数据结构和算法学习之路——链表详解(C++版)
数据结构之线性表(链表)详解——(C++语言)
The reasonable man adapts himself to the world; the unreasonable one persists in trying to adapt the world to himself. —— Bernard Shaw
明白事理的人使自己适应世界;不明事理的人想使世界适应自己。
文章目录
- 数据结构之线性表(链表)详解——(C++语言)
- (一) 关于线性表
- 1.1 线性表的基本概念
- (二) 关于链表
- 2.1 链表的基本概念
- 2.2 结点的结构表示
- 2.3 单链表的基本操作
- 2.3.1 单链表的创建
- 2.3.2 单链表的遍历
- 2.3.3 单链表的插入
- 2.3.4 单向链表的删除
- 2.4 双向链表的基本操作
- 2.4.1 双向链表的结构和创建
- 2.4.2 双向链表的插入和删除
(一) 关于线性表
1.1 线性表的基本概念
关于线性表的知识点,我们看一张思维导图便于我们理解

(二) 关于链表
2.1 链表的基本概念
线性表的链式存储结构的特点就是用一组任意的存储单元存储线性表的数据元素(存储单元可以连续也可以不连续),对于每一个数据元素,除了存储其本身的信息之外,还要存储一个用于指示其后继元素的信息(也即是后继元素的存储位置),这两部分信息构成了链表的结点,所以说结点有两个域,一个是数据域,一个是指针域,n个结点链接成为一个链表
2.2 结点的结构表示
根据上文提到的结点的概念,结点有两个域,一个是数据域,一个是指针域,那么我们用代码表示就是下面这样的:
struct node
{
element_type data; //这里是你所需要的数据,可以有很多
node *next;
};2.3 单链表的基本操作
2.3.1 单链表的创建
在本文中我们采用尾插法创建单向链表,因为用尾插法创建的链表在遍历输出的时候是按照我们输入的顺序输出的,而采用头插法则是逆序输出的,下面我们看看尾插法的创建示意图
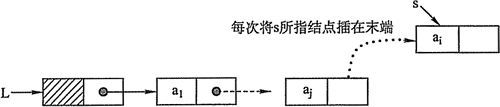
我们知道,链表必须要有一个头指针(或者是尾指针),这里我们使用头指针,为了成功地创建链表,我们还需要两个指针p1,p2,其中,p1用于不断去开辟新的结点存放我们的信息,p2是把p1开辟的结点和之前创建的链表连接起来的一个桥梁。下面我们看看具体是如何实现的(假设结点的数据域包括学生的学号和成绩)
node* creat(void)
{
node *head, *p1, *p2;
p1 = p2 = new node;
cin>>p1->num>>p1->score;
head = NULL; //初始化头指针,这很重要
while(p1->num != 0) //我们以这个条件作为是否输入完毕的判断
{
n++; //假设我们之前已经定义了一个全局变量n用于统计链表中结点的个数
if(n == 1) //n = 1说明是第一个创建的结点
{
head = p1;
}
else
{
p2->next = p1;
}
p2 = p1;
p1 = new node;
cin>>p1->num>>p1->score;
}
p2->next = NULL; //退出了while循环表示输入完毕,这时一定要记得把链表最后一个结点的指针域设为NULL
return head; //返回头指针
}2.3.2 单链表的遍历
这很简单,只需要用一个node *temp,从头指针处开始一个一个元素地去遍历单链表即可
void print(node *head)
{
node *temp;
temp = head;
while(temp != NULL)
{
cout<<temp->num<<" "temp->score<<endl;
temp = temp->next;
}
}2.3.3 单链表的插入
我们需要先找到插入的位置,然后只需要把需要插入位置的两个结点的连接断开,分别和准备插入的结点连上就OK了
那么,完成这些工作,我们可以用三个指针p1, p2, p0, 其中p0指向带插入的结点,p1指向插入位置的后继结点,p2指向带插入位置的前驱结点,(因为在单向链表中没有前驱指针),在本例中我们按num从小到大的顺序插入新结点
