二进制) |
| 0000 0000 - 0000 FFFF | xxxx xxxx xxxx xxxx |
| 0001 0000 - 0010 FFFF | 1101 10yy yyyy yyyy 1101 11zz zzzz zzzz |
具体规则:
令Unicode编码为U,
当 U <= 0x 0000 FFFF 时,其UTF-16形式就是U的二进制型。
当 0x 0000 FFFF < U <= 0x 0010 FFFF时,设U' = U - 0x 0001 0000,再将U' 写成二进制型 yyyy yyyy yyzz zzzz zzzz,最后填入格式中。
按照上述规则,Unicode编码0x10000-0x10FFFF的UTF-16编码有两个字(一个字是两个字节,16位)
第一个字的高6位是110110,第二个字的高6位是110111。
可见,
第一个字的取值范围(二进制)是1101 1000 0000 0000 到1101 1011 1111 1111,即0xD800-0xDBFF。
第二个字的取值范围(二进制)是1101 1100 0000 0000 到1101 1111 1111 1111,即0xDC00-0xDFFF。
在UTF-16规则下,有的字符是一个字,有的字符是两个字。
一个字的取值范围是0x0000 - 0xFFFF
在这当中,0xD800 - 0xDFFF 这一区域是两个字协同表示字符的。
于是将他们保留下来,作为代理区。
0xD800-0xDBFF 为 高位替代。
0xDC00-0xDFFF 为 低位替代。
前文说道。
平面15和平面16为专用区PUA,范围是0xF0000-0xFFFFD和0x100000-0x10FFFD。
补上0xFFFFF和0x10FFFF,两个特殊编码之后,
编码范围即:
0xF0000 - 0x10FFFF
带入UTF-16的规则中,得到
U'=U-0x10000:
0xE0000 - 0xFFFFF
转换为二进制:
1110 0000 0000 0000 0000 - 1111 1111 1111 1111 1111
加入引导位:
1101 1011 1000 0000,1101 1100 0000 0000 --- 1101 1011 1111 1111, 1101 1111 1111 1111
转换为十六进制:
0xDB80,0xDC00 --- 0xDBFF,0xDFFF
其高位替代的范围是:
0xDB80 - 0xDBFF
这个区域是专用区,因此该代理区叫做——高位专用替代

==========================================================
UTF-32:
UTF-32是以4个字节为单位进行读取。
这就非常简单粗暴了。
因为Unicode编码最大值为0x10FFFF,拆成四个字节就是 00 10 FF FF,
所以,忽略占空间的影响,每个编码都可以拆成4个字节的形式,并且编码与字符一一映射。
需要注意的是:
字节序,多字节数据在计算机中存储或传输的数据。
分为两种,“大端”(Big Endian, BE)和“小端”(Little Endian, LE)(源于《格列佛游记》中鸡蛋的大头还是小头)
Little Endian:将低序字节存储在起始地址
Big Endian: 将高序字节存储在起始地址
0x10FFFF的大端BE表示法: 00 10 FF FF
0x10FFFF的小端LE表示法: FF FF 10 00
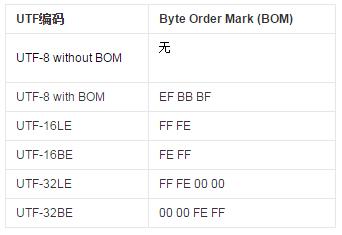
Unicode标准建议用BOM(Byte Order Mark)来区分字节序,即在传输字节流前,先传输被作为BOM的字符“零宽无中断空格”。
==========================总结===================================
在很久很久以前,有一群机智的美国人发明了ASCII码,把英文字母和常用标点都用数字表示出来了。
后来其他种族也想效仿,但是他们的文字太多了,于是这些高智慧种族在ASCII码的基础上,发明了一个区位码的概念。
用两个字节来表示一个字符。前一个字节为区号,后一个字节为位号。这就是多字节字符集。
渐渐地,这座星球上的各个种族纷纷建立了自己的字符集标准,世界一片欣欣向荣。
忽然有一天,某操作系统公司的程序猿终于死在了各国字符集标准相互转换的路上。
这一死,给这个星球上的生物敲响了警钟,这时忽然有一个声音从天空中飘来——
“我们星球需要一个统一的标准!”
于是universal code 诞生了!后来人们就叫他Unicode。
既然有辣么多的字符需要表示,那我们就把存储空间放大嘛!一个字节不够用两个,两个字节不够用四个!
传输数据的时候,我一个字节一个字节给你,就用UTF-8标准,两个两个给你就用UTF-16标准,4个4个给你就用utf-32标准。
机智的地球人效仿了区位码的概念,给每个字节的开头加了个帽子,让编码看起来很统一,110110xxxxxxxxxx,110111xxxxxxxxxx……
一看帽子就知道这个代码来自于哪里。
经过不断地完善,Unicode字符集编码方案就成了现在的样子。
=========================参考==================================
《Unicode字符集和多字节字符集关系》
http://blog.csdn.net/stephen1315/article/details/7476236
《Big Endian和Little Endian的区别 》
http://blog.chinaunix.net/uid-479984-id-2114895.html
百度百科:Unicode
http://baike.baidu.com/link?url=YBucaohEYmhdERJolWN65Nj9GAizuI27uabIClvHDL8kF0_Ev8OX0OPUgL87sZ4iKBWE15jihIjeHNXig3365K#4_1
知乎问题:《Unicode 和 UTF-8 有何区别?》
http://www.zhihu.com/question/23374078
百度百科:ASCII
http://baike.baidu.com/link?url=8i94jsXps5a4696lex0TehG4n3bFkAtn2Xi5jUbYZVn2JJWSnRGkV49-oKJoVoCnINK1nmnk_ADpBWsGL70wkK
百度百科:ANSI
http://baike.baidu.com/subview/185282/6215666.htm#viewPageContent
百度百科:字节序
http://baike.baidu.com/link?url=Viu2Tt3dwUWj9XxlHXBcl0cVqXuDd63XlEDDhS5Iks2Nti8fi5Cn6zUwOYIF6lbJN_ceGFm9dDgZ8nvlEBZeka