1000+节点:kubernetes 1.2性能和可扩展性更新介绍
原文链接
编者注:这是 Kubernetes 1.2 中的新功能介绍系列文章中的第一篇。
我们自豪地宣布的,kubernetes 1.2 版本现在可以支持1000+节点的群集,同时99%的API减少了 80%的访问延迟。这意味着仅仅六个月,在不影响用户体验的情况下,我们提升了10倍的性能 -- 99%的 pod 启动时间小于 3 秒,并且99%的 API操作延迟仅有几十毫秒(在超大集群中,LIST操作是个例外,大概需要花费几百毫秒)。
言语苍白,眼见为证,请看视频(译者注:需要,你懂地):
https://youtu.be/9C6YeyyUUmI
在上面的视频中,你看到在1000个节点规模的群集上,集群访问逐步增加到100K次查询(QPS),包括rolling update请求在内,而没有宕机、没有任何延迟。这种情况已经足以应付互联网排名前100位网站的访问量了。
在这篇博客,我们会介绍达到这样的成果我们所做的工作,并且讨论我们未来支持更大规模集群的计划。
测试方法
我们针对如下的服务等级目标来对Kubernetes的可扩展性进行基准测试:- API响应率:99%的API调用返回时间小于1s
- Pod启动时间:99%的pod和其中的容器(镜像已经缓存到本地)启动时间在5面以内
仅当全部满足这些服务等级目标的情况下,我们才声称kubernetes可以支持特定数量结点的集群。我们会不断的收集和报告上述测量数据,这也是整个项目测试框架的一部分。这一系列的测试分为2部分:API响应能力和Pod启动时间。
用户级别抽象API的响应能力
Kubernetes为用户表述他们的应用提供了高层次的抽象。例如,ReplicationController(复制控制器,后文全部使用英文)代表了一批pod的抽象。罗列所有的ReplicationControllers或者是从指定的ReplicationController罗列所有的pod是一个很常见的用例。相反的,没有人有很强烈的原因需要罗列出系统中所有的POD。例如,30000个pod(1000个节点,每个节点里有30个pod)代表了大约150MB的数据(~50kb/pod * 30k)。因此,本次测试使用ReplicationControllers。
本次测试(假定N是集群中的节点数量),我们:
1.创建大约数量为3xN并且有着不用大小的ReplicationControllers(5个,30个和250个副本),总和30xN个副本。我们按顺序来创建他们(例如,我们不是一次性启动它们)然后等待所有副本的状态都变成运行状态。
- 在每一个ReplicationController上执行一些操作(例如,扩展ReplicationController、列出ReplicationController中的所有实例等等),测量每一个操作的延迟时间。这和真实用户在正常集群操作的过程类似。
