java容器
文章目录
- 1.概览
- 2.List
- 2.1 ArrayList(✔)
- 2.2 LinkedList(✔)
- 2.3 Vector(✔)
- 2.4 CopyOnWriteArrayList(✔)
- 3.Map
- 3.1 HashMap
- 3.2 LinkedHashMap(✔)
- 3.3 WeakHashMap(✔)
- 3.4 TreeMap
- 3.5 ConcurrentHashMap(✔)
- 3.6 ConcurrentSkipListMap
- 4. Set
- 4.1 HashSet
- 4.2 LinkedHashSet
- 4.3 TreeSet
- 4.4 CopyOnWriteArraySet
- 4.5 ConcurrentSkipListSet
- 5. Queue
- 5.1 PriorityQueue
- 5.2 ArrayBlockingQueue
- 5.3 LinkedBlcokingQueue
- 5.4 SynchronousQueue
- 5.5 PriorityBlockingQueue
- 5.6 LinkedTransferQueue
- 5.7 ConcurrentLinkedQueue
- 5.8 DelayQueue
- 5.9 ArrayDeque
- 并发容器有哪些
1.概览
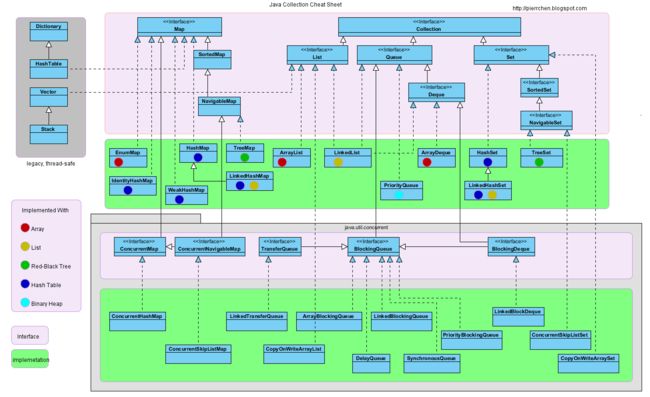
-
Set
无序,不包含重复元素,可以插入 null
HashSet:为快速查找设计的Set。存入HashSet的对象必须定义hashCode()。
TreeSet: 保存次序的Set, 底层为树结构。使用它可以从Set中提取有序的序列。
LinkedHashSet:具有HashSet的查询速度,且内部使用链表维护元素的顺序(插入的次序)。于是在使用迭代器遍历Set时,结果会按元素插入的次序显示。 -
List
有顺序以线性方式存储,可以存放重复对象
-
Queue
-
Map
key 可以为 null,键也可以为 null
键必须是唯一,
2.List
2.1 ArrayList(✔)
-
ArrayList(✔)
-
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable private static final int DEFAULT_CAPACITY = 10; private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8; // 超过了直接扩容为 Integer.MAX_VALUE- add
public boolean add(E e) { //将 size+1 作为最小容量,判断是否需要扩容.第一次插入时,需要扩容成 size=10 //超过 10 之后在扩容,扩容容量为现在的 1.5 倍 //扩容操作需要调用 Arrays.copyof(),把原来数组整个复制到新数组中,这个操作代价很高. //因此最好在创建 ArrayList 对象时,就指定大概的容量,减少扩容次数. ensureCapacityInternal(size + 1); // Increments modCount!! elementData[size++] = e; return true; } private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); //右移相当于除二操作, 扩容1.5倍 if (newCapacity - minCapacity < 0) //扩容后的容量 < 最小容量 newCapacity = minCapacity; //扩容容量大小为 minCapacity if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: //Arrays.copyOf:new一个新数组,长度为newCapacity,然后将elementData数组复制过去,最后返回一个新的数组 elementData = Arrays.copyOf(elementData, newCapacity); } private static int hugeCapacity(int minCapacity) { if (minCapacity < 0) // overflow throw new OutOfMemoryError(); return (minCapacity > MAX_ARRAY_SIZE) ? Integer.MAX_VALUE : MAX_ARRAY_SIZE; } -
remove
public E remove(int index)
- 注意: 移除之后 elementData[–size] = null; //为了使 GC 起作用
public boolean remove(Object o)
- o 为 null ,遍历 list 移除第一个 为 null 的元素
- 不为 null,判断 移除第一个 相等 即 equals 的元素
- 注意: 移除之后 elementData[–size] = null; //为了使 GC 起作用
-
遍历方式
for
增强 for 循环 — 还是用迭代器实现的
迭代器
-
fail-fast
modCount 记录 list 结构发生改变(添加/删除)的次数
if (modCount != expectedModCount) throw new ConcurrentModificationException(); -
两个坑
-
顺序删除
