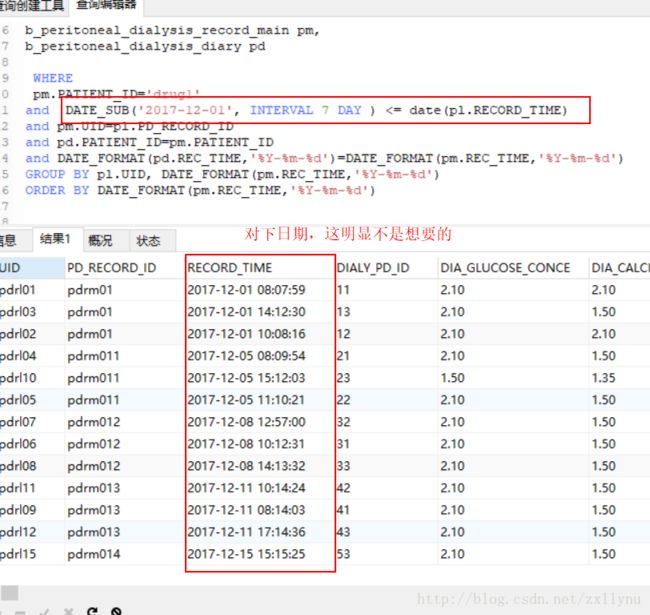
在使用MySQL时,有时需要查询出某个字段不重复的记录,这时可以使用mysql提供的distinct这个关键字来过滤重复的记录,但是实际中我们往往用distinct来返回不重复字段的条数(count(distinct id)),其原因是distinct只能返回他的目标字段,而无法返回其他字段,例如有如下表user:
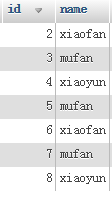
用distinct来返回不重复的用户名:select distinct name from user;,结果为:
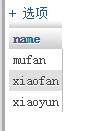
这样只把不重复的用户名查询出来了,但是用户的id,并没有被查询出来:select distinct name,id from user;,这样的结果为:
distinct name,id 这样的mysql 会认为要过滤掉name和id两个字段都重复的记录,如果sql这样写:select id,distinct name from user,这样mysql会报错,因为distinct必须放在要查询字段的开头。
所以一般distinct用来查询不重复记录的条数。
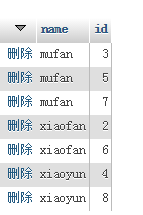
如果要查询不重复的记录,有时候可以用group by :
select id,name from user group by name;
4、为了防止查询的数据库中字段为空,可以使用ifnull(名称,默认值)的形式进行处理
select ifnull(pt,0) pt from b_medical_worker a where a.UID = ?",did);
5、下面一句是为了查询一某医生值班时其所在医院中当天,当天患者的总数
具体为b_shedual表中有患者id 医院id 排班时段id
b_medical_worker中为医生作为医护人员的表,有医生id和其所在的医院id
Record d = Db.findFirst("select count(*) sl from b_schedual a\n" + "where a.HOS_ID = (select hos_id from b_medical_worker where UID = ?)",uid
nid);
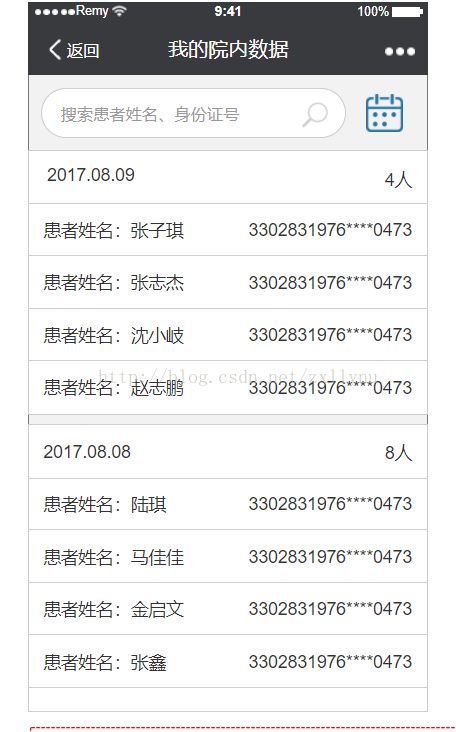
6、mysql中按照日期分组查询单表所有数据,并统计每天的数据量,欲达到如下效果
开始时,没有使用时间格式化函数,查出来的数据一直显示是一条排列,后在查询资料的途中,突然意识到所有的都是一个,是因为数据库中我查找的时间字段精确到了秒,而秒是不一样的
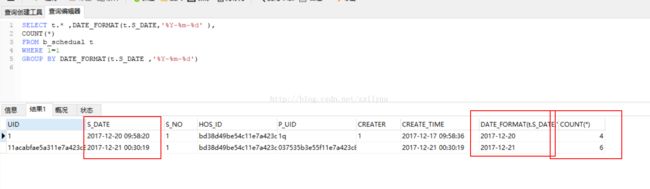
SELECT t.* ,DATE_FORMAT(t.S_DATE,'%Y-%m-%d' ),
