关系抽取比赛:pipeline方法实践
关系抽取:命名体识别+关系分类方法实践
- 1.写在前面
- 2.数据部分
- 未能处理好的问题
- 3.解决方案
- NER部分
- 关系分类部分
- 4.预测部分
- 5.总结
- 遗憾
- 反思
- 6.有用的链接
1.写在前面
- 寒假开始看RE,3月正好看到百度的比赛,在导师的支持下报名参加。
- 看论文学习和动手实践还是有区别的,第一次参加NLP的比赛,第一次使用bert,动手能力还是比较捉急,看代码,跑模型,摸爬滚打花了好多时间。
- 本次比赛还是有许多不足,会一一总结。一开始对于任务数据理解不够深刻,选用了pipeline方法,就决心一路走到底吧
- 从结果来看不是很理想,由于时间设备关系,也没怎么炼丹,去追求最好的结果。过程来说动手能力得到了锻炼。
- 本文档单纯做个记录
2.数据部分
- 数据存在关系类别不平衡、长短句数量不平衡、实体类型数量不平衡的问题
- 实体中存在一些生僻字,通用的bert不是很契合。
针对以上两个问题,使用了数据增强以及语言模型深度预训练的做法。
数据增强:EDA
深度预训练:How to Fine-Tune BERT for Text Classification?
未能处理好的问题
数据中存在噪声,具体体现:
- 在实体标注不全
- 句子中三元组标注不完整
- 文本中有许多特殊字符、表情
三元组标注不完整,其实可以考虑在训练集上做类似于交叉验证的做法。比如5份数据集,每次用4份训练,得到5个模型,在训练集上跑5份结果,然后进行投票,5份都预测到却没在训练集中的实体进入模型。
实体标注不全和文本中的噪声则需要一些文本清洗,正则表达式的做法,碍于捉急的动手能力,等到发现的时候,已经没时间,只能标注时全部丢掉。
- 反思:对于数据理解不够充分。虽然是NLP任务,也需要进行描述性分析,也需要用肉眼看数据,才能更好地理解数据,这部分工作没做到位。
3.解决方案
Pipeline的思路应该是有两种做法:
- 先预测句子可能的类别(多分类多标签),再对该类别下的句子抽取头尾实体。
P ( s , p , o ∣ s e n t e n c e ) = P ( p ∣ s e n t e n c e ) P ( s , o ∣ p , s e n t e n c e ) P(s,p,o| sentence) = P(p | sentence) P(s,o|p,sentence) P(s,p,o∣sentence)=P(p∣sentence)P(s,o∣p,sentence) - 先标注实体,再进行关系分类
P ( s , p , o ∣ s e n t e n c e ) = P ( s , o ∣ s e n t e n c e ) P ( p ∣ s , o , s e n t e n c e ) P(s,p,o| sentence) = P(s,o|sentence)P(p | s,o,sentence) P(s,p,o∣sentence)=P(s,o∣sentence)P(p∣s,o,sentence)
对于前者,参考的是:bert实践:关系抽取解读
后者是自己做的方案。选用的框架是:Kashgari
NER部分
Bert + BiLSTM + CRF
由于对NER任务没太多了解,就选了框架中自带的模型。
主要说说标注的设计。
数据集中实体是带类型信息的,比如人物、地点、歌曲等等,一共有26个类别。标注设计方式:B-1,B-2,…B-26,I,O。
之所以这样设计,是因为如果类别识别的相当精准,那其实相当于已经基本做完了,因为根据实体类型,就能大致确定关系(除了人物-人物有四种关系)。但有误差,也能大致确定头尾实体,以及哪些可能是无关的实体。
如果不考虑类型的信息,那如果一个句子中有6个实体,输入关系分类模型时,就需要穷举6*5 =30 个实体对,这显然是不好的。不仅浪费计算资源,同时,大量无关实体对也对关系分类模型数据标注造成了困难。
所以,标注设计的目的是,希望把实体类型信息运用充分,利用标注的信息做初步召回。但这样因为标签类别多自然错误率会增多,同时误差也在模型间传播【深刻体会】。
在验证集上,NER模型f1-score = 0.83
关系分类部分