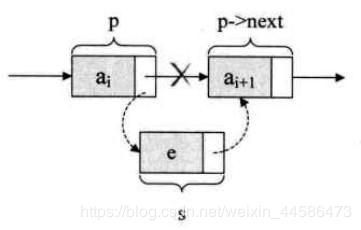
node* insert(node *head, node *stu)
{
node *p0, *p1, *p2;
p1 = head;
p0 = stu;
if(head == NULL)
{
head = p0;
p0->next = NULL;
}
else
{
while(p1->num < p0->num && p1->next != NULL)
{
p2 = p1;
p1 = p1->next;
}
if(p1->num >= p0->num)
{
if(p1 == head) //这种是把结点插在头部的情况
{
head = p0;
p0->next = p1;
}
else //这种是把结点插在中间的情况
{
p2->next = p0;
p0->next = p1;
}
}
if(p1->next == NULL) //这种是把结点插在尾部的情况
{
p1->next = p0;
p0->next = NULL;
}
}
n++;
return head;
}2.3.4 单向链表的删除
对于单向链表的删除,我们可以使用两个指针,一个指向待删除结点的前驱结点,另一个指向带删除节点的后继结点,当然也可以像下图那样只使用一个指针去实现
那么我们再讨论一下如何找到前驱结点呢?我们可以使用滞后法,就是先让pre_p等于p1,随后p1往后走一个元素,这样以此类推下去,最后当我们确定了p1的位置的时候,我们就可以保证pre_p总是指向p1的前面一个元素
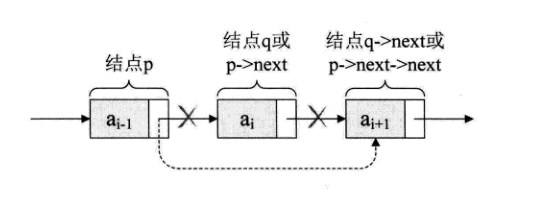
node* del(node *head, int del_num)
{
node *p, *pre_p; //p指针用于寻找要删除的结点, pre_p用于确定该节点的前驱结点
p = head;
if(p == NULL)
{
return head; //该链表为空
}
while(p->num != del_num && p->next != NULL)
{
//如果目前p指针所指向结点的数据和del_num不匹配而且p还有向后搜索的余地
pre_p = p1;
p1 = p1->next;
}
if(p->num == del_num) //找到了要删除的结点
{
if(p == head) //该结点在第一个
{
head = p->next;
return head;
}
else
{
pre_p->next = p1->next; //这一步就实现了上面流程图的目的,当p是最后一个结点时p->next = NULL,所以我们不需要单独讨论删除的结点在最后一个的情况
}
}
else
{
cout<<"没有找到要删除的结点"<<endl;
}
n--; //链表长度减一
return head;
}2.4 双向链表的基本操作
2.4.1 双向链表的结构和创建
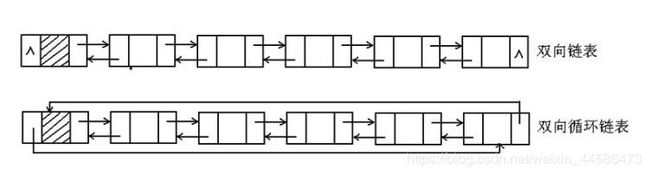
其实不要被双向链表的名字吓住了,其实它和单链表没什么本质上的区别,只不过是每个结点多了前驱指针罢了,它的创建过程和单链表思路几乎一样
下面是双向链表的结构
struct double_link
{
element_type data;
double_link *next;
double_link *prior;
}; 而对于双向链表的创建有几点需要注意的地方
而对于双向链表的创建有几点需要注意的地方
- 当创建了双向链表的第一个结点(假设p1指向它),那么我们应该要让p1->prior = NULL;
p1->next = NULL; - 每次插入新的结点,我们都要让这两个结点建立双向联系,即p2->next = p1; p1->prior = p2; 同时别忘了让新结点(也就是末尾结点)的next指针指向NULL
2.4.2 双向链表的插入和删除
对于双向链表的插入和删除,指针变化的顺序还是有一定讲究的,比如说p0指向要插入的结点,p1,p2分别是带插入位置的前驱指针和后继指针,我们想完成插入操作,可以这样写
p0->next = p2;
p0->prior = p1;
p2->prior = p0;
p1->next = p0;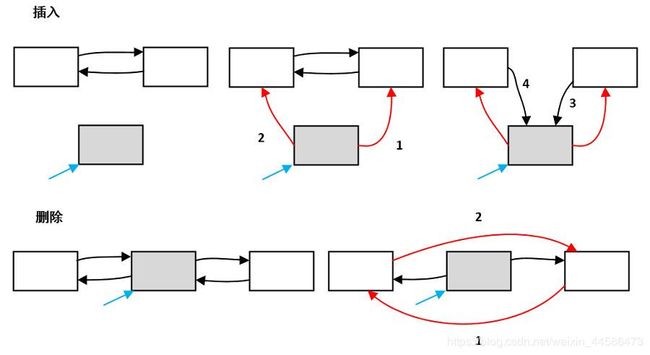
PS:在之后的博文中,我还会分享一些关于链表的有趣的算法题