@Test //错误示范 public void delete(){ List<Integer> list = new ArrayList<>(); for (int i = 1; i < 5; i++) { list.add(i); } System.out.println(list);//[1, 2, 3, 4] for (int i = 0; i < list.size(); i++) { list.remove(i); } System.out.println(list);//[2, 4] } //正确的方法 @Test public void delete2(){ List<Integer> list = new ArrayList<>(); for (int i = 1; i < 5; i++) { list.add(i); } System.out.println(list);//[1, 2, 3, 4] for (int i = (list.size()-1); i >= 0; i--) { list.remove(i); } System.out.println(list);//[] } -
增强 for 循环 / 迭代器遍历,不能对数组进行增删操作,只能使用迭代器的 remove 方法
@Test public void iteratorTest(){ List<Integer> list = new ArrayList<>(); for (int i = 1; i < 5; i++) { list.add(i); } Iterator<Integer> iterator = list.iterator(); while (iterator.hasNext()){ list.add(1); // 抛异常 ConcurrentModificationException -> checkForComodification System.out.println(iterator.next()); } } @Test public void foreachTest(){ List<Integer> list = new ArrayList<>(); for (int i = 1; i < 5; i++) { list.add(i); } for (Integer a:list){ list.add(10);// ConcurrentModificationException System.out.println(a); } } //正确的方法 @Test public void iteratorTest2(){ List<Integer> list = new ArrayList<>(); for (int i = 1; i < 5; i++) { list.add(i); } Iterator<Integer> iterator = list.iterator(); while (iterator.hasNext()){ System.out.println(iterator.next()); iterator.remove();//执行remove之前需要执行next方法,给 lastRet 赋值才能 remove } System.out.println(list);//[] }
-
-
序列化/反序列化
private void readObject(java.io.ObjectInputStream s) private void writeObject(java.io.ObjectOutputStream s)
2.2 LinkedList(✔)
-
LinkedList(✔)
-
小结:
(1)LinkedList是一个以双链表实现的List;
(2)LinkedList还是一个双端队列,具有队列、双端队列、栈的特性;
(3)LinkedList在队列首尾添加、删除元素非常高效,时间复杂度为O(1);
(4)LinkedList在中间添加、删除元素比较低效,时间复杂度为O(n);
(5)LinkedList不支持随机访问,所以访问非队列首尾的元素比较低效;
(6)LinkedList在功能上等于ArrayList + ArrayDeque; -
和 ArrayList 对比
LinkedList (双向链表结构)
- 优点:不需要扩容和预留空间,不需要连续的存储空间
- 优点: 添加和 删除 效率高
- 缺点: 随机访问效率低,需要遍历整个链表
- 缺点:改查效率低
ArrayList (顺序表结构—数组)
- 优点: 支持随机访问
- 缺点:添加/删除效率低,需要拷贝数组(也可能涉及扩容操作)
-
双向链表查找 index 位置的节点时,有一个加速动作:若index < 双向链表长度的1/2,则从前向后查找; 否则,从后向前查找。
-
常用方法
//可以用作 list, 双端队列,, 也可以作为栈使用 //Deque getFirst //返回此列表的第一个元素。 getLast //返回此列表的第一个元素。 removeFirst //移除并返回此列表的第一个元素。 removeLast addFirst //将指定元素插入此列表的开头。 addLast element peek //获取但不移除此列表的头(第一个元素)。 peekFirst //获取但不移除此列表的第一个元素;如果此列表为空,则返回 null。 peekLast poll //获取并移除此列表的头(第一个元素) pollFirst //获取并移除此列表的第一个元素;如果此列表为空,则返回 null。 pollLast remove //获取并移除此列表的头(第一个元素)。 offer //将指定元素添加到此列表的末尾(最后一个元素)。 offerFirst // 在此列表的开头插入指定的元素。 offerLast push pop //从此列表所表示的堆栈处弹出一个元素。 //AbstractSequentialList get set add remove -
其余看脑图
2.3 Vector(✔)
和 ArrayList 对比
-
相同点:
-
和 ArrayList 实现了相同的接口, 继承了相同的父类,
-
底层都是数组实现
-
初始默认长度都是 10
-
public class Vector<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable
-
-
不同:
- Vector 是线程安全的,因为使用了 Synchronized
- 扩容容量: Vector 2倍, ArrayList: 1.5倍
2.4 CopyOnWriteArrayList(✔)
-
参考文献1 参考文献2
