prometheus+grafana
Prometheus 是使用 Golang 开发的开源监控系统,被人称为下一代监控系统,是为数不多的适合 Docker、Mesos 、Kubernetes 环境的监控系统之一 。
Grafana 是一个开源的图表可视化系统,简言之,其特点在于图表配置比较方便、生成的图表漂亮。
Prometheus + Grafana 监控系统的组合中,前者负责采样数据并存储这些数据;后者则侧重于形象生动的展示数据。
概念
Prometheus 是源于 Google Borgmon 的一个系统监控和报警工具。基本原理是通过 HTTP 协议周期性地抓取被监控组件的状态(pull 方式),这样做的好处是任意组件只要提供 HTTP 接口就可以接入监控系统,不需要任何 SDK 或者其他的集成过程。
这样做非常适合虚拟化环境比如 VM 或者 Docker ,故其为为数不多的适合 Docker、Mesos 、Kubernetes 环境的监控系统之一,被很多人称为下一代监控系统。
像QPS和响应时间这些数据,外部工具是没办法直接拿到的,必须要服务器以某种方式将数据暴露出来。最常见的做法是写日志。比如Nginx,每一条请求对应一个日志,日志中有响应时间这个字段。通过对日志分析,我们就可以得到QPS,最大响应时间,平均响应时间等,再通过可视化工具即可绘制我们想要的Dashboard。
日志这个方法固然是可行的,但是还有更好的方法。这个方法就是时序数据库(Time Series Database)。时序数据库简单来说就是存储随时间变化的数据的数据库。什么是随时间变化的数据呢?举个简单的例子,比如,CPU使用率,典型的随时间变化的量,这一秒是50%,下一秒也许就是80%了。
metrics name & label 指标名称和标签
每条时间序列是由唯一的 指标名称 和 一组 标签 (key=value)的形式组成。
指标名称 一般是给监测对像起一名字,例如 http_requests_total 这样,它有一些命名规则,可以包字母数字_之类的的。
通常是以应用名称开头_监测对像_数值类型_单位这样。
安装(两种方式)
1.下载
https://prometheus.io/download/ (darwin是苹果系统)或者docker pull prom/prometheus
2.运行
./prometheus --config.file=prometheus.yml &(后台运行)
如果要使用不同于9090的端口号,可以在命令行参数 --web.listen-address中指定,如:
./prometheus --config.file=prometheus.yml --web.listen-address=:9091 &
可以查看查看prometheus命令
./prometheus -h
docker 运行方式
docker run -d --name=prometheus -p 9091:9090 -v 挂载配置文件:/etc/prometheus/prometheus.yml prom/prometheus --config.file=/etc/prometheus/prometheus.yml
在浏览器打开 http://localhost:9091/metrics就能看到prometheus的指标了
直接打开http://localhost:9091就能看见指标查询页面

3.配置文件prometheus.yml的解析
 scrape_interval代表所有监控应用默认pull时间
scrape_interval代表所有监控应用默认pull时间
evaluation_interval代表应用默认更新rules文件的周期,默认为1min
scrape_timeout: 15s # 设定抓取数据的超时时间,默认为10s
rule_files:数组中加载的触发AlertManager模块的条件
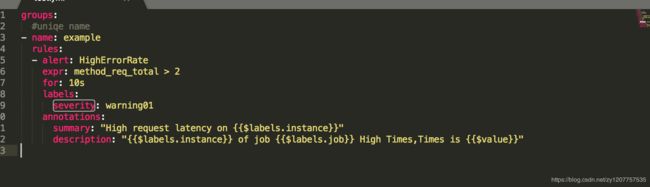
alert:预警名
expr:条件
for:条件满足后持续xx时间后触发(状态:inactive-》panding-》firing)
1)inactive:表示当前报警信息即不是firing状态也不是pending状态
2)pending:表示在设置的阈值时间范围内被激活的
3)firing:表示超过设置的阈值时间被激活的
severity:标签对应alertManager的标签(触发对应的通知目标)
图为alertManager.yml的配置

scrape_configs数组下每个job_name代表一个应用
scrape_configs:
# job_name默认写入timeseries的labels中,可以用于查询使用,job名不能重复
- job_name: 'mPrometheus'
# metrics_path defaults to '/metrics'
//可以设置应用指标的路径 默认为'/metrics'
metrics_path: "/myPrometheus/prometheus01"
static_configs:
//应用暴露的端口 可以监控多个targets: ['localhost:9090','localhost:9092']
- targets: ['localhost:9090']
例如在spring中暴露端口