COUNT(*)
FROM b_schedual t
WHERE 1=1
GROUP BY DATE_FORMAT(t.S_DATE ,'%Y-%m-%d');
(注:t.* 表示我要查询所有列,date_format() 为格式化时间的函数, t.S_DATE 是我要操作的表“b_shedual”中表示时间的字段,%Y-%m-%d 表示将日期格式化到日,%Y-%m-%d-%H 表示将时间格式化到小时,以此类推 )
最终结果为
7、mysql,怎么根据一个时间段,然后查询出这个时间段的全部时间??
drop procedure if exists test;8、
create procedure test(in start datetime)
begin
drop table if exists tmp;
create TEMPORARY table tmp (date datetime);
set @stop=date_add(start,INTERVAL -7 day);
while start >= @stop DO
insert into tmp values(start);
set start=date_add(start,interval -1 day);
end while;
select * from tmp;
end;
这个是需要循环的,以上帮你写了一个存储过程,创建后,执行call test('2016-01-08'),可以帮你列出你所需的答案。
比如
id name age
1 zhang 20
2 li 10
3 wang 20
4 chen 20
5 zhao 18
如上表 将年龄分组 某个年龄段最多的排在前面,依次排列下去?
|
1
2
3
4
5
6
7
8
9
10
11
|
SELECT
COUNT
(
DISTINCT
user_id) user_count,
CASE
WHEN
age <= 10
THEN
'0-10'
WHEN
age > 10
AND
age <= 20
THEN
'10-20'
WHEN
age > 20
AND
age < 30
THEN
'10-30'
END
AS
`age
FROM
tableName
GROUP
BY
age
ORDER
BY
age
desc
|
9、在下面的计算某天在一周 一个月 一年的第几天时,特别注意一个问题:
weekday(date) 中的date 格式好像有一定的要求,据其他资料说是必须是datetime 格式和某格式才行,
开始时我因为之前的语句需要用到date_format(表名.createDate,'%Y-%M-%d'),
复制粘贴过来的,所以刚开始时我写的是weekday(date_format(表名.createDate,'%Y-%M-%d'))weekDay,
结果在搜索结果中字段 weekDay 总是为空,当我将语句改为weekday(表名.createDate)时结果出来了!!!!
