Linux常用命令自整理(持续更新)
Linux命令自整理
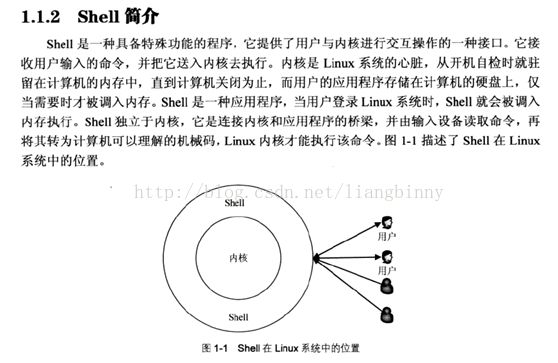
内核——shell——用户,用户通过shell命令与内核交互
Linux命令成千上万,不可能每个命令都记得住如何用,这时候,可以使用man 命令打开命令帮助页,查看命令怎么用,如:
输入q退出
分号(;)可以隔开同一行内多条命令,即多条命令按顺序执行
LS
ls [option] [file or direction]
ll 等价于 ls –l
ls –lrt, l显示文件的详细信息,r按字母逆序或者最早优先的顺序显示输出结果,t是显示按修改时间排序
CP
cp [option] [source] [destination]
-r实现目录递归复制,-a复制不改变文件生成时间
cp -r ./1023 ./tmp 实现目录直接复制。
cp -ar ./1023 ./tmp 实现目录直接复制,且不改变目录的修改时间。
MV
mv [option] [source] [destination]
mv也可以适用于文件的重命名
规则都一样,-f 不提示,-i会有提示操作,-r是对目录递归操作,-p移动时保持权限
RM
rm [option] [file or direction]
mkdir
mkdir [option] [direction]
mkdir –m 777 direct (创建目录并赋予权限,rwx读写执行权限)
mkdir –p路径名 (创建目录可以是一个路径,如果父目录不存在,则连父目录一起创建)。
如:mkdir -p /opt/samba/tmp/111/222/333
cd 等效于 cd ~返回用户目录
cd - 返回上一次的目录
文件权限
(-/d)(rwx)(rwx)(rwx)
(目录or文件)(属主用户权限)(与文件属主用户的同组用户权限)(其他用户权限)
chmod
u表示用户,g表组,o表示其他用户,a表示所有,+表示增加权限,-表示删除权限,=表示赋予给定权限并删除其他权限
chmod u+x 1.txt,表示给这个文件增加可执行权限
chmod 777 赋予全部权限
查找命令find
find [路径] [选项] [操作]
路径表示要查找的目录路径,即在什么路径下查找,
选项用于指定查找条件,比如:可以按照更改时间,文件属主,文件类型等方式查找,如:name根据文件名查找,mtime –n +n,-n表示更改时间在n天之内,+n表示修改时间在n天之前,type表示某一类型文件
操作用于指定结果的输出方式,如print将查找的结果输出
find . -name 'report*' -print
查找当前目录下包括子目录下的含有名称为”report”的文件或文件夹,并输出
vi命令
一般模式,直接vi进去就是一般模式
w(保存),q,q!(强退),wq
x删除字符,dd删除正行
hjkl,左下上右光标移动,^移动到当前行第一个非空字符,$移动到当前行尾
:n移动到n行
/搜索单词,?从下往上搜索,n查找下一个,N查找上一个,G直接到文件尾
插入模式,在一般模式下按i,o,a等字母都可以进入插入模式,按esc键可以返回到一般模式
正则表达式,空行:^$
^表示匹配以什么开头,但是在[]里,^表示是取反的意思
如匹配任意英文单词匹配法:
[A-Za-z] [A-Za-z]*
\<\>表示精确匹配,\
awk,perl,grep还支持正则表达式
grep命令可以是字符串,可以是变量,也可以是正则表达式
如:grep ‘Hello word’ filename.txt
grep “Hello world” f1.txt f2.txt (多文件grep)
grep “Hello world” f?.txt,表示查找f1.txt,f2.txt下的文件
grep –n “Hello world” f*.txt 查找Hello world的文件并显示文件所在的行数
grep -i 表示不区分大小写
grep -l Hello 1.txt只显示文件名
grep –r helloworld * ,,,,-r表示递归搜索,不仅搜索本目录,还包括子目录
grep [Hh]ello 1.txt 查找Hello,hello的行
grep ^/…./ 1.txt 查找以/开头,中间包含任意4个字符,第六个字符任是/的行,如/home/满足条件
grep www\.baidu\.com 1.txt ,,查找含有www.baidu.com的行
grep ‘\
grep –E “OA|ab” 1.txt,查找含有OA或ab的行,-E表示支持正则表达式,如果没有-E,|这个符号会被当作字符来处理,-E才表示|是或的意思。
grep –F “OA|ab” 1.txt 不支持正则表达式.