- 停止并删除系统中所有的ReplicationControllers
本次测试的结果请参见"Kubernetes 1.2 指标"一节。
在v1.3版本中,我们计划扩展这个测试,添加一些新的测试内容,包括创建Services, 部署Deployments, DaemonSets, 其它一些API对象。
Pod启动端到端延迟
用户对Kubernetes花费多少时间来调度和启动一个pod也很关心。它体现在两个方面:初始创建和如果当pod所在主机宕机后,replicationController需要创建一个新的pod来替代。本次测试(假定N为集群中的节点数量),我们:
- 创建一个副本数为30×N的ReplicatiionController,然后等待所有副本的状态都变成Running。我们同时还做了运行更高密度的测试,副本数为100×N,不过是在一个节点数比较少的集群中。
- 每隔200毫秒,创建一个单pod的ReplicationController。对每个ReplicationController,我们都会测算“总的端到端启动时间”(其定义参见下文)。
- 关闭并删除系统中的所有pod和ReplicationController。
我们是这么定义的“总的端到端启动时间”的,它从客户端向API服务器发送创建ReplicationController的时刻开始,到客户端监听到pod的状态变为“running & ready”的时刻。这意味着,“pod启动时间”包括了ReplicationController的创建,RC依次创建pod,调度器调度pod,Kubernetes为pod设置网络,启动容器,等待容器成功响应健康检查,并最终等待容器将其状态上报回API服务器,最后API服务器将pod的状态报告给正在监听中的客户端。
虽然我们可以通过一些方式来显著地减少“pod启动时间”,比如说,刨除客户端监听pod状态消耗的时间,或者直接创建pod而非使用ReplicationController来创建pod。但我们相信目前定义的“pod启动时间”符合大多数真实场景的广义定义,这样用户才能更好地了解系统的性能标准。
Kubernetes 1.2 的指标
那么,结果是什么呢?我们在Google Compute Engine上进行测试,基于 Kubernetes 群集规模设置master节点规格。对于1000个节点的群集我们使用 n1-standard-32规格的虚拟机作为master节点(32核,120GB内存)。API 的响应能力
下面两个图表呈现Kubernetes 1.2和kubernetes1.0在100个节点的集群中99%的API调用延迟统计。(柱形图越低表示延迟越小)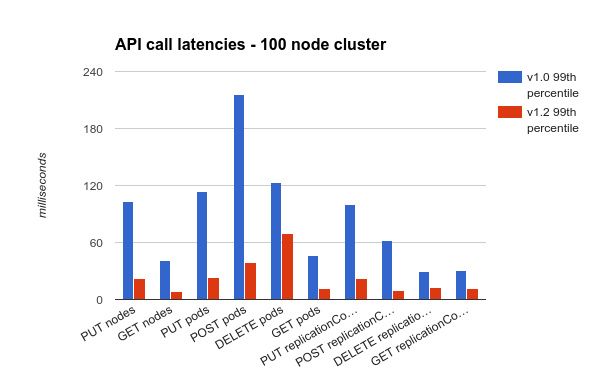