参考方法:《Enriching Pre-trained Language Model with Entity Information for Relation Classification》
这篇文章从学术角度,没有多大的贡献,只是发现了一种标注实体的方式,十分契合bert。
模型结构如下:
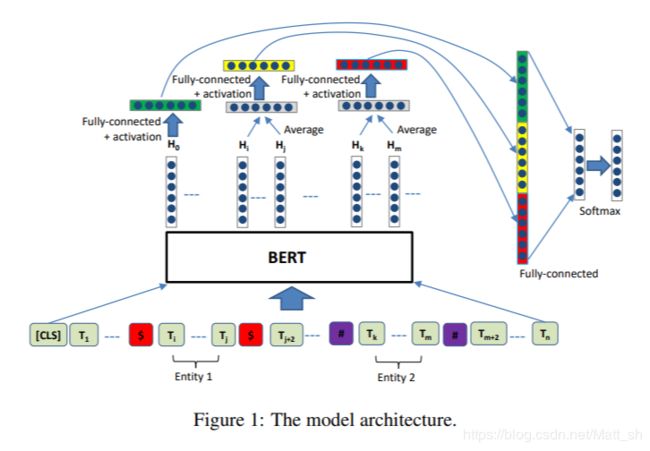
简单来说,头尾实体前后分别加上 $ 与 # 。然后构建两个mask向量,只有实体所在位置是1,非实体部分mask掉。输出层两个mask向量分别去与bert的sequence_output做内积,得到的两个向量与bert的pool_output拼接,输入进全连接网络做一个softmax,输出类别。
这部分我的工作量主要在基于Kashgar包的复现模型上。自行设置了一个类,这是一个多输入,单输出的模型。
具体坑概括如下:
- 多输入的部分是一个元组,传入到base_model.py里需要改data_generator部分(原框架只适应于单输入,虽然说支持,但其实不太行)
- 自定义的模型会少些属性,用callback时,在callback.py中也要稍作修改。
关系分类单模型的f1-score达到了0.93。就是说,在知道实体信息的情况下,预测实体间关系的效果是相当不错的。
4.预测部分
首先进行NER:
Input:sentence
output:【(e1,t1)(e2,t2)(e3,t3)(e4,t4)】
e是实体,t是实体类型。
假设实体类型预测是对的。
根据给定的schema,我可以知道哪些是头实体,哪些是尾实体,哪些类型的尾实体匹配相应的头实体。
即,我可以得到(e1:e2,e4)(e2:e3) (e3:e4)【subject:object】的形式。
同时,还可以知道他们可能的关系,即4个候选的label_list。
这样在关系分类阶段:
只需预测e1,e2 ; e1,e4 ; e2,e3 ; e3,e4 这四组实体对的关系。
召回策略:
- 假设四组预测得到的关系是p1,p2,p3,p4。
- 如果 p i p_i pi在候选的 l a b e l l i s t i label list_i labellisti中,那召回这个三元组 ( s i , p i , o i ) (s_i,p_i,o_i) (si,pi,oi)。
- 如果不在,则进入第二轮候选的list。
- 第二轮候选list通过观察预测结果,通过一些模板的做法召回
这样的做法,十分依赖NER的标注结果。可惜NER这部分做的比较粗糙,也没有调参,只有0.83的f1值,所以最终结果不是特别理想。而且出现了少部分句子(1/12)预测出单实体、零实体的情【这种情况这套方案没法解决】。
所以只能用关系分类+实体抽取的方法(上述链接)做填充与召回(类似于融合的办法吧,但没有投票,是以该结果为基准)
后面为了提升效果,又把官方baseline的预测结果做投票,最终f1为0.7392。
5.总结
遗憾
- 端到端的方法没有尝试。Joint entity recognition and relation extraction as a multi-head selection problem这篇文章应该也适合这个比赛。
- 炼丹过程体验不够,损失函数有看了focal loss,但最后没有用上。
- 调参也只是预实验凭感觉,没有尝试使用一些调参的方法。33 个神经网络「炼丹」技巧
- 文本去噪在RE这边也有些方法,没有调研。
- 端到端,多标签的一些解码策略也没实践
反思
- 首先,要对数据进行比较深入的探索与了解;
- 其次,要对于相应的模型与方法调研充分,侧重于其适应于什么数据,解决什么问题,有哪些缺陷。
- 再者,要想自己去改进方法与模型,更应该从数学的角度出发,将具体问题抽象成数学的形式,模型是形式的一个表达。如果形式不变,那只是在这种框架下找最好的模型与参数。形式改变,是解决思路的改变,更有可能对于一些方法进行改进。
- 最后,时间安排应该更加紧凑,要对于模型训练、调参、融合有个预估。
6.有用的链接
nlp中的实体关系抽取方法总结
基于DGCNN和概率图的轻量级信息抽取模型
- 数据增强的论文:Affinity and Diversity: Quantifying Mechanisms of
Data Augmentation - 文本数据描述分析方法总结