grep –v 显示不包含匹配文本的所有行
grep进程,但不包含自己
ps -ef|grep java|grep -v grep
grep命令族
egrep 扩展grep命令,支持基本和扩展正则表达式。相当于 grep -E
fgrep 快速grep命令,不支持正则表达式,按照字符串的字面意思进行匹配。相当于grep –F
文本处理工具sed和awk命令
sed只是针对原始文件的副本进行编辑,不编辑原始文件。如果需要保存改动内容,需要重定向>
sed [选项] ‘sed命令’ 输入文件
sed –n不打印源文件所有行输出
sed –f 表示正在调用sed脚本文件
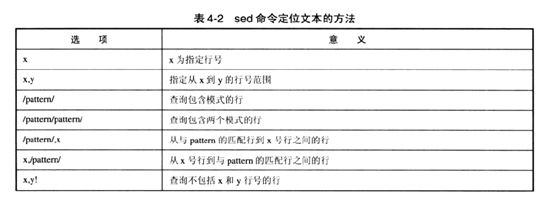
sed命令通常由定位文本行和sed编辑命令两部分组成
使用行号,指定一行或者指定行号范围
使用正则表达式
Sed编辑命令
p打印匹配行
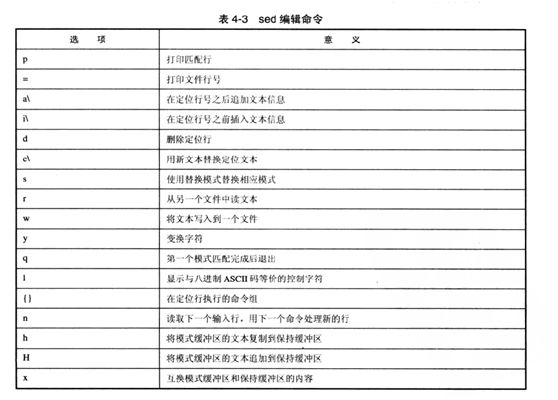
=打印文件号
a\在定位行号之后追加文本信息
i\在定位行号之前追加文本信息
d删除定位行
c\用新文本替换定位文本
s使用替换模式替换相应模式
r从另外一个文件中读文本
w将文本写入到另外一个文件中
sed–n ‘1p’ input.txt 只打印第一行,1是定位文本,第一行,p是编辑命令,打印匹配行
sed -n '1,3p' server.log 只打印第1-3行,

利用sed命令打印模式匹配行,用/patten/方法进行模式匹配
sed -n '/Starting/p' server.log

sed 编辑命令可以放在’’里面,也可以放在外面
sed -n '/Starting/'p server.log
log.txt
[root@bogon tmp]# cat log.txt
This is a book ..
We learn Linux.
How are you.
Here you are .
[root@bogon tmp]#
插入文本i\(前面) 或者 a\(追加)
insert.sed
[root@bogon tmp]# cat insert.sed
#!/bin/sed -f
/Here/i\
Here insert a new line
执行脚本
./insert.sed log.txt
得到结果:匹配含有Here的行,并在该行前面(i\)添加Here insert a new line
[root@bogon tmp]# ./insert.sed log.txt
This is a book ..
We learn Linux.
How are you.
Here insert a new line
Here you are .
[root@bogontmp]#
这个只是输出到控制台,并没有改log.txt文件
修改文本c\
将匹配的文本,用新文本替代,用编辑命令为c\,修改文本的格式为:
sed ‘匹配文本 c\替换文本’ 输入文件
log.txt
[root@bogon tmp]# cat log.txt
This is a book ..
We learn Linux.
How are you.
Here you are .
[root@bogon tmp]#
modify.sed文件:
[root@bogon tmp]# cat modify.sed
#!/bin/sed -f
/Here/c\
we modify this line.
[root@bogon tmp]#
执行modify.sed文件,修改文本:
[root@bogon tmp]# ./modify.sed log.txt
This is a book ..
We learn Linux.
How are you.
we modify this line.
[root@bogon tmp]#
删除文本d
sed ‘1d’ log.txt 删除第一行
sed ‘1,10d’ log.txt 删除1-10行
sed ‘5,$d’ log.txt 删除5到最后一行
sed ‘$d’ log.txt 删除最后一行
sed '/This/'d log.txt 删除匹配This的行,d可以在’’内外都可以。
[root@bogon tmp]# cat log.txt
This is a book ..
We learn Linux.
How are you.
Here you are .
[root@bogon tmp]# sed '1d' log.txt
We learn Linux.
How are you.
Here you are .
[root@bogon tmp]# sed '$d' log.txt
This is a book ..
We learn Linux.
How are you.
Here you are .
[root@bogon tmp]#
[root@bogon tmp]# sed '/This/'d log.txt
We learn Linux.
How are you.
Here you are .
[root@bogon tmp]#
替换文本 s/
s /被替换的字符串/新字符串/ [替换选项]
sed 's/Here/Where/' log.txt
[root@bogon tmp]# sed 's/Here/Where/'log.txt
This is a book ..
We learn Linux.
How are you.
Where you are .
[root@bogon tmp]#
与-n结合,p只打印替换行。
sed -n 's/Here/Where/p' log.txt
[root@bogon tmp]# sed -n 's/Here/Where/p'log.txt
Where you are .
[root@bogon tmp]#
sed -n 's/Here/Where/pg' log.txt
[root@bogon tmp]# sed -n 's/Here/Where/pg'log.txt
Where you are .
[root@bogon tmp]#
g是替换所有出现的地方,当匹配的那行出现两个相同的匹配时,g才起作用。
tr命令
通过使用 tr,您可以非常容易地实现sed 的许多最基本功能。您可以将 tr 看作为 sed 的(极其)简化的变体:它可以用一个字符来替换另一个字符,或者可以完全除去一些字符。您也可以用它来除去重复字符。这就是所有 tr 所能够做的。
tr用来从标准输入中通过替换或删除操作进行字符转换。tr主要用于删除文件中控制字符或进行字符转换。使用tr时要转换两个字符串:字符串1用于查询,字符串2用于处理各种转换。tr刚执行时,字符串1中的字符被映射到字符串2中的字符,然后转换操作开始。
tr ["string1_to_translate_from"]["string2_to_translate_to"] < input-file
将string1替换为string2
-c是表示用string1的补集替换为string2
带有最常用选项的tr命令格式为:
tr -c -d -s["string1_to_translate_from"] ["string2_to_translate_to"]< input-file
-c 将字符串1中字符集的补集替换为此字符集string2,要求字符集string2为ASCII。
-d 删除字符串1中所有输入字符。
-s 删除所有重复出现字符序列,只保留第一个;即将重复出现字符串压缩为一个字符串。
input-file是转换文件名。虽然可以使用其他格式输入,但这种格式最常用。
字符范围
指定字符串1或字符串2的内容时,只能使用单字符或字符串范围或列表。
[a-z] a-z内的字符组成的字符串。
[A-Z] A-Z内的字符组成的字符串。
[0-9] 数字串。
\octal 一个三位的八进制数,对应有效的ASCII字符。
[O*n] 表示字符O重复出现指定次数n。因此[O*2]匹配OO的字符串。
tr中特定控制字符的不同表达方式
速记符含义八进制方式
\a Ctrl-G 铃声\007
\b Ctrl-H 退格符\010
\f Ctrl-L 走行换页\014
\n Ctrl-J 新行\012
\r Ctrl-M 回车\015
\t Ctrl-I tab键\011
\v Ctrl-X \030
实例:
将文件file中出现的" el "替换为"ab"
[root@bogon tmp]# cat newfile
ss
hello world