我们把LIST操作结果单列出来,因为LIST操作延迟很高。注意,我们稍微的修改了些我们的测试,当前的测试在kubernetes v1.0上会产生比它们之前更高的延迟。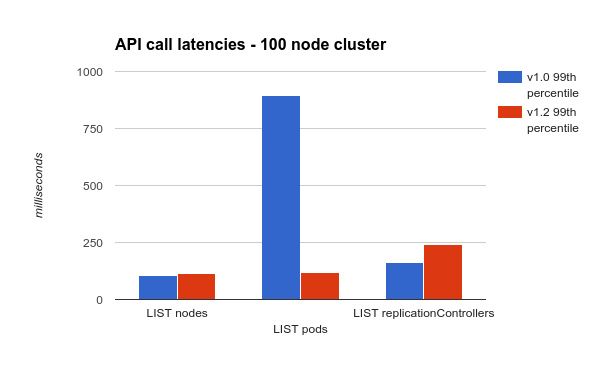
我们也在1000个节点的集群中进行了测试。需要注意的是,GKE(Google容器引擎)环境不支持群集大小超过 100,所以我们无法对这两个的指标进行比较。不过,实际上,从kubernetes 1.0开始,已经有客户在运行超过1000+结点的集群。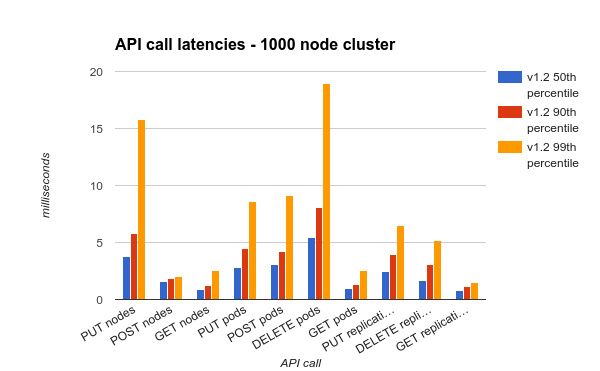
由于LIST操作延迟非常大,我们还是把LIST操作单独显现出来。可以看到所有的请求延迟都可以控制在1秒以内。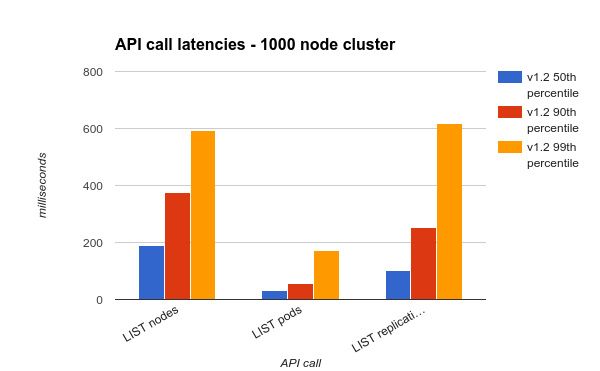
Pod 启动延迟
"Pod启动延迟“(启动延迟的定义见“POD启动端到端延迟”一节)的测试结果见下图。我们也把kubernertes1.0在100 个节点群集规模的测试结果放在一起比较。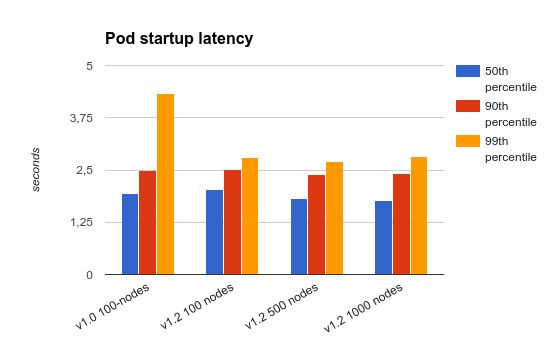
如图上显示的,在100 个节点的群集上测试,kubernetes1.2极大地降低了延迟时间,即使在1000个节点的集群上测试,测试结果一样十分优秀。综上所述, API请求延迟和 pod启动延迟,比六个月前kubernetes1.1在100个节点集群上测试结果要好得多。
我们是如何完成这些性能提升的?
在过去的6个月时间里,为了在性能和扩展性方面取得这些重要的收获,我们对整个系统做了很多的改进。一些重要的改进,罗列如下:- 在API服务器层面,创建“读缓存”
(https://github.com/kubernetes/ ... 15945 )
由于大部分的kubernetes控制逻辑是作用在有序的由ETCD监听器持继更新的一致的数据快照上面的,所以轻微的数据方面的延迟并不影响集群操作的准确性。这些独立的控制逻辑,为系统可扩展性而做的分布式的设计,乐于增加一点延迟,但却带来系统总体吞吐量上面的提升。
在kubernetes 1.2中,我们就是利用这个特性,通过添加一个API服务器读缓存来提升性能和扩展性。有了这个特性,API服务的Client可以直接读取内存中的数据,而不必再每次读取ETCD中存储的数据。缓存中的数据通过ETCD的监听器在后台来更新。这些有接收数据延迟敏感的Client(通常高速缓存的延迟是10几毫秒量级),可能完全通过缓存数据来提供响应,减少从ETCD加载数据的负担,同时提高服务器的吞吐量。这个优化从v1.1版本已经开始了,当时我们添加了直接通过API服务而不是ETCD来提供监听的功能。详情参见:https://github.com/kubernetes/ ... h.md.