public class CopyOnWriteArrayList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable{
final transient ReentrantLock lock = new ReentrantLock();
private transient volatile Object[] array;
public CopyOnWriteArrayList() // 构造一个空数组 setArray(new Object[0]);
public CopyOnWriteArrayList(Collection<? extends E> c) // 将 传入的 Collection 转为Object[] 赋值给 array
public CopyOnWriteArrayList(E[] toCopyIn) // 将传入的数组 toCopyIn 赋值给 array
}
-
add (总的来说:就是先将array拷贝一份,然后进行添加,最后在赋值回去)
public boolean add(E e) public void add(int index, E element) { final ReentrantLock lock = this.lock; lock.lock(); try { Object[] elements = getArray(); int len = elements.length; //检查越界情况 if (index > len || index < 0) throw new IndexOutOfBoundsException("Index: "+index+ ", Size: "+len); Object[] newElements; //移动的元素的个数 int numMoved = len - index; if (numMoved == 0) //插在末尾 newElements = Arrays.copyOf(elements, len + 1); else { newElements = new Object[len + 1]; System.arraycopy(elements, 0, newElements, 0, index); System.arraycopy(elements, index, newElements, index + 1, numMoved); } newElements[index] = element; setArray(newElements); } finally { lock.unlock(); } } public boolean addIfAbsent(E e) private boolean addIfAbsent(E e, Object[] snapshot) ---加锁的添加方法,详情看 jdk souorceCode注释 -
get 未加锁
public E get(int index) { return get(getArray(), index); } -
remove : 和 add 一样,复制在删除在赋值. 加锁
-
迭代器
static final class COWIterator<E> implements ListIterator<E> { /* CopyOnWriteArrayList 在使用迭代器遍历的时候,操作的都是原数组, 没有像 ArrayList 那样进行修改次数判断,所以不会抛异常! */ private final Object[] snapshot; private int cursor; private COWIterator(Object[] elements, int initialCursor) { cursor = initialCursor; snapshot = elements; } //不支持 remove 操作,只能依靠 CopyOnWriteArrayList 的 remove()方法 public void remove() { throw new UnsupportedOperationException(); } } -
小结
(1)CopyOnWriteArrayList使用 ReentrantLock 重入锁加锁,保证线程安全;
(2)CopyOnWriteArrayList的写操作都要先拷贝一份新数组,在新数组中做修改,修改完了再用新数组替换老数组,所以空间复杂度是O(n),性能比较低下;
(3)CopyOnWriteArrayList的读操作支持随机访问,时间复杂度为O(1);
(4)CopyOnWriteArrayList采用读写分离的思想,读操作不加锁,写操作加锁,且写操作占用较大内存空间,所以适用于读多写少的场合;
(5)CopyOnWriteArrayList只保证最终一致性,不保证实时一致性;
缺陷,对于边读边写的情况,不一定能实时的读到最新的数据
3.Map
3.1 HashMap
- 参考文献1
3.2 LinkedHashMap(✔)
-
数组+双向链表+红黑树+单链表
-
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V> -
//LinkedHashMap 的 Entry static class Entry<K,V> extends HashMap.Node<K,V> { Entry<K,V> before, after; // 用于维护 插入结点的顺序 Entry(int hash, K key, V value, Node<K,V> next) { super(hash, key, value, next); } } //HashMap 的 Node static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; //用于 链接 哈希桶中的 单链表 } //双向链表的头结点 transient LinkedHashMap.Entry<K,V> head; //双向链表的尾结点 transient LinkedHashMap.Entry<K,V> tail; // true:按照访问顺序存储元素(LRU) false:插入顺序存储元素 --默认:false final boolean accessOrder; // public LinkedHashMap(int initialCapacity,float loadFactor, boolean accessOrder) -
