hadoop入门之mapreduce(四)
标签(空格分隔): hadoop
1.概念
mr是什么:mapreduce 一个分布式编程框架
通过这个框架我们嵌入相关代码就能实现分布式运算程序,一般而言都需要分成两个阶段,第一阶段在每台机器上做运算,之后需要将所有数据的运算结果进行汇总,这就是map 和reduce。
2.几个角色及相互关系
2.1编程角色
Mapper: 用于执行map task的时候调用
Reducer: 用于执行reducetask的时候调用
Driver: 是yarn的客户端,获取相关数据并提交给yarn的resourcemanage,起相关的map task,reducetask和appmaster
2.2运行过程中的角色
map task: map task是map阶段的任务
reduce task: reduce task是reduce运行阶段的任务
appmaster: 负责map和reduce调度衔接的管理程序,包括在异常情况下的任务管理,在yarn中执行
yarn: 资源和任务调度框架 包括ResourceManage NodeManage,ResourceManage负责协调整个集群资源,NodeManage是当前机器的使用管理。(当前我是这么了解的,后续学到yarn的时候再着重了解)
2.3map task和reduce task的关系
先说一下:map task和reduce task
map和reduce是两个各自并行的流程,map相互之间根据数据拆分的信息(InputSplict),完成map多任务并行处理。而reducetask则需要等待所有maptask完成之后的结果,根据分区及reducetask数量完成多reducetask的运行。整个流程由appmaster去监控,如果发现异常可能会起替补map task/reducetask 做补救(保证执行结果的可靠性及减少时间消耗 这就是资源调度框架的好处之一)。
3第一个mr程序构建
3.1简要说明
与之前构建的hdfs程序的maven引入一样, hadoop-client包也包含了yarn相关的包,所以无需引入其他包。
如果觉得麻烦可以从github上面下载这个项目,里面主要是我写的一些demo案例。为了兼顾半途直接看的同学我会将项目依赖给贴出来。
3.2构建
1)maven jar包引入
org.apache.hadoop
hadoop-client
{hadoop.version}
2)map类
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* Created by: luochengyue
* date: 2019/5/7.
* desc:
* Mapper
* 泛型的四个字段说明:读取数据的位置,读取的这一行数据,输出的Key的类型,输出的Value类型
* 另外需要注意由于涉及到网络传输,所以需要使用hadoop包中的基本类型传输包,也可以自定义,只要实现对应的hadoop的Writable接口接口
* @version:
*/
public class WcMapper extends Mapper {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] words = value.toString().split(" ");
//将每个单词和对应的计数输出,由于会根据key排序,所以我们中间也可以不进行数据统计
for(String w:words){
context.write(new Text(w),new IntWritable(1));
}
}
}
3)reducce类构建
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Created by: luochengyue
* date: 2019/5/7.
* desc:
* Reducer
* Reducer参数说明:key 对应map的输出key,value对应map的输出value,之后是对应本身reduce的输出参数key和value的类型
* @version:
*/
public class WcReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
//由于reduce相同key会被传输到同一个reducetask,之后一组相同的key会调用一次reduce所以 key对应的value是Iterable
int count = 0;
for(IntWritable vc:values){
count+=vc.get();
}
context.write(key,new IntWritable(count));
}
}
4)dirver构建
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* Created by: luochengyue
* date: 2019/5/7.
* desc:yarn的客户端,
* @version:
*/
public class WcDriver {
public static void main(String[] args) throws Exception{
//由于涉及到操作hdfs数据,有一个用户的概念所以需要设置下hadoop的用户名 -DHADOOP_USER_NAME=hadoop 就可以设置用户名了
//这个可以查看FileSystem里面会发现获取一个系统内的HADOOP_USER_NAME作为用户名 job.setUser应该也可以回头试下
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://hadoop1:9000");//可不配置默认操作本地的
Job job = Job.getInstance(conf);
//接着主要设置几个简单的参数即可 主要设置包括map类,reduce类,map输出参数类型,reduce最终输出类型,驱动所在的jar包
//这些方法都可以在job上看到set相关的方法
job.setJarByClass(WcDriver.class);//所在jar包
job.setMapperClass(WcMapper.class);
job.setReducerClass(WcReducer.class);
//map输出的相关参数