![]()
在springboot中,端口是默认开启9090

检查应用是否开启成功 -》localhost:9090/metrics是否正常打开
AlertManager
Alertmanager与Prometheus是相互分离的两个部分。Prometheus服务器根据报警规则将警报发送给Alertmanager,然后Alertmanager将silencing、inhibition、aggregation等消息通过电子邮件、webhoob等发送通知。
1.安装
https://github.com/prometheus/alertmanager/releases或者docker pull prom/alertmanager
2.运行
./alertmanager --config.file=./alertmanager.yml 或者
docker run -d -p 9093:9093 -v xxx:/etc/alertmanager.yml --name=alertmanager prom/alertmanager --config.file=/etc/alertmanager.yml
查看web页面localhost:9093
3.配置alertmanager.yml
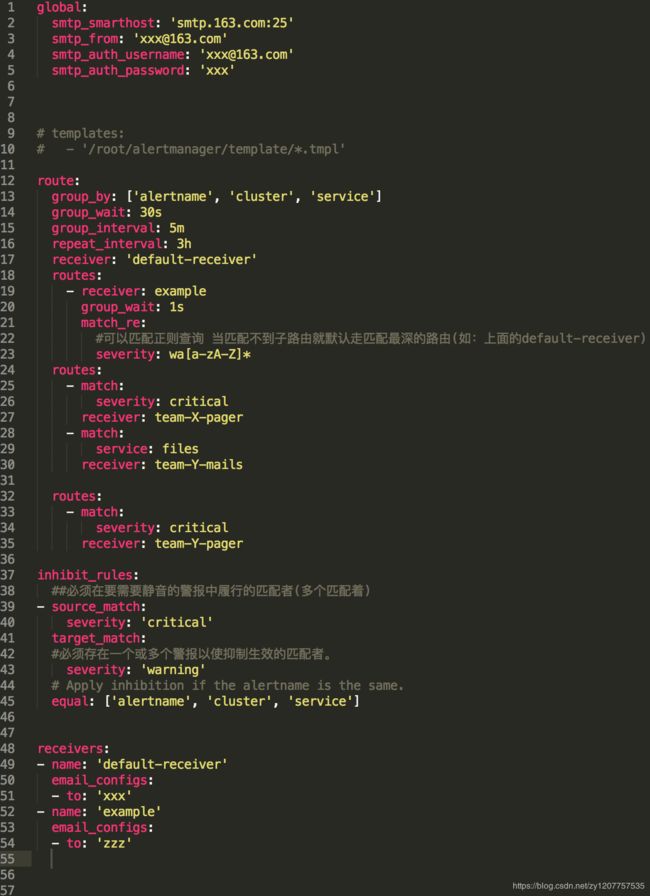
group_by:对警报分组,
group_wait:当触发新报警时,等待时间,30s内组合这个group中接收的所有报警一起发送预警
gourp_interval:设置控制在分派同一组的进一步通知之前等待多长时间,并且从上次发送的通知开始计算时间间隔。(再来改组预警时等待多久预警才能触发)
repeat_interval:已有的Group等待group_interval指定的时间,判断Alert是否解决,(没有解决时)当上次发送通知到现在的间隔大于repeat_interval或者Group有更新时会发送通知
receiver: 'xxx'对应receivers中name:'xxx' 当找不到匹配时默认触发root节点
route下receiver 对应receivers下name ,severity对应从prometheuspush过来的报警文件中severity对应
inhibit_relus:抑制是指当警报发出后,停止重复发送由此警报引发其他错误的警报的机制。
例如,当警报被触发,通知整个集群不可达,可以配置Alertmanager忽略由该警报触发而产生的所有其他警报(提高警报信息的友好性)。
优质警报模板alertmanager:
https://github.com/prometheus/alertmanager/blob/master/doc/examples/simple.yml
如果想配置发送模板
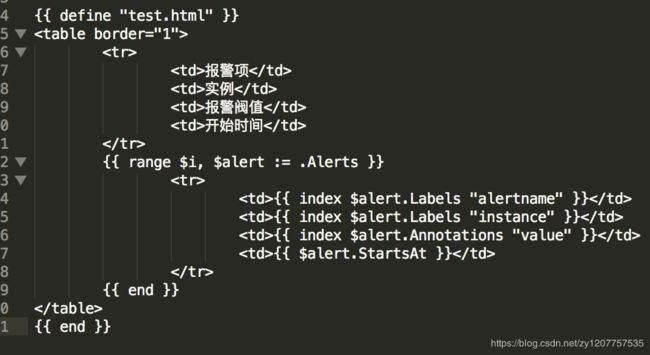
并需要在配置文件中引入
- to: '******@163.com' # 接收警报的email配置
html: '{{ template "test.html" . }}' # 设定邮箱的内容模板
headers: { Subject: "[WARN] 报警邮件"} # 接收邮件的标题
先启alertmanager(暴露端口)再启prometheus
Grafana
grafana 是一个开源的时序性统计和监控平台,支持例如prometheus、 elasticsearch、graphite、influxdb 等众多的数据源,并以功能强大的界面编辑器著称。
grafana 的权限分为三个等级:Viewer、Editor 和 Admin,Viewer 只能查看 grafana 已经存在的面板而不能编辑,Editor 可以编辑面板,Admin 则拥有全部权限例如添加数据源、添加插件、增加 API KEY。
1.安装
安装grafana
https://grafana.com/grafana/download
wget https://dl.grafana.com/oss/release/grafana-5.4.2.darwin-amd64.tar.gz
或者 docker pull grafana/grafana
2.启动
./bin/grafana-server start &
或者docker run -d -p 3000:3000 -v xxx:/etc/grafana/sample.ini --name=grafana grafana/grafana --config=/etc/grafana/sample.ini
可以设置读取文件 -config="xxx/sample.ini"
3.查看
localhost:3000
初始用户名和密码:admin
4.配置prometheus 数据源

