9.8.3 消除缺失的编号
编写一个程序, 在一个文件夹中, 找到所有带指定前缀的文件, 诸如spam001.txt, spam002.txt 等,并定位缺失的编号( 例如存在 spam001.txt 和 spam003.txt,但不存在 spam002.txt)。让该程序对所有后面的文件改名,消除缺失的编号。
#! python3
import shutil, os, re
def sortFileName(folder):
# 查找并提取原始文件名路径列表
originTextFile = []
for foldername, subfolders, filenames in os.walk(folder):
for filename in filenames:
if re.compile(r'^spam(\d){3}\.txt$').search(filename):
originTextFile.append(os.path.join(foldername, filename))
# 建立目标序列文件名路径列表
totalNum = []
newTextFile = []
for i in range(1, len(originTextFile) + 1):
totalNum.append('%03d' % i)
newTextFile.append(os.path.join(foldername, 'spam' + totalNum[-1] + '.txt'))
# 对文件改名以消除缺失的编号
for index in range(0, len(originTextFile)):
shutil.move(originTextFile[index], newTextFile[index])
print('Done.')
sortFileName('.')
12.13.1 乘法表
创建程序 multiplicationTable.py,从命令行接受数字 N,在一个 Excel 电子表格
中创建一个 N×N 的乘法表。例如,如果这样执行程序:
py multiplicationTable.py 6
它应该创建一个图 12-11 所示的电子表格。
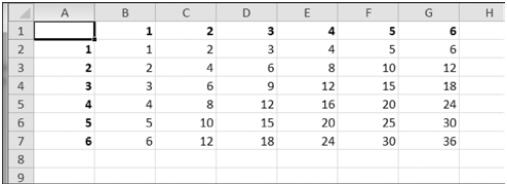
行 1 和列 A 应该用做标签,应该使用粗体。
#! python3
import sys, openpyxl
from openpyxl.styles import Font
n = int(sys.argv[1])
wb = openpyxl.Workbook()
sheet = wb.active
font = Font(bold = True)
for rowNum in range(2, n + 2):
sheet.cell(row = rowNum, column = 1).font = font
sheet.cell(row = rowNum, column = 1).value = rowNum - 1
for colNum in range(2, n + 2):
sheet.cell(row = 1, column = colNum).font = font
sheet.cell(row = 1, column = colNum).value = colNum - 1
for x in range(2, n + 2):
for y in range(2, n + 2):
sheet.cell(row = x, column = y).value = (x - 1) * (y - 1)
wb.save('multiplicationTable.xlsx')
print('Done.')
12.13.2 空行插入程序
创建一个程序 blankRowInserter.py,它接受两个整数和一个文件名字符串作为
命令行参数。我们将第一个整数称为 N,第二个整数称为 M。程序应该从第 N 行开
始,在电子表格中插入 M 个空行。例如,如果这样执行程序:
python blankRowInserter.py 3 2 myProduce.xlsx
执行之前和之后的电子表格,应该如图 12-12 所示。

程序可以这样写:读入电子表格的内容,然后在写入新的电子表格时,利用 for
循环拷贝前面 N 行。对于剩下的行,行号加上 M,写入输出的电子表格。
#! python3
import openpyxl, sys
n = int(sys.argv[1])
m = int(sys.argv[2])
excelFilename = sys.argv[3]
wb = openpyxl.load_workbook(excelFilename)
sheet = wb.active
sheet1 = wb.create_sheet(title = 'Sheet1')
for row in range(1, n):
for col in range(1, sheet.max_column + 1):
sheet1.cell(row = row, column = col).value = sheet.cell(row = row, column = col).value
for row in range(n, sheet.max_row + 1):
for col in range(1, sheet.max_column + 1):
sheet1.cell(row = row + m, column = col).value = sheet.cell(row = row, column = col).value
wb.save(excelFilename)
print('Done.')