感谢来自于google的Wojciech Tyczynski,来自于Redhat的Clayton Coleman和Timothy St. Clair。有他们的支持,我们才通过合适的设计,利用了ETCD独特的优势,来提升kubernetes扩展性和性能。 - Introduce a “Pod Lifecycle Event Generator” (PLEG) in the Kubelet
(https://github.com/kubernetes/ ... tor.md) - 在kubelet中引入“Pod生命周期事件生成器(PLEG)
(https://github.com/kubernetes/ ... tor.md)
kubernetes 1.2同时提升了服务器上POD的密度。从1.2开始,我们测试并建议在单一结点上创建最多100个POD(相比1.1的30个POD)。这个成就归功于社区努力工作实现的POD生命周期事件生成器(PLEG)。
kubelet(kubernetes的结点代理)有一个线程专门负责管理POD的生命周期。在之前的实现中,这个线程定期的扫描底层的容器引擎(Docker)来探测容器状态变化,并执行一些必要的运作来保证结点处于期望的状态(例如,启动或者停止容器)。随着POD密度的提高,并发的扫描会干扰到Docker的工作,导致严重的可靠性和性能问题(包括额外的CPU使用,这也是向上扩张的一个限制因素)
为解决这个问题,我们引入了一个新的kubelet子模块 - PLEG - 来集中处理状态变化探测和生成生命周期事件。随着并发扫描的消除,我们可以减低kubelet的CPU使用率并且4倍的提高容器数量。这也允许我们使用更低的扫描周期,从而更快的探测状态变化并做出反馈。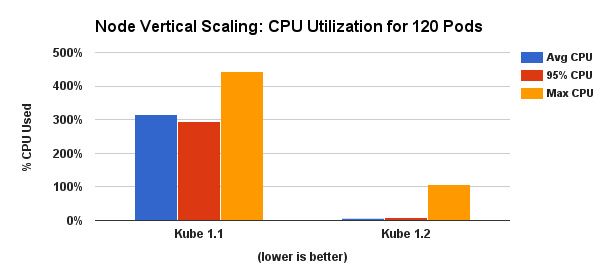
- 提高调度吞吐量 来自CoreOS的kubernetes社区成员(Hongchao Deng和Xiang Li)帮助我们更深入的进入kubernetes的调度并且神奇的提高了吞吐量却没有牺牲准确性或灵活性。他们将调度30000POD的时间总体降低了1400%!你可阅读这个篇非常棒的博客来了解他们是怎么做到的。https://coreos.com/blog/improv ... .html
- 更高效的JSON解析器 Go语言的标准库中包括了一个灵活而且易用的JSON解析器。它可以通过反射API编码或者解析任何Go语言的struct结构。但是灵活带来的代价是反射分配了大量小对象,这些小对象都需要被runtine跟踪并回收。我们的测试表明,无论服务器端还是客户端都花费了大量的时候在序列化上。基于我们的对象类型并不是经常变动,我们感觉通过代码生成可以避免大量的反射。
在调研了Go语言的JSON和做了一些初步的测试后,我们发现ugorji codec库提供了可观的速度提升 - 大概200%的提升在编码和解码JSON时,如果使用生成的序列器,同时有显著的对象分配降低。在向ugorji的主干提交了一些修复以解决我们的复杂结构编解码问题后,我们切换了kubernetes和go-etcd client的JSON解析器。结合一些其它在JSON层面上或下的优化后,我们削减了几乎所有API操作的CPU使用时间,特别是读操作。 - 其它一些导致显著提升的变化,包括:
- 减少断掉TCP连接的数量。这些连接可能引发不必要的新TLS会话:
https://github.com/kubernetes/ ... 15664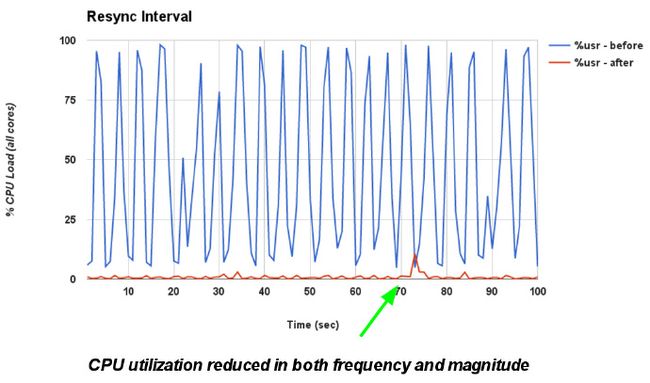
- 提高复制控制器(RC)在大集群中的性能
https://github.com/kubernetes/ ... 21672
这两种情况下的问题,都是由kubernetes社区成员发现并解决的,他们是Andy Goldstein and Jordan Liggitt来自Red Hat, Liang Mingqiang 来自网易.