[root@bogon tmp]# cat newfile | tr"el" "ab"
ss
habbo worbd
[root@bogon tmp]#
【注意】这里,凡是在file中出现的"e"字母,都替换成"a"字母,"l"字母替换为"b"字母。而不是将字符串"el"替换为字符串"ab"。
使用tr命令“统一”字母大小写
(小写 --> 大写)
# cat file | tr [a-z] [A-Z] > newfile
(大写 --> 小写)
# cat file | tr [A-Z] [a-z] > newfile
把文件中的数字0-9替换为a-j
# cat file | tr [0-9] [a-j] > newfile
4、删除文件file中出现的"Snail"字符
# cat file | tr -d "Snail" >newfile
【注意】这里,凡是在file文件中出现的'S','n','a','i','l'字符都会被删除!而不是紧紧删除出现的"Snail”字符串。
[root@bogon tmp]# cat newfile | tr [a-z][A-Z]
SS
HELLO WORLD
[root@bogon tmp]# cat newfile | tr [A-Z][a-z]
ss
hello world
[root@bogon tmp]#
[root@bogon tmp]# cat newfile | tr -d"hello"
ss
wrd
[root@bogon tmp]#
【注意】这里,凡是在file文件中出现的'h','e','l','l','0'字符都会被删除!而不是紧紧删除出现的"hello”字符串。
5、删除文件file中出现的换行'\n'、制表'\t'字符
# cat file | tr -d "\n\t" >new_file
不可见字符都得用转义字符来表示的,这个都是统一的。
[root@bogon tmp]# cat newfile | tr -d"\n\t"
sshello world[root@bogon tmp]#
6、删除“连续着的”重复字母,只保留第一个
# cat file | tr -s [a-zA-Z] > new_file
[root@bogon tmp]# cat newfile | tr -s [a-z]
s
helo world
[root@bogon tmp]#
7、删除空行
# cat file | tr -s "\n" >new_file
8、删除Windows文件“造成”的'^M'字符(回车)
# cat file | tr -d "\r" >new_file
或者
# cat file | tr -s "\r""\n" > new_file
【注意】这里-s后面是两个参数"\r"和"\n",用后者替换前者
即\n替换\r,加上-s,就去重\n,只出现一个\n
awk
awk调用与sed类似,也有三种方式
一种为shell命令行方式,另外两种是将awk程序写入脚本文件,然后执行该脚本文件。
任何awk语句都由模式(pattern)和动作(action)组成。
[root@bogon tmp]# awk '/^$/{print"this is a blank"}' log.txt
this is a blank
[root@bogon tmp]#
awk '/^$/{print "this is ablank"}' log.txt
这是awk的第一种调用方式,单引号中间是awk命令,该awk命令由两部分组成,以/符号分隔,^$部分是模式,花括号部分是动作,该命令表示一旦读入的是空行,就打印”this is a blank” 。^$是正则表达式,表示空白行,print表示该动作是打印操作,log.txt表示输入的文件。
awk的第二种调用方式
awk -f [命令文件] 文本文件
awk -f src.awk log.txt
[root@bogon tmp]# cat src.awk
/^$/{print "this is a blank"}
[root@bogon tmp]#
[root@bogon tmp]# awk -f src.awk log.txt
this is a blank
[root@bogon tmp]#
awk的第三种调用方式
直接执行awk脚本文件来调用,与sed方法一样,脚本内容:
[root@bogon tmp]# cat src1.awk
#!/bin/awk -f
/^$/{print "this is a blank"}
[root@bogon tmp]#
[root@bogon tmp]# ./src1.awk log.txt
this is a blank
[root@bogon tmp]#
记录和域
Hi Man 400-111111
Hi, Man,400-111111共3个域,两个或两个以上空格,或者tab键当作一个分隔符来处理,对文本文件分域处理是Linux系统中很多命令都使用的方法。
awk定义域操作符$来指定执行当作的域,如$1表示第一个操作域,$2表示第二个,$0表示所有域
[root@bogon tmp]# cat source.txt
Li Hao kkk123456
Li Si ddd123466
zhang san fff 123467
[root@bogon tmp]# awk '{print$1,$2,",",$4,$3}' source.txt
Li Hao , 123456 kkk
Li Si , 123466 ddd
zhang san , 123467 fff
[root@bogon tmp]#
[root@bogon tmp]# awk '{print $0}'source.txt
Li Hao kkk123456
Li Si ddd123466
zhang san fff 123467
[root@bogon tmp]#
$后面还可以跟变量
[root@bogon tmp]# awk 'BEGIN {one=1;two=2}{print $(one + two)}' source.txt
kkk
ddd
fff
[root@bogon tmp]#
实际就是print $3
awk –F可以改变分隔域,如用Tab键来当作分隔域
awk –F”\t” ‘{print $3}’ source.txt
[root@bogon tmp]# awk -F"\t"'{print $2}' source.txt
kkk 123456
ddd 123466
fff123467
[root@bogon tmp]#
尽管-F可以改变分隔符,但是awk还提供了另一种更方便的方法来改变分隔符,这就是改变awk环境变量FS,
[root@bogon tmp]# awk 'BEGIN {FS=","}{print $1,$3}' source1.txt
Li Hao 123456
Li Si 123466
zhang san 123467
[root@bogon tmp]#
关系和布尔运算符
awk定义了一组关系运算符用于awk模式匹配,

匹配第一个域中含有Li的行
[root@bogon tmp]# awk 'BEGIN{FS=","} $1~/Li/' source1.txt
Li Hao,kkk,123456
Li Si,ddd,123466
[root@bogon tmp]#
不匹配第一个域中含有Li的行
[root@bogon tmp]# awk 'BEGIN{FS=","} $1!~/Li/' source1.txt
zhang san,fff,123467
[root@bogon tmp]#
打印第三域大于123466的行
[root@bogon tmp]# awk 'BEGIN{FS=","} {if($3 >= 123466) print $0}' source1.txt
Li Si,ddd,123466
zhang san,fff,123467
[root@bogon tmp]#
awk '/^$/{print x+=1}' source1.txt 打印空白行的序号 。
[root@bogon tmp]# cat source1.txt
Li Hao,kkk,123456
Li Si,ddd,123466
zhang san,fff,123467
[root@bogon tmp]#
[root@bogon tmp]# awk '/^$/{print x+=1}'source1.txt
1
2
3
source2.txt存放的是学生姓名以及最后三列存放的是成绩,用awk计算每个学生的平均成绩.