保证 顺序的 函数
//HashMap 中,这三个方法都是没实现的,在 LinkedHashMap 中实现来维护结点顺序 // void afterNodeAccess(Node<K,V> p) { } void afterNodeInsertion(boolean evict) { } void afterNodeRemoval(Node<K,V> p) { } //LinkedHashMap /* 在节点访问之后被调用,主要在put()已经存在的元素或get()时被调用, 如果accessOrder为true,调用这个方法把访问到的节点移动到双向链表的末尾。 */ void afterNodeAccess(Node<K,V> e) { // move node to last LinkedHashMap.Entry<K,V> last; // accessOrder = true则执行,否则结束 // accessOrder = true, e 不是 tail 尾结点 if (accessOrder && (last = tail) != e) { LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; p.after = null; if (b == null) head = a; else b.after = a; if (a != null) a.before = b; else last = b; if (last == null) head = p; else { p.before = last; last.after = p; } tail = p; ++modCount; } } /* 在节点插入之后做些什么,在HashMap中的putVal()方法中被调用,可以看到HashMap中这个方法的实现为空。 evict:驱逐的意思 如果 evict 为 true,则移除最老的元素(head) 默认removeEldestEntry()方法返回false,也就是不删除元素。 */ void afterNodeInsertion(boolean evict) { // possibly remove eldest LinkedHashMap.Entry<K,V> first; //如果evict为true,且头节点不为空,且 确定移除最老的元素,即移除 head //head 为 双向链表的头结点 if (evict && (first = head) != null && removeEldestEntry(first)) { K key = first.key; //HashMap.removeNode()从HashMap中把这个节点移除之后,会调用 afterNodeRemoval() 方法; removeNode(hash(key), key, null, false, true); } } //传进来的参数 是 双向链表的头结点 (即最老的结点) protected boolean removeEldestEntry(Map.Entry<K,V> eldest) { return false; } /* 在节点被删除之后调用的方法 afterNodeInsertion -> HashMap.removeNode() -> afterNodeRemoval 从双向链表中 删除结点 e */ void afterNodeRemoval(Node<K,V> e) { // unlink LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; // 把节点p从双向链表中删除。 p.before = p.after = null; if (b == null) head = a; else b.after = a; if (a == null) tail = b; else a.before = b; } /* 因此使用 LinkedHashMap 实现 LRU, 1) 设置 accessOrder 为 true --> 把最近访问的结点移动到尾部 2) 重写 removeEldestEntry 方法 --> 返回 true 会删除该结点, false 不删除 */ -
get
public V get(Object key) { Node<K,V> e; if ((e = getNode(hash(key), key)) == null) return null; //如果查找到了元素,且accessOrder为true, //则调用afterNodeAccess()方法把访问的节点移到双向链表的末尾。 if (accessOrder) afterNodeAccess(e); return e.value; } -
小结
(1)LinkedHashMap继承自HashMap,具有HashMap的所有特性;
(2)LinkedHashMap内部维护了一个双向链表存储所有的元素;
(3)如果accessOrder为false,则可以按插入元素的顺序遍历元素;
(4)如果accessOrder为true,则可以按访问元素的顺序遍历元素;
(5)LinkedHashMap的实现非常精妙,很多方法都是在HashMap中留的钩子(Hook),直接实现这些Hook就可以实现对应的功能了,并不需要再重写put()等方法;
(6)默认的LinkedHashMap并不会移除旧元素,如果需要移除旧元素,则需要重写removeEldestEntry()方法设定移除策略;
(7)LinkedHashMap可以用来实现LRU缓存淘汰策略;
3.3 WeakHashMap(✔)
-
WeakHashMap(✔)
-
强/软/弱/虚引用
强应用、软引用、弱引用、虚引用 分别是什么?