- 减少断掉TCP连接的数量。这些连接可能引发不必要的新TLS会话:
Kubernetes 1.3及以后
当然,革命尚未成功,同志仍需努力。我们将继续努力来改善kubernetes的性能,我们希望kubernetes能够像google borge系统一样,将规模扩展到几千上万个节点。基于在测试基础设施的大量投入,以及容器在生产环节的使用的持续关注, 我们已经识别出了在提高规模方面的下步工作计划。关于kubernetes 1.3:
- 我们的主要瓶颈仍然是API服务,因为编码和解码JSON对象需要花费大部分时间。我们计划对API增加protocol buffers的支持,这样在组件间通信以及在etcd存储目标时,可以作为一个可选路径。用户仍然可以使用JSON 与API服务器进行通信,但由于绝大多数Kubernetes通信是集群内(API服务器与节点间,调度器与API服务器间等),我们希望Master上的CPU和内存使用率能显著减小。
- Kubernetes使用标签来标识对象集合;例如,要识别属于特定ReplicationController的pods,需要遍历在一个名称空间内的所有pods,然后选择与控制器的标签选择器匹配的pods。为标签添加一个高效的索引,即能利用现有API对象缓存的优势,又能够迅速找到匹配标签选择器的对象,这可以让这种经常性操作变快更多。
- 调度决策取决于一堆不同的因素,包括基于资源请求的pods调度,调度有相同选择器的pods(例如,来自相同的服务,ReplicationController,Job等),节点上需要存在容器镜像等等。这些计算,特别是在特定选择器调度方面,还有许多改进的机会。https://github.com/kubernetes/ ... 22262 可以看到至少一个提升建议。
- 我们非常期待etcd V3.0,它内建了一些kubernetes的用例,既提高了性能,同时引入了新的特性。来自CoreOS贡献者已经开始为Kubernetes到etcd v3.0的转变奠定基础了(详情请看https://github.com/kubernetes/ ... 22604)。
虽然以上列表并没有列出全部为了性能所做的努力,我们仍然对实现显著的性能改善持有乐观态度,正如kubernetes1.0到2.0的性能提升。
总结
在过去的六个月中,我们已经显著改善了Kubernetes的可扩展性,v1.2版本在运行1000个节点的集群中,已经具备了和之前在小集群中同样出色的响应速度(用我们的SLOs来衡量)。但是这还不够,我们希望让Kubernetes更进一步发展和运行的更快。Kubernetes v1.3将进一步提高系统的可扩展性和系统的响应速度,同时继续增加功能,使其更易于构建和运行基于容器理念设计的应用程序。请加入我们的社区,帮助我们建立Kubernetes的未来!现在有很多种方式参与。如果你对可扩展性特别感兴趣,你应该也会对这些感兴趣:
- slack可扩展性频道
- 可扩展性"特殊兴趣小组”,每周四上午9点在SIG-Scale hangout的讨论。
当然,关于Kubernetes项目的更多信息,请登录官网 www.kubernetes.io
作者: Wojciech Tyczynski, 软件工程师,Google
译者: 天云软件 容器团队
--------------
一些备注:
- 我们API响应性测试中排除了对"events"资源的操作,因为它们更像系统日志,而且对于系统的正常运行不是必须的。
- 本文使用的测试类包括Kubernetes git仓库中的test/e2e/load.go。
- 本文使用的测试类包括Kubernetes git仓库中的test/e2e/density.go。
- 现在Kubernetes在较小规模的集群中可能导致性能显著下降,我们准备在下一版本优化这一点。我们鼓励任何针对Kubernetes做基准测试或试图复制这些研究结果的人使用同样大小规模的集群,否则性能会受到影响。