[root@bogon tmp]# cat source2.txt
Li Hao,kkk,82,92,69
Li Si,ddd,96,74,88
zhang san,fff,75,72,74
[root@bogon tmp]#
[root@bogon tmp]# cat src2.awk
#!/bin/awk -f
BEGIN {FS=","}
{total=$3+$4+$5
avg=total/3
print $1,avg}
[root@bogon tmp]#
[root@bogon tmp]# ./src2.awk source2.txt
Li Hao 81
Li Si 86
zhang san 73.6667
[root@bogon tmp]#
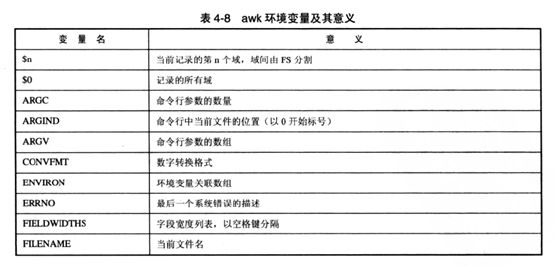
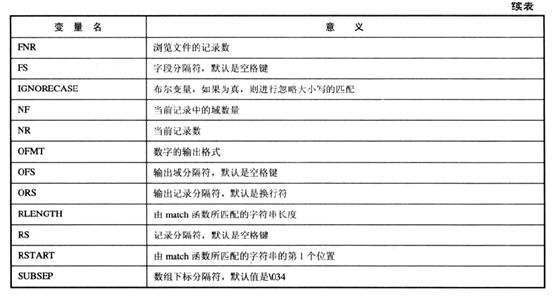
awk环境变量
awk定义了很多环境变量,我们称他们为系统变量
[root@bogon tmp]# awk 'BEGIN{FS=","} {printf("%s\t%d\t%d\r\n",$1,$3,$4)}' source2.txt
Li Hao 82 92
Li Si 96 74
zhang san 75 72
[root@bogon tmp]#
%-15s表示长度控制在15位,不够长用空格补齐
[root@bogon tmp]# awk 'BEGIN{FS=","} {printf("%-15s\t%d\t%d\r\n",$1,$3,$4)}' source2.txt
Li Hao 82 92
Li Si 96 74
zhang san 75 72
[root@bogon tmp]#
awk 'BEGIN {FS=",";print"Name\t\tMach\t\tEnglish"}{printf("%-15s\t%d\t%d\r\n",$1,$3,$4)}' source2.txt
[root@bogon tmp]# awk 'BEGIN{FS=",";print "Name\t\tMach\t\tEnglish"}{printf("%-15s\t%d\t%d\r\n",$1,$3,$4)}' source2.txt
Name Mach English
Li Hao 82 92
Li Si 96 74
zhang san 75 72
[root@bogon tmp]#
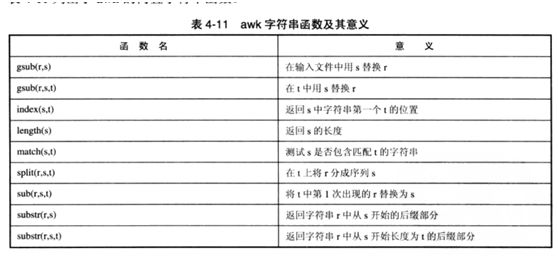
内置字符串函数
[root@bogon tmp]# awk 'BEGIN{FS=",";OFS=","} gsub(/Li/,"Zhang") {print $0}'source2.txt
Zhang Hao,kkk,82,92,69
Zhang Si,ddd,96,74,88
[root@bogon tmp]#
FS是源文件分隔符,OFS是输出作用域分隔符,gsub方法把Li替换成Zhang
结果只替换了两行
index输出ll在Hello出现的位置。
[root@bogon tmp]# awk 'BEGIN {printindex("Hello","ll")}'
3
[root@bogon tmp]#
length输出字符串长度
[root@bogon tmp]# awk 'BEGIN {printlength("Hello")}'
5
[root@bogon tmp]#
sort
-t按分隔符进行排序,默认是按第一作用域排序
[root@bogon tmp]# sort -t, source2.txt
Li Hao,kkk,82,92,69
Li Si,ddd,96,74,88
zhang san,fff,75,72,74
[root@bogon tmp]#
-k指定按某作用域排序,且默认是按字符串方式排序
[root@bogon tmp]# sort -t, -k3 source2.txt
zhang san,fff,75,72,74
Li Hao,kkk,82,92,69
Li Si,ddd,96,74,88
[root@bogon tmp]#
如果要让它按照数字大小排序,可加n
[root@bogon tmp]# sort -t, -k3n source2.txt
zhang san,fff,75,72,74
Li Hao,kkk,82,92,69
Li Si,ddd,96,74,88
[root@bogon tmp]#
如果要按逆向排序,可加r
[root@bogon tmp]# sort -t, -k3nrsource2.txt
Li Si,ddd,96,74,88
Li Hao,kkk,82,92,69
zhang san,fff,75,72,74
[root@bogon tmp]#
-u 去除结果中的重复行
[root@bogon tmp]# sort -t, -k3nrsource2.txt
Li Si,ddd,96,74,88
Li Si,ddd,96,74,88
Li Hao,kkk,82,92,69
zhang san,fff,75,72,74
[root@bogon tmp]#
Li Si那行有两条记录,是重复的,要只显示一条,可加-u
[root@bogon tmp]# sort -t, -k3nr -usource2.txt
Li Si,ddd,96,74,88
Li Hao,kkk,82,92,69
zhang san,fff,75,72,74
[root@bogon tmp]#
-o
如果要将排序后的结果输出到某个文件,可以用-o,后面加文件名
[root@bogon tmp]# sort -t, -k3nr -u -osource3.txt source2.txt
[root@bogon tmp]# cat source3.txt
Li Si,ddd,96,74,88
Li Hao,kkk,82,92,69
zhang san,fff,75,72,74
[root@bogon tmp]#
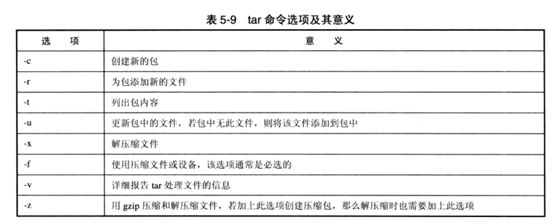
tar
tar [选项] [新包名] 文件名或目录名
tar -cvf source.tar source*
将所有的source*文件打包进source.tar里面
[root@bogon tmp]# tar -cvf source.tarsource*
source1.txt
source2.txt
source3.txt
source.txt
完成后就发现有source.tar
source.tar
要想查看包的内容(不解压),可以用tf