13.6.1 PDF 偏执狂
利用第 9 章的 os.walk()函数编写一个脚本,遍历文件夹中的所有 PDF(包含子文件夹),用命令行提供的口令对这些 PDF 加密。用原来的文件名加上_encrypted.pdf后缀,保存每个加密的 PDF。在删除原来的文件之前,尝试用一个程序读取并解密该文件,确保它被正确的加密。
然后编写一个程序,找到文件夹中所有加密的 PDF 文件(包括它的子文件夹),利用提供的口令,创建 PDF 的解密拷贝。如果口令不对,程序应该打印一条消息,并继续处理下一个 PDF 文件。
#! python3
# 使用方法:python *.py 加密口令
import PyPDF2, os, sys
# 利用os.walk()函数编写一个脚本,遍历文件夹中的所有 PDF(包含子文件夹)
path = 'C:\\folder' # 文件夹路径
for folderName, subfolders, filenames in os.walk(path):
for filename in filenames:
if filename.endswith('.pdf'):
# 用命令行提供的口令对这些 PDF 加密。
pdfFile = open(folderName + '\\' + filename, 'rb') # 文件绝对路径
pdfReader = PyPDF2.PdfFileReader(pdfFile)
pdfWriter = PyPDF2.PdfFileWriter()
for pageNum in range(pdfReader.numPages):
pdfWriter.addPage(pdfReader.getPage(pageNum))
print('encrypting...')
pdfWriter.encrypt(sys.argv[1]) # 获取口令并加密
# 用原来的文件名加上_encrypted.pdf后缀,保存每个加密的 PDF。
resultPdf = open(folderName + '\\' + filename[:-4] + '_encrypted.pdf', 'wb')
pdfWriter.write(resultPdf)
resultPdf.close()
pdfFile.close()
# 在删除原来的文件之前,尝试用一个程序读取并解密该文件,确保它被正确的加密。
encryptedPdfReader = PyPDF2.PdfFileReader(open(folderName + '\\' + filename[:-4] + '_encrypted.pdf', 'rb'))
if encryptedPdfReader.isEncrypted and encryptedPdfReader.decrypt(sys.argv[1]):
print(filename + ' is encrypted.')
print('deleting... ' + filename)
os.unlink(folderName + '\\' + filename)
else:
print(filename + ' is not encrypted or wrong password.')
else:
continue
print('Done.')
#! python3
# 使用方法:python *.py 解密口令
import PyPDF2, os, sys
# 然后编写一个程序,找到文件夹中所有加密的 PDF 文件(包括它的子文件夹)
path = 'C:\\folder' # 文件夹路径
for folderName, subfolders, filenames in os.walk(path):
for filename in filenames:
if filename.endswith('.pdf'):
# 利用提供的口令,创建 PDF 的解密拷贝。
pdfFile = open(folderName + '\\' + filename, 'rb') # 文件绝对路径
pdfReader = PyPDF2.PdfFileReader(pdfFile)
if pdfReader.isEncrypted:
if pdfReader.decrypt(sys.argv[1]):
print(filename + ' is decrypted.')
pdfWriter = PyPDF2.PdfFileWriter()
for pageNum in range(pdfReader.numPages):
pdfWriter.addPage(pdfReader.getPage(pageNum))
resultPdf = open(folderName + '\\' + filename[:-4] + '_decrypted.pdf', 'wb')
pdfWriter.write(resultPdf)
resultPdf.close()
pdfFile.close()
# 如果口令不对,程序应该打印一条消息,并继续处理下一个 PDF 文件。
else:
print('wrong password!')
else:
continue
print('Done.')
13.6.3 暴力 PDF 口令破解程序
假定有一个加密的 PDF 文件,你忘记了口令,但记得它是一个英语单词。尝试猜测遗忘的口令是很无聊的任务。作为替代,你可以写一个程序,尝试用所可能的英语单词来解密这个 PDF 文件,直到找到有效的口令。这称为暴力口令攻击。从http://nostarch.com/automatestuff/下载文本文件 dictionary.txt。这个字典文件包含 44000多个英语单词,每个单词占一行。
利用第 8 章学过的文件读取技巧来读取这个文件,创建一个单词字符串的列表。然后循环遍历这个列表中的每个单词,将它传递给 decrypt()方法,如果这个方法返回整数 0,口令就是错的,程序应该继续尝试下一个口令。如果 decrypt()返回 1,程序就应该终止循环,打印出破解的口令。你应该尝试每个单词的大小写形式(在我的笔记本上,遍历来自字典文件的所有 88000 个大小写单词,只要几分钟时间。这就是不应该使用简单英语单词作为口令的原因)。
#! python3
import PyPDF2
def Decrypt(word):
if pdfReader.decrypt(word):
print('Password is %s' % word)
return -1
elif pdfReader.decrypt(word.lower()):
print('Password is %s' % word.lower())
return -1
else:
return 0
dictFilePath = 'C:\\dictFilename.txt' # 字典文件绝对路径
dictFile = open(dictFilePath)
wordList = dictFile.read().split('\n')
dictFile.close()
pdfFilePath = 'C:\\pdfFilename.pdf' # PDF文件绝对路径
pdfReader = PyPDF2.PdfFileReader(open(pdfFilePath, 'rb'))
if pdfReader.isEncrypted:
print('Decrypting...')