- 强引用: 内存不足,也不会对对象进行回收
- 软引用:内存不足,可以被回收GC
- 弱引用:只要有GC运行就会被回收
- 引用队列: ReferenceQueue —> 弱引用、软引用、虚引用 在被GC回收之后,会被放入引用队列
- 虚引用: 如果一个对象只具有虚引用,那么它就和没有任何引用一样,任何时候都可能被gc回收。
/* 强引用: 当内存不足,JVM开始垃圾回收,对于==强引用对象,就算出现了OOM也不会对该对象进行回收== 强引用是造成Java内存泄漏的主要原因之一。 */ Object o = new Object(); /* 软引用: 软引用是相对强引用弱化了一些的引用,需要用java.lang.ref.SoftReference类来实现 对于软引用的对象来说:当系统内存充足时他不会被回收,当系统内存不足时,他会被回收 应用举例: 假如有一个应用程序需要读取大量图片, 如果每次读取图片都从硬盘读取则会严重影响性能, 如果一次性全部加载到内存中又可能造成内存溢出。 此时可以使用软引用来解决。 设计思路是:用一个HashMap来保存图片的路径和相应图片对象关联的软引用之间的映射关系, 当内存不足时,JVM会自动回收这些缓存图片对象所占用的空间,从而有效地避免了OOM的问题。 Map -
WeakHashMap是一种弱引用map,内部的key会存储为弱引用,当jvm gc的时候,如果这些key 没有强引用存在 的话,会被gc回收掉,下一次当我们操作map的时候会把对应的Entry整个删除掉,基于这种特性,WeakHashMap特别适用于缓存处理。
-
存储结构: WeakHashMap因为gc的时候会把没有强引用的key回收掉,所以注定了它里面的元素不会太多,因此也就不需要像HashMap那样元素多的时候转化为红黑树来处理了.因此,WeakHashMap的存储结构只有(数组 + 链表)。
-
public class WeakHashMap<K,V> extends AbstractMap<K,V> implements Map<K,V> { //桶 Entry<K,V>[] table; //引用队列,当弱键失效的时候会把Entry添加到这个队列中,当下次访问map的时候会把失效的Entry清除掉。 private final ReferenceQueue<Object> queue = new ReferenceQueue<>(); } -
Entry 内部类
private static class Entry<K,V> extends WeakReference<Object> implements Map.Entry<K,V> { // 可以发现没有key, 因为key是作为弱引用存到Referen类中 V value; final int hash; Entry<K,V> next; /** * Creates new entry. */ Entry(Object key, V value,ReferenceQueue<Object> queue,int hash, Entry<K,V> next) { // 调用WeakReference的构造方法初始化key和引用队列 /* WeakReference 又调用父类的构造方法 public WeakReference(T referent, ReferenceQueue q) { super(referent, q); } */ super(key, queue); this.value = value; this.hash = hash; this.next = next; } } public abstract class Reference<T> { // 实际存储key的地方 //key就是Reference的referent属性,它会被gc特殊对待,即当没有强引用存在时,当下一次gc的时候会被清除。 private T referent; /* Treated specially by GC */ // 引用队列 volatile ReferenceQueue<? super T> queue; Reference(T referent, ReferenceQueue<? super T> queue) { this.referent = referent; this.queue = (queue == null) ? ReferenceQueue.NULL : queue; } } private T referent; /* Treated specially by GC */ -
put
自己看 JDK 1.8 注释
计算 hash -> 确定哈希桶 -> 遍历链表 -> 找到替换 -> 没找到插在哈希桶的开头 -> size++ 判断是否需要扩容
和 HashMap 不同:
-
HashMap key 为空,直接返回 0, 这里使用 空对象
//HashMap return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); //WeakHashMap return (key == null) ? NULL_KEY : key; --> hash(key) -
求 hash 值 : HashMap只用了一次异或,这里用了四次
-
扩容: HashMap中是大于threshold才扩容,这里等于threshold就开始扩容了
//WeakHashMap if (++size >= threshold) resize(tab.length * 2); //HashMap if (++size > threshold) resize();//两倍扩容使用的是 oldCap << 1
-
-
resize
/* ? 不确定 : getTable() 调用 expungeStaleEntries() 清除 queue 中的结点即 无效的 key, 此时 value,next 即 Entry 还存在 Entry -
使用案例
@Test public void useWeakHashMap(){ Map<String,Integer> map = new WeakHashMap<>(); map.put(new String("1"),1); map.put(new String("2"),2); map.put(new String("3"),3); map.put("6",6); //使用 key 强引用 "3" 这个字符串 String key = null; for (String s:map.keySet()){ if (s.equals("3")){ key = s; } } System.out.println(map);//{6=6, 1=1, 2=2, 3=3} System.gc(); map.put(new String("4"),4); // gc 后 放入的值 (4)和 强引用的 key (3,6) 可以打印出来 System.out.println(map);//{4=4, 6=6, 3=3} key = null; System.gc(); System.out.println(map);//{6=6} /* Entry(Object key, V value,ReferenceQueue