tar -tf source.tar
[root@bogon tmp]# tar -tf source.tar
source1.txt
source2.txt
source3.txt
source.txt
[root@bogon tmp]#
tar –u可以更新包中的文件,如果包中没有这个文件,则添加进包中
[root@bogon tmp]# tar -uf source.tarsource.txt
[root@bogon tmp]#
解压
tar –xvf 压缩包名称 #解压非gzip格式的压缩包
tar –zxvf 压缩包名称 #解压gzip格式的压缩包
tar –cf命令创建的包实际上是将多个文件放到一起,并没有压缩,gzip命令是Linux中常用的压缩工具,它可以对tar命令创建的包进行压缩
[root@bogon tmp]# ll
total 52
-rwxr-xr-x. 1 root root 48 Nov 17 22:57 insert.sed
-rwxrwxrwx. 1 root root 64 Nov 17 23:10 log.txt
-rwxr--r--. 1 root root 45 Nov 17 23:08 modify.sed
-rw-r--r--. 1 root root 59 Nov 19 22:39 source1.txt
-rw-r--r--. 1 root root 81 Nov 20 00:51 source2.txt
-rw-r--r--. 1 root root 62 Nov 20 00:53 source3.txt
-rw-r--r--. 1 root root 10240 Dec 1 23:19 source.tar
-rw-r--r--. 1 root root 57 Nov 19 19:30 source.txt
-rwxr--r--. 1 root root 45 Nov 18 23:37 src1.awk
-rwxr--r--. 1 root root 71 Nov 19 22:51 src2.awk
-rwxr--r--. 1 root root 31 Nov 18 22:59 src.awk
压缩前source.tar 有10240B
[root@bogon tmp]# gzip source.tar
[root@bogon tmp]# ll
total 44
-rwxr-xr-x. 1 root root 48 Nov 17 22:57 insert.sed
-rwxrwxrwx. 1 root root 64 Nov 17 23:10 log.txt
-rwxr--r--. 1 root root 45 Nov 17 23:08 modify.sed
-rw-r--r--. 1 root root 59 Nov 19 22:39 source1.txt
-rw-r--r--. 1 root root 81 Nov 20 00:51 source2.txt
-rw-r--r--. 1 root root 62 Nov 20 00:53 source3.txt
-rw-r--r--. 1 root root 307 Dec 1 23:19 source.tar.gz
-rw-r--r--. 1 root root 57 Nov 19 19:30 source.txt
-rwxr--r--. 1 root root 45 Nov 18 23:37 src1.awk
-rwxr--r--. 1 root root 71 Nov 19 22:51 src2.awk
-rwxr--r--. 1 root root 31 Nov 18 22:59 src.awk
[root@bogon tmp]#
压缩后有307B,而且包名变为source.tar.gz
解压,需要解压包内所有文件,用tar –zxvf source.tar.gz
[root@bogon tmp]# ll
total 4
-rw-r--r--. 1 root root 307 Dec 1 23:19 source.tar.gz
[root@bogon tmp]# tar -zxvf source.tar.gz
source1.txt
source2.txt
source3.txt
source.txt
[root@bogon tmp]# ll
total 20
-rw-r--r--. 1 root root 59 Nov 19 22:39 source1.txt
-rw-r--r--. 1 root root 81 Nov 20 00:51 source2.txt
-rw-r--r--. 1 root root 62 Nov 20 00:53 source3.txt
-rw-r--r--. 1 root root 307 Dec 1 23:19 source.tar.gz
-rw-r--r--. 1 root root 57 Nov 19 19:30 source.txt
[root@bogon tmp]#
gzip –d 命令可以还原source.tar.gz到source.tar,不解压文件。
[root@bogon tmp]# gzip -d source.tar.gz
[root@bogon tmp]# ll
total 28
-rw-r--r--. 1 root root 59 Nov 19 22:39 source1.txt
-rw-r--r--. 1 root root 81 Nov 20 00:51 source2.txt
-rw-r--r--. 1 root root 62 Nov 20 00:53 source3.txt
-rw-r--r--. 1 root root 10240 Dec 1 23:19 source.tar
-rw-r--r--. 1 root root 57 Nov 19 19:30 source.txt
[root@bogon tmp]#
变量和引用
[root@bogon tmp]# variable1=1
[root@bogon tmp]# echo $variable1
1
[root@bogon tmp]#
变量间有空格,应该用“”括起来
[root@bogon tmp]# mmm="HelloWorld"
[root@bogon tmp]# echo $mmm
Hello World
[root@bogon tmp]#
unset命令可以清除变量的值
unset 变量名
[root@bogon tmp]# unset mmm
[root@bogon tmp]# echo $mmm
[root@bogon tmp]#
环境变量
环境变量适用于所有登录进程所产生的子进程.