for word in wordList:
if Decrypt(word):
break
else:
continue
else:
print('This PDF file is not encrypted.')
14.8.1 Excel 到 CSV 的转换程序
Excel 可以将电子表格保存为 CSV 文件,只要点几下鼠标,但如果有几百个 Excel文件要转换为 CSV,就需要点击几小时。利用第 12 章的 openpyxl 模块, 编程读取当前工作目录中的所有 Excel 文件,并输出为 CSV 文件。
一个 Excel 文件可能包含多个工作表,必须为每个表创建一个 CSV 文件。 CSV文件的文件名应该是
从 http://nostarch.com/automatestuff/下载 ZIP 文件 excelSpreadsheets.zip,将这些电子表格解压缩到程序所在的目录中。可以使用这些文件来测试程序。
#! python3
import openpyxl, csv, os
for excelFile in os.listdir('.'):
# Skip non-xlsx files, load the workbook object.
if excelFile.endswith('.xlsx'):
wb = openpyxl.load_workbook(excelFile)
for sheetName in wb.sheetnames:
# Loop through every sheet in the workbook.
sheet = wb[sheetName]
# Create the CSV filename from the Excel filename and sheet title.
csvFile = open(os.path.join(excelFile[:-5] + '_' + sheetName + '.csv'), 'w', newline = '')
# Create the csv.writer object for this CSV file.
csvWriter = csv.writer(csvFile)
# Loop through every row in the sheet.
for rowNum in range(1, sheet.max_row + 1):
rowData = [] # append each cell to this list
# Loop through each cell in the row.
for colNum in range(1, sheet.max_column + 1):
# Append each cell's data to rowData.
rowData.append(sheet.cell(row = rowNum, column = colNum).value)
# Write the rowData list to the CSV file.
csvWriter.writerow(rowData)
csvFile.close()
print('Done.')
15.12.1 美化的秒表
扩展本章的秒表项目,让它利用 rjust()和 ljust()字符串方法来“美化”的输出。(这些方法在第 6 章中介绍过)。输出不是像这样:
Lap #1: 3.56 (3.56)
Lap #2: 8.63 (5.07)
Lap #3: 17.68 (9.05)
Lap #4: 19.11 (1.43)
…而是像这样:
Lap # 1: 3.56 ( 3.56)
Lap # 2: 8.63 ( 5.07)
Lap # 3: 17.68 ( 9.05)
Lap # 4: 19.11 ( 1.43)
请注意,对于 lapNum、 lapTime 和 totalTime 等整型和浮点型变量,你需要字符串版本,以便对它们调用字符串方法。接下来,利用第 6 章中介绍的 pyperclip 模块,将文本输出复制到剪贴板,以便用户可以将输出快速粘贴到一个文本文件或电子邮件中。
#! python3
import time, pyperclip
# Display the program's instructions.
print('Press ENTER to begin. Afterwards, press ENTER to "click" the stopwatch. Press Ctrl-C to quit.')
input() # press Enter to begin
print('Started.')
startTime = time.time() # get the first lap's start time
lastTime = startTime
lapNum = 1
copyList = []
# Start tracking the lap times.
try:
while True:
input()
lapTime = round(time.time() - lastTime, 2)
totalTime = round(time.time() - startTime, 2)
result = 'Lap #%s: %s (%s)' % (str(lapNum).rjust(2), str(totalTime).rjust(6), str(lapTime).rjust(5))
print(result, end='')
copyList.append(result)
lapNum += 1
lastTime = time.time() # reset the last lap time
except KeyboardInterrupt:
# Handle the Ctrl-C exception to keep its error message from displaying.
print('\nDone.')
pyperclip.copy('\n'.join(copyList))
环境:python3