【容器系统】之 大数据容器化-基于Kubernetes构建现代大数据系统
Apache Spark
在大数据处理与分析领域,Apache Spark无疑占据着重要地位。它的特点是基于内存计算,支持各类资源管理平台,其中以YARN最为常见,同时又与Hadoop平台集成,在集群节点以HDFS作为分布式文件存储系统。
我们可以先看一下搭建一个常见的Apache Spark大数据平台需要哪些步骤:
1.安装Hadoop集群
2.配置HDFS
3.配置YARN
4.安装Spark
5.配置Spark与YARN集成
事实上如果参阅官方文档,还有更多细节检查与配置,有过大数据相关领域从业经验的人都知道,要搭建一套可用的大数据环境并不容易,再加上后期维护,就更吃力了,而一套稳定的大数据平台正是进行大数据应用开发的基础。根据笔者了解,有不少公司正是因为大数据平台搭建及配置的复杂性等原因,不得不在多个测试环境中,共用一套大数据平台,这种方式长期看维护成本较高,也可能存在安全隐患。
大数据领域需要一些变化,而Kubernetes的出现则提供了契机。
Kubernete(以下简称k8s)是容器集群管理系统,是一个开源的平台,可以实现容器集群的自动化部署、自动扩缩容、维护等功能。通过Kubernetes你可以:
· 快速部署应用
· 快速扩展应用
· 无缝对接新的应用功能
· 节省资源,优化硬件资源的使用
大数据社区
随着K8s社区的发展壮大,微服务及容器化被越来越多的公司应用到生产环境。与此同时,K8s也成为容器编排的首选平台。大数据社区在容器化进程中当然也是不甘落后的。
Spark自2.3开始官方支持K8sFlink自1.9开始官方支持K8sHue官方Helm chart包Hive以MR3为执行引擎支持K8sAirflow自1.10开始支持K8sPresto支持K8s……
可以看到整个大数据社区也在积极支持容器化,但大数据的容器化并不是生硬地将各个组件搬到K8s上,以Spark on YARN为例,核心组件YARN作为资源调度器,其结构如下图所示
下图讲述了Apache Spark on YARN的工作方式:
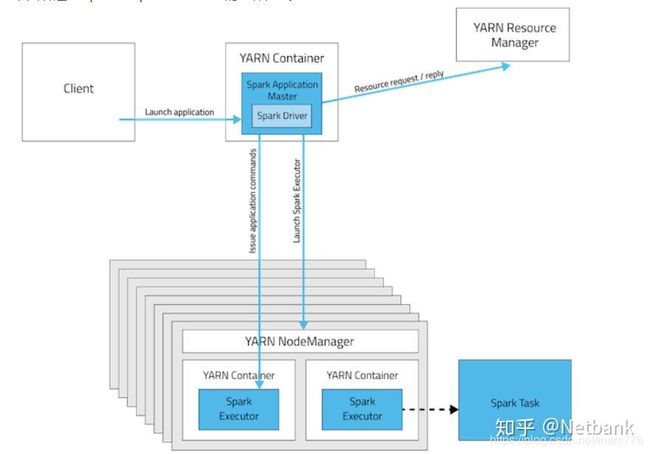
YARN ResourceManager的功能为:
负责集群中所有资源的统一管理和分配,它接收来自各个节点(NodeManager)的资源汇报信息,并把这些信息按照一定的策略分配给各个应用程序
了解K8s的同学可以看出YARN的功能其实与K8s Scheduler的功能非常类似
Kubernetes 调度器是一个策略丰富、拓扑感知、工作负载特定的功能,调度器显著影响可用性、性能和容量。调度器需要考虑个人和集体的资源要求、服务质量要求、硬件/软件/政策约束、亲和力和反亲和力规范、数据局部性、负载间干扰、完成期限等。
所以与其将YARN生搬到K8s中(早期确实是这样做的),何不用K8s调度器替换掉YARN,使得Spark适应K8s呢? 事实上社区确实是在这个方向努力尝试,并且自Spark 2.3开始,实验性支持使用K8s原生Scheduler替代YARN。
spark on k8s:

在该方案中
1.客户端通过spark-submit将任务提交到K8s集群中,并在集群中启动一个Spark Driver Pod;
2.Spark Driver启动相应的Executor Pod, 组成一个Spark Application集群并执行作业任务;
3.任务执行完成后,Executor Pod会被销毁, 而Driver Pod会持久化相关日志,并保持在’completed’状态,直到用户手清理或被K8s集群的垃圾回收机制回收.
Spark原生支持K8s的好处也是很明显的:可以更好的利用K8s的集群资源,通过K8s赋能,更好的进行资源的隔离。这个方案不太友好的地方在于:spark-submit在K8s集群之外,使用非声明式的提交接口,实际使用起来不够友好。
将Spark应用迁移到K8s环境中
Spark Operator是Google基于Operator模式开发的一款的工具, 用于通过声明式的方式向K8s集群提交Spark作业,并且负责管理Spark任务在K8s中的整个生命周期,其工作模式如下

我们可通过Hem安装 spark-operator
$ helm repo add incubator http://storage.googleapis.com/kubernetes-charts-incubator
$ helm install incubator/sparkoperator --namespace spark-operator
创建服务用户及绑定权限
$ kubectl create serviceaccount spark
$ kubectl create clusterrolebinding spark-role --clusterrole=edit --serviceaccount=default:spark --namespace=default
一个典型的Spark应用在K8s中的资源描述文件 spark-pi.yaml 如下所示
apiVersion: "sparkoperator.k8s.io/v1beta2"
kind: SparkApplication
metadata:
name: spark-pi
namespace: default
spec:
type: Scala
mode: cluster
image: "gcr.io/spark-operator/spark:v2.4.4"
imagePullPolicy: Always
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.11-2.4.4.jar"
sparkVersion: "2.4.4"
restartPolicy:
type: Never
volumes:
- name: "test-volume"
hostPath:
path: "/tmp"
type: Directory
driver:
cores: 1
coreLimit: "1200m"
memory: "512m"
labels:
version: 2.4.4
serviceAccount: spark
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
executor:
cores: 1
instances: 1
memory: "512m"
labels:
version: 2.4.4
volumeMounts:
- name: "test-volume"
mountPath: "/tmp"
部署运行
$ kubectl apply -f spark-pi.yaml

计算与存储分离
1.计算与存储耦合存在的问题:当存储或计算其中一方资源不足时,只能同时对两者进行扩容,导致扩容的经济效率比较低(另一种扩容的资源被浪费了);
2.在云计算场景下,不能实现真正的弹性计算,因为计算集群中也有数据,关闭闲置的计算集群会丢失数据。
因为耦合导致的以上这些问题,导致很多公司不得不考虑这种耦合的必要性。而Hadoop的架构设计正是计算与存储耦合,这种设计并不适合云原生架构。而作为大数据存储的基石-HDFS,目前并无官方的K8s解决方案,不过在K8s社区本身就有许多优秀的存储解决方案-MINIO

MinIO 是一个基于Apache License v2.0开源协议的对象存储服务。它兼容亚马逊S3云存储服务接口,非常适合于存储大容量非结构化的数据,例如图片、视频、日志文件、备份数据和容器/虚拟机镜像等,而一个对象文件可以是任意大小,从几kb到最大5T不等。而且实验数据表明,其性能丝毫不逊色于HDFS

安装MINIO也非常容易
$ helm install stable/minio
我们以WordCount,数据读写使用minio存储系统(兼容亚马逊S3云存储服务接口)
JavaRDD textFile = sc.textFile("s3a://...");
JavaPairRDD counts = textFile
.flatMap(s -> Arrays.asList(s.split(" ")).iterator())
.mapToPair(word -> new Tuple2<>(word, 1))
.reduceByKey((a, b) -> a + b);
counts.saveAsTextFile("s3a://...");
由于兼容亚马逊S3云存储服务接口这一优势,minio也同样可以作为Hive数据仓库的可选存储系统。
fs.s3a.path.style.access
true
Enable S3 path style access.
hive.metastore.warehouse.dir
s3a://hive/warehouse
总结
通过以上论述,在K8s集群上搭建Spark大数据平台,相比传统YARN调度方式而言更为简洁,MINIO可作为大数据的存储系统,在保证数据的持久性的同时,也实现了大数据计算系统与存储系统的解耦。