编程环境:
anaconda + Spyder
Win10 + python3.6
完整代码及数据已经更新至GitHub,欢迎fork~GitHub链接
声明:创作不易,未经授权不得复制转载
statement:No reprinting without authorization
内容概述:
任务:
• 实现Pivoted Length Normalization VSM;
• 实现BM25;
注意
• 改进Postings:(docID, Freq),不仅记录单词所在的文档ID,也记录其在文档中的Frequency;
• 构建inverted index时,记录文档的长度,以及计算average document length (avdl)
一、对推特数据的处理和对postings等一些数据结构的增加与改善
对推特数据文本的处理与实验三相同,只保留用户名、tweet内容以及用来作为文档id的tweetid,修改postings的结构,添加TF的信息,保存每个单词在每条tweet中的词频信息,tf = postings[term][tweeted],打印后如下所示:
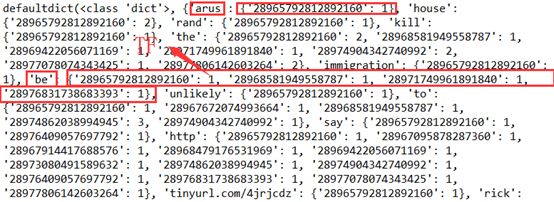
添加其它需要的数据结构来分别记录DF、文档长度(tweet词数)、文档数量和文档平均长度(词数):
postings = defaultdict(dict)
document_frequency = defaultdict(int)
document_lengths= defaultdict(int)
document_numbers = len(document_lengths)
avdl=0
文档长度(每条tweet词数)的数据结构如下所示:
get_postings_dl()
initialize_document_frequencies()
initialize_avdl()
二、PLN_VSM和BM25的具体实现应用
首先依旧是利用已有数据结构实现查询的功能,对于输入的一串语句,进行相同的token处理,而后为了加快检索速率,避免去遍历所有tweet计算每一个F(q,d),可以先对于查询检索提取出相关的tweetid,得到relevant_tweetids列表,然后利用PLN和BM25的方法分别计算他们的分数最后降序输出。
核心search方法如下:
def do_search():
query = token(input("Search query >> "))
if query == []:
sys.exit()
unique_query = set(query)
#避免遍历所有的tweet,可先提取出有相关性的tweetid,tweet中包含查询的关键词之一便可认为相关
relevant_tweetids = Union([set(postings[term].keys()) for term in unique_query])
#print(relevant_tweetids)
if not relevant_tweetids:
print ("No tweets matched any query terms.")
else:
scores1 = sorted([(id,similarity_PLN(query,id))
for id in relevant_tweetids],
key=lambda x: x[1],
reverse=True)
scores2 = sorted([(id,similarity_BM25(query,id))
for id in relevant_tweetids],
key=lambda x: x[1],
reverse=True)
print ("<<<<>>>>")
print("PLN一共有"+str(len(scores1))+"条相关tweet!")
for (id,score) in scores1:
print (str(score)+": "+id)
print ("<<<<>>>>")
print("BM25一共有"+str(len(scores2))+"条相关tweet!")
for (id,score) in scores2:
print (str(score)+": "+id)
其中similarity_PLN(query,id)和similarity_BM25(query,id)分别使用PLN和BM25的公式来计算,具体如下:

对于PLN中的参数b,由于每条tweet的次数有限,平均每条18个词左右(加上用户名),因此不同文档的长度不会相差太多,对于文档长度低于(或高于)平均长度的奖励 (或惩罚)比重不宜太大, 经过实验发现设为0.1便可满足需求。

对于BM25模型,基于同样原理,其比重不应太大,于是将k设为1,b同样设为0.1.
def similarity_PLN(query,id):
global postings,avdl
fenmu =1 - 0.1 + 0.1*(document_lengths[id]/avdl)
similarity = 0.0
unique_query = set(query)
for term in unique_query:
if (term in postings) and (id in postings[term].keys()):
#使用ln(1+ln(C(w,d)+1))后发现相关性的分数都为负数很小
similarity += (query.count(term)*(math.log(math.log(postings[term][id] + 1) + 1)) *math.log((document_numbers+1)/document_frequency[term]))/fenmu
return similarity
def similarity_BM25(query,id):
global postings,avdl
fenmu =1 - 0.1 + 0.1*(document_lengths[id]/avdl)
k = 1
similarity = 0.0
unique_query = set(query)
for term in unique_query:
if (term in postings) and (id in postings[term].keys()):
C_wd = postings[term][id]
#使用ln(1+ln(C(w,d)+1))后发现相关性的分数都为负数很小
similarity += (query.count(term)*(k+1)*C_wd*math.log ((document_numbers+1)/document_frequency[term]))/(k*fenmu+C_wd)
return similarity
三、进行查询测评比较
选取三条查询输入,观察两种方法各自返回的tweetid列表:
(1)
 image.png
image.png

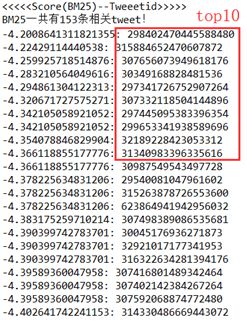
两者前十个中有9个相同,顺序略有不同!
(2)
 image.png
image.png
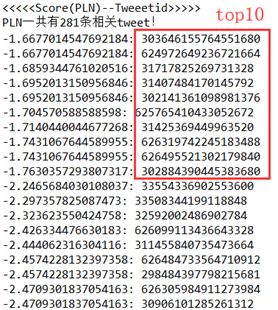

两者前10个结果完全一样,并且顺序一致!
(3)
 image.png
image.png


前10个结果完全一样,并且顺序一致!
综上比较可以发现,两种方法的效果十分接近,但具体哪一种的效率或准确率更好,还有待进一步的测评。
四、更新用qrels.txt和eval_hw4.py对检索模型的结果进行评测:
1、利用提供的result.txt进行演示(baseline?)


刚开始由于弄混了升序和降序(sorted函数中的reverse参数),导致结果很低,调整后结果如下:
1、使用PLN结构的结果如下:
(1) PLN result 01(b = 0.1):
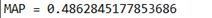 image.png
image.png image.png
image.png
(2) PLN result 01(b = 0.2):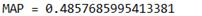 image.png
image.png image.png
image.png
B = 0.1时有更好表现
2、使用BM25结构的结果如下:
(1) BM25 result 01(k = 1,b = 0.1):
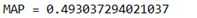 image.png
image.png image.png
image.png
(2) BM25 result 02(k = 2,b = 0.1):
 image.png
image.png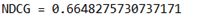 image.png
image.png
(3) BM25 result 03(k = 1,b = 0.2):
 image.png
image.png image.png
image.png
(4) BM25 result 04(k = 1,b = 0.3):
 image.png
image.png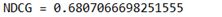 image.png
image.png
综上可以发现k=1,b=0.2时有最好表现,MAP = 0.491,NDCG = 0.684
3、综合PLN和BM25:
 image.png
image.png image.png
image.png
发现并没有好多少与单独使用单一结构相近
声明:创作不易,未经授权不得复制转载
statement:No reprinting without authorization