Hadoop实战学习(1)-WordCount
环境:Hadoop:2.7.3,JDK:1.8.0_111,ubuntu16.0.4,Idea2018。
Idea是Linux版本的,不是Windows版本的哈。这里需要注意。整个开发测试环境都是Linux系统下的。
随意准备一个txt文档,输入一些单词。txt文档命名为test.txt。先上传到本地文件系统当中进行测试,

这个是文件内容
以下是具体代码:
package com.hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.IOException;
import java.util.StringTokenizer;
/**
* @Author Administrator
* @Date 2018/5/27 14:31
*/
public class HDFSDemo {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf=new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount ");
System.exit(2);
}else {
FileSystem.get(conf).delete(new Path(otherArgs[1]));
}
//设置作业名称
Job job=Job.getInstance(conf,"wordcount");
//设置搜索类
job.setJarByClass(HDFSDemo.class);
//设置输入格式,TextInputFormat是默认输入格式,不能设置成FileInputFormat.Class,该惨数在当前情况下可以不设置
job.setInputFormatClass(TextInputFormat.class);
//设置Mapper类
job.setMapperClass(TokenizerMapper.class);
//设置Reducer类
job.setReducerClass(IntSumReducer.class);
//设置Reducer个数
job.setNumReduceTasks(1);
//设置maper端单词输出格式
job.setMapOutputKeyClass(Text.class);
//设置mapper端单词输出个数格式
job.setMapOutputValueClass(IntWritable.class);
//设置Reducer端单词输出格式
job.setOutputKeyClass(Text.class);
//设置Reducer单词输出个数格式
job.setOutputValueClass(IntWritable.class);
//设置job的输入路径,多次add可以设置多个输入路径
FileInputFormat.addInputPath(job,new Path(otherArgs[0]));
//设置输出路径
FileOutputFormat.setOutputPath(job,new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
public static class TokenizerMapper extends Mapper {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
}
然后配置输入参数:
点击Idea菜单栏中的 Run->Edit Configurations,弹出如下窗口:
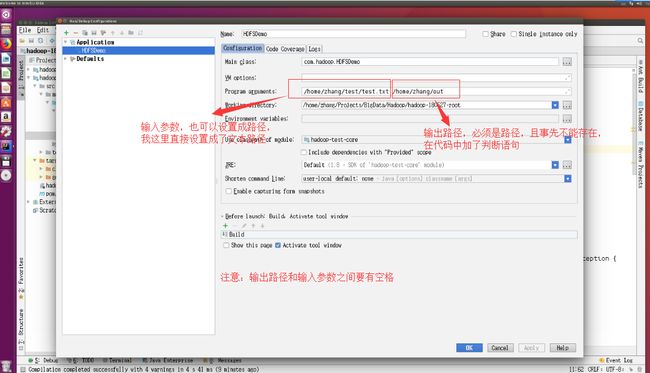
按照图中的指示配置输入与输出参数,然后边缘运行代码:

程序编译通过,然后在该主机上面参看是否有输出内容:

可以看到有输出结果,并且输出结果是正确的。
然后将程序打包成jar包并放到主目录下。打包jar包的方法就不讲了。
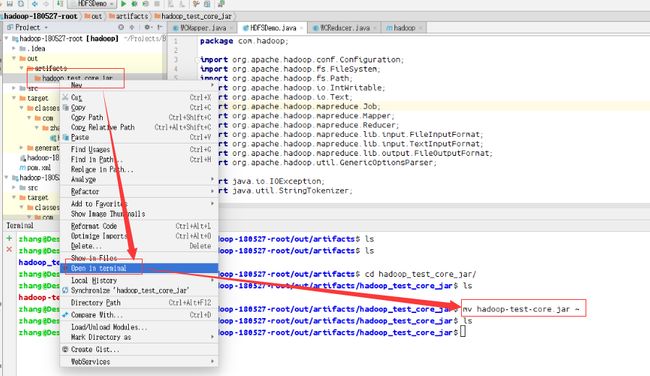
jar包打包成功过后将jar移动到用户主目录。然后开始在正式环境下测试。

这里以分布式系统中目录/user/zhang/hadoop分输入路径。
然后执行命令:
~$ hadoop jar hadoop-test-core.jar com.hadoop.HDFSDemo /user/zhang/hadoop output
由于代码中只使用了一个Reducer,因此只有一个DataNode在进行输出计算,所以时间教长。

可以看到作业已经计算成功。

可以看到在分布式文件系统中已经建立了一个output目录并且存放了计算结果。
然后将计算结果输出查看:

可以看到和之前在开发环境下的测试输出结果是一模一样的。
到此整个过程就结束了。
源代码地址:https://pan.baidu.com/s/1NYRwwIN9YHYESVYQ7oy0OA
下载解压后会有三个文件夹,以导入maven工程的方式导入root那个文件夹中的 pom.xml即可。