3. MySQL dayof... 函数:dayofweek(), dayofmonth(), dayofyear()
分别返回日期参数,在一周、一月、一年中的位置。
set @dt = '2008-08-08';
select dayofweek(@dt); -- 6
select dayofmonth(@dt); -- 8
select dayofyear(@dt); -- 221
日期 '2008-08-08' 是一周中的第 6 天(1 = Sunday, 2 = Monday, ..., 7 = Saturday);一月中的第 8 天;一年中的第 221 天。
4. MySQL week... 函数:week(), weekofyear(), da
select
(@i:=@i+1) i,
D.*
FROM
(
select
a.patient_id,a.dt,
/*周数*/
weekofyear(a.dt) weeks,
/*周开始日期*/
adddate(CONCAT(DATE_FORMAT(a.dt,'%Y'),'0101'),(weekofyear(a.dt)-1)*7) week_st,
/*周结束日期*/
adddate(CONCAT(DATE_FORMAT(a.dt,'%Y'),'0101'),weekofyear(a.dt)*7-1) week_ed,
/*是否有预警*/
count(b.UID) sl
FROM
(SELECT @i:=0) as i,
(
select a.PATIENT_ID,DATE_FORMAT(a.rec_time,'%Y-%m-%d') dt from b_peritoneal_dialysis_diary a
left join b_peritoneal_dialysis_record_main b
on (a.PATIENT_ID = b.PATIENT_ID
and DATE_FORMAT(a.rec_time,'%Y-%m-%d') = DATE_FORMAT(b.rec_time,'%Y-%m-%d'))
union
select a.PATIENT_ID,DATE_FORMAT(a.rec_time,'%Y-%m-%d') dt from b_peritoneal_dialysis_diary a
right join b_peritoneal_dialysis_record_main b
on (a.PATIENT_ID = b.PATIENT_ID
and DATE_FORMAT(a.rec_time,'%Y-%m-%d') = DATE_FORMAT(b.rec_time,'%Y-%m-%d'))
) a left join b_alert b
on(a.PATIENT_ID = B.P_UID AND A.DT = DATE_FORMAT(b.ALERT_TIME,'%Y-%m-%d'))
where a.PATIENT_ID='drug1'
group by a.patient_id,weeks
)D
order by i DESC;yofweek(), weekday(), yearweek()
set @dt = '2008-08-08';
select week(@dt); -- 31
select week(@dt,3); -- 32
select weekofyear(@dt); -- 32
select dayofweek(@dt); -- 6
select weekday(@dt); -- 4
select yearweek(@dt); -- 200831
MySQL week() 函数,可以有两个参数,具体可看手册。 weekofyear() 和 week() 一样,都是计算“某天”是位于一年中的第几周。 weekofyear(@dt) 等价于 week(@dt,3)。
MySQL weekday() 函数和 dayofweek() 类似,都是返回“某天”在一周中的位置。不同点在于参考的标准, weekday:(0 = Monday, 1 = Tuesday, ..., 6 = Sunday); dayofweek:(1 = Sunday, 2 = Monday, ..., 7 = Saturday)
MySQL yearweek() 函数,返回 year(2008) + week 位置(31)。
10、 工作中为了实现如下效果,需要用到为MySQL数据查询结果添加自增字段,且需要获取查询表所在结果的一个日期所在周的一周的开始日期和结束日期,因为需要为查询结果定位,所以还需要对周数进行打标记符

select
(@i:=@i+1) i,
D.*
FROM
(
select
a.patient_id,a.dt,
/*周数*/
weekofyear(a.dt) weeks,
/*周开始日期*/
adddate(CONCAT(DATE_FORMAT(a.dt,'%Y'),'0101'),(weekofyear(a.dt)-1)*7) week_st,
/*周结束日期*/
adddate(CONCAT(DATE_FORMAT(a.dt,'%Y'),'0101'),weekofyear(a.dt)*7-1) week_ed,
/*是否有预警*/
count(b.UID) sl
FROM
(SELECT @i:=0) as i,
(
select a.PATIENT_ID,DATE_FORMAT(a.rec_time,'%Y-%m-%d') dt from b_peritoneal_dialysis_diary a
left join b_peritoneal_dialysis_record_main b
on (a.PATIENT_ID = b.PATIENT_ID
and DATE_FORMAT(a.rec_time,'%Y-%m-%d') = DATE_FORMAT(b.rec_time,'%Y-%m-%d'))
union
select a.PATIENT_ID,DATE_FORMAT(a.rec_time,'%Y-%m-%d') dt from b_peritoneal_dialysis_diary a
right join b_peritoneal_dialysis_record_main b
on (a.PATIENT_ID = b.PATIENT_ID
and DATE_FORMAT(a.rec_time,'%Y-%m-%d') = DATE_FORMAT(b.rec_time,'%Y-%m-%d'))
) a left join b_alert b
on(a.PATIENT_ID = B.P_UID AND A.DT = DATE_FORMAT(b.ALERT_TIME,'%Y-%m-%d'))
where a.PATIENT_ID='drug1'
group by a.patient_id,weeks
)D
order by i DESC;