变量名=变量值 #环境变量赋值
export 变量名
环境变量的名称一般由大写字母组成.
清除环境变量跟清除变量一样,用unset
[root@bogon Desktop]# APPSPATH=/usr/local
[root@bogon Desktop]# export APPSPATH
[root@bogon Desktop]# echo $APPSPATH
/usr/local
[root@bogon Desktop]#
可以看到刚才设置的APPSPATH值
[root@bogon Desktop]# env|grep APPSPATH
APPSPATH=/usr/local
[root@bogon Desktop]#
重要的环境变量
PWD变量存的是当前目录路径,OLDPWD存放的是上一个目录路径
cd切换到其他目录时,系统会自动修改这两个变量的值
[root@bogon ~]# echo $PWD
/root
[root@bogon ~]# echo $OLDPWD
/root/Desktop
[root@bogon ~]#
PATH是Linux中极为重要的一个环境变量,它用于帮助Shell找到用户所输入的命令.各个目录用冒号分割。
[root@bogon ~]# echo $PATH
/usr/local/sbin:/usr/sbin:/sbin:/usr/local/bin:/usr/bin:/bin:/root/bin
修改PATH变量可以如下:
[root@bogon ~]# exportPATH="/usr/local":$PATH
[root@bogon ~]# echo $PATH
/usr/local:/usr/local/sbin:/usr/sbin:/sbin:/usr/local/bin:/usr/bin:/bin:/root/bin
[root@bogon ~]#
在HOME目录,Linux以.开头的文件为隐藏文件
ll –a可以查看到所有的文件。
$HOME/.bash_profile是最重要的配置文件,当某linux用户登录时,Shell会自动执行.bash_profile文件
[root@bogon ~]# cat .bash_profile
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
.~/.bashrc
fi
# User specific environment and startupprograms
PATH=$PATH:$HOME/bin
export PATH
[root@bogon ~]#
可以看到,.bash_profile做了些初始化环境变量的操作
$HOME下的.bash_profile是用户的环境变量,影响的是单用户, 而/etc/profile是系统的环境变量,影响全部用户
修改了环境变量,仍然需要source /etc/profile生效
以下是辅助知识:
Linux 的变量可分为两类:环境变量和本地变量
环境变量,或者称为全局变量,存在与所有的shell 中,在你登陆系统的时候就已经有了相应的系统定义的环境变量了。Linux 的环境变量具有继承性,即子shell 会继承父shell 的环境变量。
本地变量,当前shell 中的变量,很显然本地变量中肯定包含环境变量。Linux 的本地变量的非环境变量不具备继承性。
Linux 中环境变量的文件
当你进入系统的时候,linux就会为你读入系统的环境变量,这些环境变量存放在什么地方,那就是环境变量的文件中。Linux 中有很多记载环境变量的文件,它们被系统读入是按照一定的顺序的。
1. /etc/profile :
此文件为系统的环境变量,它为每个用户设置环境信息,当用户第一次登录时,该文件被执行。并从/etc/profile.d 目录的配置文件中搜集shell 的设置。
这个文件,是任何用户登陆操作系统以后都会读取的文件(如果用户的shell 是csh 、tcsh 、zsh ,则不会读取此文件),用于获取系统的环境变量,只在登陆的时候读取一次。
假设用户使用的是BASH ,那么
2. /etc/bashrc :
在执行完/etc/profile 内容之后,如果用户的SHELL 运行的是bash ,那么接着就会执行此文件。另外,当每次一个新的bash shell 被打开时, 该文件被读取。
每个使用bash 的用户在登陆以后执行完/etc/profile中内容以后都会执行此文件,在新开一个bash 的时候也会执行此文件。因此,如果你想让每个使用bash 的用户每新开一个bash 和每次登陆都执行某些操作,或者给他们定义一些新的环境变量,就可以在这个里面设置。
3. ~/.bash_profile :
每个用户都可使用该文件输入专用于自己使用的shell 信息。当用户登录时,该文件仅仅执行一次,默认情况下,它设置一些环境变量,执行用户的.bashrc 文件。
单个用户此文件的修改只会影响到他以后的每一次登陆系统。因此,可以在这里设置单个用户的特殊的环境变量或者特殊的操作,那么它在每次登陆的时候都会去获取这些新的环境变量或者做某些特殊的操作,但是仅仅在登陆时。
4. ~/.bashrc :
该文件包含专用于单个人的bash shell 的bash 信息,当登录时以及每次打开一个新的shell 时, 该该文件被读取。
单个用户此文件的修改会影响到他以后的每一次登陆系统和每一次新开一个bash 。因此,可以在这里设置单个用户的特殊的环境变量或者特殊的操作,那么每次它新登陆系统或者新开一个bash ,都会去获取相应的特殊的环境变量和特殊操作。
~/.bash_logout :
当每次退出系统( 退出bash shell) 时, 执行该文件。
几个命令
env 和printenv
这两个变量用于打印所有的环境 变量:
set
用于显示与设置当前本地变量。单独一个set 就显示了当前环境的所有的变量,它肯定包括环境变量和一些非环境变量
unset
用于清除变量。不管这个变量是环境变量还是本地变量,它都可以清除。
位置参数
从命令行向Shell脚本传递参数,$1表示第一个参数,$2表示第二个参数,$*和$@一样,表示所有参数,$0表示脚本名称,$#表示传递参数的数量,$$脚本运行的进程号,$?命令的退出状态,0表示没有错,非0表示有错误。
[root@bogon ~]# cat position
#!/bin/sh
echo "The script name is : $0"
echo "Parameter #1:$1"
echo "Parameter #2:$2"
echo "Parameter #3:$3"
echo "-----------------------"
echo "All the command line parametersare : $*"
echo "The number of command lineparameters is:$#"
echo "The process ID is:$$"
echo "Did this script have anyerrors?$?"