save & test测试是否连接prometheus成功
添加dashborad
还有一些对仪表盘显示的设置。
grafana也有Alerting功能(在4.0及以上)
邮件形式预警需在配置文件中配置
[smtp]
enabled = true
host =smtp.163.com:25
user=xxx
password=x'xx
skip_verify=true
from_name=xxx
重启
接着配置
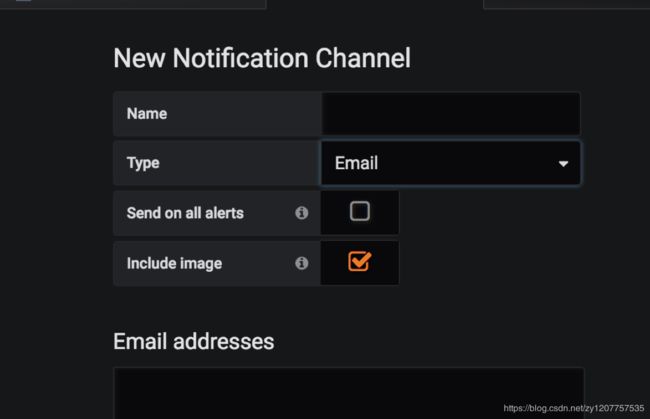
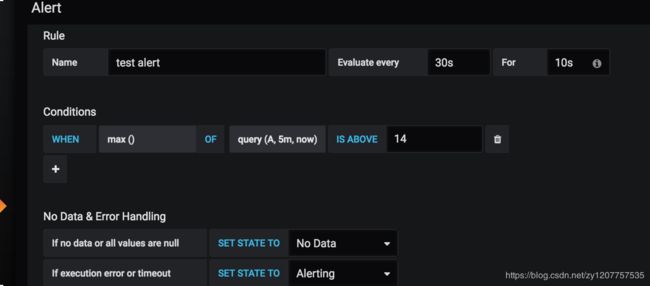
evaluate every 代表每多久检查一下
for 代表当超过阀值,持续多少秒就把邮件
conditions是条件
A代表第几个PromQL条件
也可以以webhook的方式指定一个url接收数据