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//reduce输出的相关参数
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setUser("hadoop");
//输入输出参数路径设置
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//提交等待完成 会输出打印过程 实际调用的是submit
boolean comple = job.waitForCompletion(true);
System.exit(comple?0:1);
}
}
5)数据准备
angala girl boy
you know i like
sad goob bye
i like java
i like hadoop
将这两个这个数据放入到文件上传到hadoop的作为输入目录的地方,可以上传成多个不同命的文件
6)打包
一种是默认不用构建使用打包类 idea直接package就能打包
另一种用maven显示配置
maven-assembly-plugin
false
com.dinfo.mr.MrMainDriver
org.apache.maven.plugins
maven-dependency-plugin
copy
package
copy-dependencies
${project.build.directory}/lib
我直接没有配置
7)运行
使用
hadoop jar wc.jar mainpackage inputpath outputpath
例子hadoop jar hdfsops-1.0-SNAPSHOT.jar com.lcy.hadoop.mr.wc.WcDriver /wcdemo/input /wcdemo/output
运行,因为wc.jar中包含了相关的hadoop中的包引用,所以可以直接利用hadoop集群中的类库,我们打包时不包含类库的直接使用hadoop jar人家就能引入hadoop相关的包。减少jar包大小,迁移程序成本降低。
8)查看相关数据
hadoop fs -cat partition-… 数据可以看到我们wc的结果
至此第一个wc程序构建使用成功
3.3mapreduce提交流程
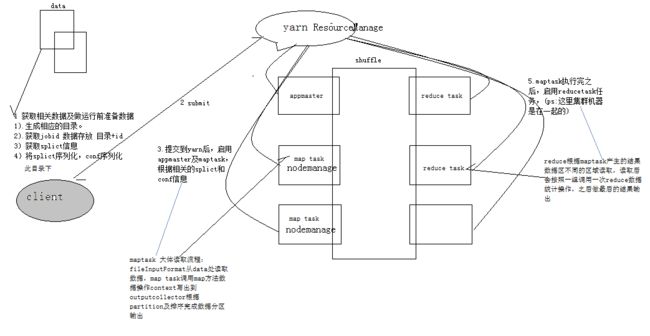
1 获取相关数据及做运行前准备数据
1).生成相应的目录。
2).获取jobid 数据存放 1)中目录+id
3) 获取splict信息
4)将splict序列化,conf序列化
2.submit到yarn resourcemanage
3.提交到yarn后,启用appmaster及maptask,根据相关的splict和conf信息
1)maptask 大体流程:fileInputFormat从data处读取数据,map task调用map方法数据操作context写出到outputcollector根据partition及排序完成数据分区输出
4.shuffle(后续补充)
5.maptask执行完之后,启用reducetask任务
1)reduce根据maptask产生的结果数据区不同的区域读取,读取后会按照一组调用一次reduce数据统计操作,之后做最后的结果输出。
4并行度的机制
相关机制
4.1map并行机制
map并行机制就是map可以启多少个,决定并行任务数量
map的并行制主要是根据切片之后可以切多少片,多少个splict就会启动多少个map task
4.1.1map切片逻辑梳理
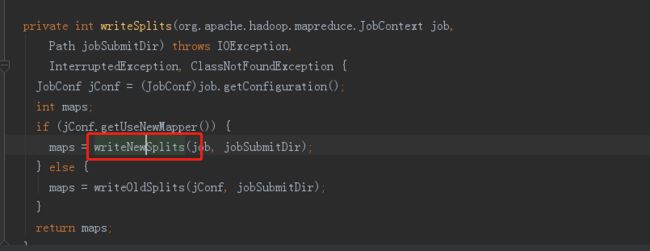
通过job.submit提交任务,然后我们看获取splict的流程。


public static final String SPLIT_MINSIZE =
"mapreduce.input.fileinputformat.split.minsize";
public static final String SPLIT_MAXSIZE =
"mapreduce.input.fileinputformat.split.maxsize";
这是两个对应的最小最大拆分参数
差不多就是这样了,切片逻辑先从InputFormat,
1)通过反射获取我们我们这里设置的是FileInputFormat来进行切片信息。
2)我们可以通过configuration去设置最大最小拆分数据。
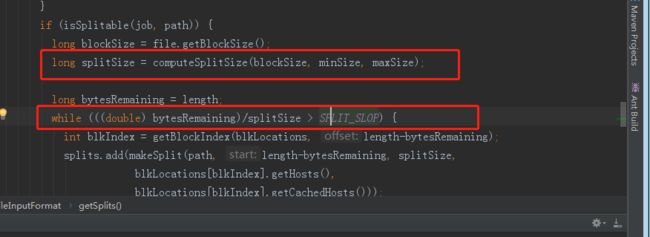
3)之后根据Math.max(minSize, Math.min(maxSize, blockSize));获取切片大小
4)之后判定剩余的数据是否大于3)中获取的数据量的1.1倍,如果不大于直接把剩余的放进InputSplict,如果大于则按splict拆分后,剩余的继续按4逻辑走。
5)这样就获取到了splicts的数据,序列化到jobid下的文件夹给yarn,之后会根据这个信息去启动相应数量的map
4.2 reduce并行机制
reduce的并行度我们是可以手动设置的,job.setNumReduceTasks(1);
这个参数设置reduce的数量,会根据partition相应的reduce获取相应的区域数据,完成reduce程序的流程。而partition我们可以设置job.setPartitionerClass();完成partition逻辑的设置。
思考题
数据来源:
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 24 27 2481 24681 200
说明:时间戳 手机号码 ...最后一个状态码,倒数第二个下载流量,倒数第三个上行流量
1.现有一个流量统计任务,文件在baidu网盘上
根据此数据完成手机号 上传流量,下载流量,总流量的统计 其中文件中的行主要是以 \t 完成切分。这题主要是需要自定义Bean记得实现Writable接口。
链接:https://pan.baidu.com/s/1N8MN79U9vt6TjP1tFvXXFg
提取码:7x3u
复制这段内容后打开百度网盘手机App,操作更方便哦
2.将1中的文件按区域分区输出到不同的文件中,这题主要是需要做分区和设置reducenumber。考察自定义Partitioin.