[root@bogon ~]#
[root@bogon ~]# ./position How are you
The script name is : ./position
Parameter #1:How
Parameter #2:are
Parameter #3:you
-----------------------
All the command line parameters are : Howare you
The number of command line parameters is:3
The process ID is:2736
Did this script have any errors?0
[root@bogon ~]#
引用
双引号“”表示引用除美元符号($),反引号(`),反斜杠外的所有字符
单引号’’表示引用所有字符
``反引号表示系统命令
\反斜杠表示转义符,屏蔽下一个字符的特殊意义。
[root@bogon tmp]# cat double.sh
#!/bin/bash
variable=2001
echo "$variable"
echo $variable
variable2="X Y Z"
echo "$variable2"
echo $variable2
[root@bogon tmp]#
[root@bogon tmp]# ./double.sh
2001
2001
X Y Z
X Y Z
[root@bogon tmp]#
单引号和双引号的区别:
[root@bogon tmp]# echo "$PWD is adirecty"
/root/tmp is a directy
[root@bogon tmp]# echo '$PWD is a directy'
$PWD is a directy
命令替换
命令替换是指将命令的标准输出作为值赋给某个变量,bash shell定义了两种语法进行命令替换,一种是使用反引号(``),另一种是利用$(),两种等价,语法如下:
`Linux命令`
$(Linux命令)
比如:pwd是显示当前工作目录的命令,`pwd`和$(pwd)等价,值都为当前工作目录,与环境变量$PWD一致
[root@bogon tmp]# echo `who`
root tty1 2014-12-03 17:15 (:0) root pts/02014-12-03 17:18 (:0.0)
[root@bogon tmp]# echo `world`
bash: world: command not found
[root@bogon tmp]# echo `date`
Wed Dec 3 17:46:59 PST 2014
[root@bogon tmp]#
[root@bogon tmp]# dirlist=`ls -l|grepsource`
[root@bogon tmp]# echo $dirlist
-rw-r--r--. 1 root root 59 Nov 19 22:39source1.txt -rw-r--r--. 1 root root 81 Nov 20 00:51 source2.txt -rw-r--r--. 1root root 62 Nov 20 00:53 source3.txt -rw-r--r--. 1 root root 57 Nov 19 19:30source.txt
[root@bogon tmp]# echo "$dirlist"
-rw-r--r--. 1 root root 59 Nov 19 22:39 source1.txt
-rw-r--r--. 1 root root 81 Nov 20 00:51 source2.txt
-rw-r--r--. 1 root root 62 Nov 20 00:53 source3.txt
-rw-r--r--. 1 root root 57 Nov 19 19:30 source.txt
[root@bogon tmp]#
尽管``和$()是等价,但$()可以嵌套
$?可以查看上一次命令的执行结果
[root@bogon tmp]# echo $?
0
[root@bogon tmp]#
测试
测试命令可以用于测试表达式的条件的真假。
测试命令有两种,一种是用test expression,另一种是更为可读的,[ expression ],注意expression前后要有空格,[]经常与if else使用
整数比较运算符:
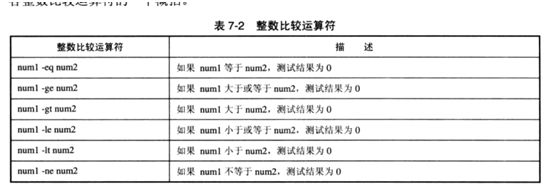
[root@bogon tmp]# num1=15
[root@bogon tmp]# [ "$num1" -eq15 ]
[root@bogon tmp]# echo $?
0
[root@bogon tmp]#
[root@bogon tmp]# [ $num1 -eq 15 ]
[root@bogon tmp]# echo $?
0
[root@bogon tmp]#
[root@bogon tmp]# [ $num1 -ge 15 ]
[root@bogon tmp]# echo $?
0
[root@bogon tmp]#
[root@bogon tmp]# [ $num1 -gt 15 ]
[root@bogon tmp]# echo $?
1
[root@bogon tmp]#
字符串运算符:
-n string 判断字符串不为空
-z string 判断字符串为空
string1 = string2 是否相同
string1 != string2 是否不同
判断
if/else,if/elif/else和case
单if
if expression
then
command
command
fi
[root@bogon tmp]# cat if_exam.sh
#!/bin/bash
#input a number
echo "Please input a number:"
read integer1
if [ "$integer1" -gt 15 ]
then echo "the number you input islarge 15"
fi
[root@bogon tmp]#
[root@bogon tmp]# ./if_exam.sh
Please input a number:
11
[root@bogon tmp]# ./if_exam.sh
Please input a number:
16
the number you input is large 15
[root@bogon tmp]#
if/elif/else
[root@bogon tmp]# cat if_exam.sh
#!/bin/bash
#input a number
echo "Please input a number:"
read integer1
if [ "$integer1" -gt 15 ]
then
echo "the number you input is large15"
elif [ "$integer1" -eq 15 ]
then
echo "the number you input is equal15"
else
echo "the number you input is small15"
fi
[root@bogon tmp]#
[root@bogon tmp]# ./if_exam.sh
Please input a number:
15
the number you input is equal 15
[root@bogon tmp]#
case 结构
case variable in
value1)
command
…..
command;;
value2)
command;;
*)
command;;
esac
[root@bogon tmp]# cat case_exam.sh
#!/bin/bash
echo "Please input a day:"
read day
case "$day" in
1)
echo "Monday"
echo "Mon";;
2)
echo "Tur";;
3)
echo "Wed";;
4)
echo "Thu";;
5)
echo "Fri";;
6)
echo "Sat";;
7)
echo "Sun";;
*)
echo "input error"
esac
[root@bogon tmp]#
[root@bogon tmp]# ./case_exam.sh
Please input a day:
1
Monday
Mon
[root@bogon tmp]# ./case_exam.sh
Please input a day:
7
Sun
[root@bogon tmp]# ./case_exam.sh
Please input a day:
0
input error
[root@bogon tmp]#
数字常量
在linux中,shell用num#表示不同的进制,
[root@bogon tmp]# cat constant_exam.sh
#!/bin/bash
let "num1=40"
echo "num1=$num1"
let "num2=040"
echo "num2=$num2"
let "num3=0x40"
echo "num3=$num3"
let "num4=6#40"
echo "num4=$num4"
[root@bogon tmp]#
[root@bogon tmp]# ./constant_exam.sh
num1=40
num2=32
num3=64
num4=24
[root@bogon tmp]#
for循环
for variable in {list}
do
command
command
done
[root@bogon tmp]# cat for_exam.sh
#!/bin/bash
for variable in 1 2 3 4 5
do
echo"Hello World"
done
[root@bogon tmp]# ./for_exam.sh
Hello World
Hello World
Hello World
Hello World
Hello World
[root@bogon tmp]#
[root@bogon tmp]# cat for_exam2.sh
#!/bin/bash
for file in $( ls )
do
echo"file: $file"
done
[root@bogon tmp]#
[root@bogon tmp]# ./for_exam2.sh
file: case_exam.sh
file: constant_exam.sh
file: double.sh
file: for_exam2.sh
file: for_exam.sh
file: if_exam.sh
file: insert.sed
file: log.txt
file: modify.sed
file: source1.txt
file: source2.txt
file: source3.txt
file: source.txt
file: src1.awk
file: src2.awk
file: src.awk
file: text
file: tmp
[root@bogon tmp]#
读取入参for循环
[root@bogon tmp]# cat for_exam3.sh
#!/bin/bash
echo "number of arguments is $#"
for arg in $*
do
echo"$arg"
done
[root@bogon tmp]#
[root@bogon tmp]# ./for_exam3.sh 1 2 3
number of arguments is 3
1
2
3
[root@bogon tmp]#
类C风格for循环
[root@bogon tmp]# cat for_exam4.sh
#!/bin/bash
for(( i=1;i<5;i++ ))
do
echo"$i"
done
[root@bogon tmp]# ./for_exam4.sh
1
2
3
4
[root@bogon tmp]#
计算1-4的和
[root@bogon tmp]# cat for_exam5.sh
#!/bin/bash
sum=0
for(( i=1;i<5;i++ ))
do
let "sum += i"
done
echo "sum=$sum"
[root@bogon tmp]# ./for_exam5.sh
sum=10
[root@bogon tmp]#
while
[root@bogon tmp]# cat while_exam.sh
#!/bin/bash
echo "please input a number:"
read num
while [[ "$num" != 4 ]]
do
if[ "$num" -lt 4 ]
then
echo" to small,input again "
readnum
elif [ "$num" -gt 4 ]
then
echo"to big , input again "
readnum
else
exit0
fi
done
echo "right"
[root@bogon tmp]#
[root@bogon tmp]# ./while_exam.sh
please input a number:
1
tosmall,input again
6
to big , input again
4
right
[root@bogon tmp]#
Break
#!/bin/bash
for(( i=1;i<5;i++ ))
do
echo"$i"
done
[root@bogon tmp]# ./break_exam.sh
sum=1
sum=3
sum=6
[root@bogon tmp]#
select
[root@bogon tmp]# cat select_exam.sh
#!/bin/bash
echo "what is your favriouscolor?"
select color in "red""blud" "green" "yellow"
do
break
done
echo "you have selectcolor:$color"
[root@bogon tmp]# ./select_exam.sh
what is your favrious color?
1) red
2) blud
3) green
4) yellow
#? 1
you have select color:red
[root@bogon tmp]#
I/O 重定向
cmd1 |cmd2 : pipe,将cmd1 的标准输出作为cmd2 的标准输入
>file :将标准输出重定向到file
>>file :将标准输出重定向到file,如果file存在,append到文件中,即附加到文件的后面,而不是覆盖文件 当cat不带参数的时候,表示使用标准输入作为输入,这允许在标准输入中键入相关的内容,下面将alias加入.bashrc作为最后一行 $ cat >> .bashrc alias cdmnt='mount -t iso9660 /dev/sbpcd /cdrom' ^D Ctrl+D退出 >|file :强制将标准输出重定向到file,即使noclobber设置。当设置环境变量set–o noclobber,将禁止重定向到一个已经存在的文件中,避免文件被覆盖。 n >|file :强制将文件描述符n重定向到file,即使noclobber打开 n>>file :将文件描述符n的输出重定向到file,如果file存在,将输出append到文件后面 n>& :将标准输出复制到文件描述符n(Duplicatestandard output to file descriptor n) n<& :从文件描述符n复制标准输入(Duplicatestandard input from file descriptor n) n>&m :文件描述字n将一个copy至文件描述字m(Filedescriptor n is made to be a copy of the output file descriptor) n<&m :文件描述字n作为文件描述字m中的一个拷贝(Filedescriptor n is made to be a copy of the input file descriptor) &>file : 将标准输出和标准错误输出定向至文件file <&- : 关闭标准输入 >&- : 关闭标准输出 n>&- : 关闭文件描述字作为输出(Close theoutput from file descriptor n) n<&- :关闭文件描述字作输入(Close theinput from file descriptor n) 文件描述符在bash中比较少用,从0开始用户表示进行的数据流,0表示标准输入,1表示标准输出,2表示标注错误输出,其他从3开始。最为常用的场景是将错误消息输出到某个文件,可以加上2>file 到我们的命令中。 我们来看下面一个脚本的例子: command > logfile 2>&1 & >logfile,表示command的标准输出重定向至文件logfile中,2>&1,匹配n>&m,表示文件描述字2(command的标准错误输出)将copy一份采用文件描述字1(即标准输出),由于标准输出已经重定向logfile,这份copy也见将重定向至文件lofgile。我们可以用“abcd > logfile 2>&1 &”来验证这个效果。最后&表示后台运行的方式。这样命令表示在后台运行command,而它的标准输出和错误输出均重定向到logfile文件中。下面可达到类似的效果: command 2>&1 | tee logfile & 错误输出同样适用标准输出,通过pipe方式,见他们作为输入执行tee logfile。tee命令将它的标准输入copy至他的标准标准输出以及参数所带的文件中。和上面的命令不一眼这里即会在stdout 和logfile中同时输出。 其他文件描述字的重定向,例如<&n,通常用于从多个文件中读入或者写出。