Hadoop中的自定义数据类型(序列化、反序列化机制)详解
大家都知道,Hadoop中为Key的数据类型必须实现WritableComparable接口,而Value的数据类型只需要实现Writable接口即可;能做Key的一定可以做Value,能做Value的未必能做Key.但是具体应该怎么应用呢?----本篇文章将结合手机上网流量业务进行分析。
核心:JDK中自带的序列化机制会传递对象的继承结构信息,而hadoop中的序列化机制不会传递对象的继承结构信息.
先介绍一下业务场景:统计每个用户的上行流量和,下行流量和,以及总流量和。
本次描述所用数据:
日志格式描述:
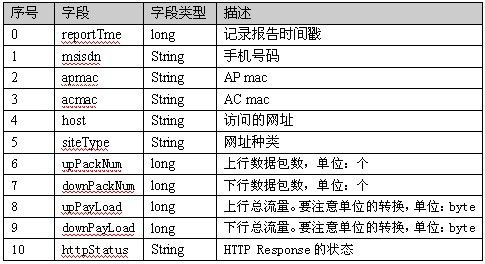
日志flowdata.txt中的具体数据:
下载地址:链接:https://pan.baidu.com/s/1_uTmheiguruyx20u8VrASA 提取码:sjtt

接下来贴出详细代码,代码中含有详细注释,从代码中可以看出,用到了hadoop自定义的数据类型FlowType,因为FlowType只做value,所以在代码中只需要实现Writable接口。
package FlowSum;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
//本程序的目的是统计每个用户的上行流量和,下行流量和,以及总流量和:用到的知识点是hadoop中自定义数据类型(序列化与反序列化机制)
public class MsisdnFlowSum
{
public static String path1 = "file:///C:\\flowdata.txt";
public static String path2 = "file:///C:\\flowdir\\";
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(conf);
if(fileSystem.exists(new Path(path2)))
{
fileSystem.delete(new Path(path2), true);
}
Job job = Job.getInstance(conf);
job.setJarByClass(MsisdnFlowSum.class);
FileInputFormat.setInputPaths(job, new Path(path1));
job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowType.class);
job.setNumReduceTasks(1);
job.setPartitionerClass(HashPartitioner.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowType.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileOutputFormat.setOutputPath(job, new Path(path2));
job.waitForCompletion(true);
//查看运行结果:
FSDataInputStream fr = fileSystem.open(new Path("file:///C:\\flowdir\\part-r-00000"));
IOUtils.copyBytes(fr, System.out, 1024, true);
}
public static class MyMapper extends Mapper
{
protected void map(LongWritable k1, Text v1,Context context)throws IOException, InterruptedException
{
//拿到日志中的一行数据
String line = v1.toString();
//切分各个字段
String[] splited = line.split("\t");
//获取我们所需要的字段:手机号、上行流量、下行流量
String msisdn = splited[1];
long upPayLoad = Long.parseLong(splited[8]);
long downPayLoad = Long.parseLong(splited[9]);
//将数据进行输出
context.write(new Text(msisdn), new FlowType(upPayLoad,downPayLoad));
}
}
public static class MyReducer extends Reducer
{
protected void reduce(Text k2, Iterable v2s,Context context)throws IOException, InterruptedException
{
long payLoadSum = 0L; //计算每个用户的上行流量和
long downLoadSum = 0L; //统计每个用户的下行流量和
//数据传递过来的时候:<手机号,{FlowType1,FlowType2,FlowType3……}>
for (FlowType v2 : v2s)
{
payLoadSum += v2.upPayLoad;
downLoadSum += v2.downPayLoad;
}
context.write(k2, new FlowType(payLoadSum,downLoadSum)); //在此需要重写toString()方法
}
}
}
class FlowType implements Writable
{
public long upPayLoad;//上行流量
public long downPayLoad;//下行流量
public long loadSum; //总流量
public FlowType(){}
public FlowType(long upPayLoad,long downPayLoad)
{
this.upPayLoad = upPayLoad;
this.downPayLoad = downPayLoad;
this.loadSum = upPayLoad + downPayLoad;//利用构造函数的技巧,创建构造函数时,总流量被自动求出
}
//只要数据在网络中进行传输,就需要序列化与反序列化
//先序列化,将对象(字段)写到字节输出流当中
public void write(DataOutput fw) throws IOException
{
fw.writeLong(upPayLoad);
fw.writeLong(downPayLoad);
}
//反序列化,将对象从字节输入流当中读取出来,并且序列化与反序列化的字段顺序要相同
public void readFields(DataInput fr) throws IOException
{
this.upPayLoad = fr.readLong();//将上行流量给反序列化出来
this.downPayLoad = fr.readLong(); //将下行流量给反序列化出来
}
public String toString()
{
return "" + this.upPayLoad+"\t"+this.downPayLoad+"\t"+this.loadSum;
}
}
代码写完之后,我们先用hadoop的本地运行模式调试代码,本地运行模式的运行日志如下(指摘部分日志):
2016-07-07 14:11:59,821 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1334)) - Running job: job_local2141814132_0001
2016-07-07 14:11:59,823 INFO [Thread-3] mapred.LocalJobRunner (LocalJobRunner.java:createOutputCommitter(471)) - OutputCommitter set in config null
2016-07-07 14:11:59,832 INFO [Thread-3] mapred.LocalJobRunner (LocalJobRunner.java:createOutputCommitter(489)) - OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
查看运行结果:
13480253104 180 180 360
13502468823 7335 110349 117684
13560439658 2034 5892 7926
13600217502 1080 186852 187932
13602846565 1938 2910 4848
13660577991 6960 690 7650
13719199419 240 0 240
13726230503 2481 24681 27162
13760778710 120 120 240
13823070001 360 180 540
13826544101 264 0 264
13922314466 3008 3720 6728
13925057413 11058 48243 59301
13926251106 240 0 240
13926435656 132 1512 1644
15013685858 3659 3538 7197
15920133257 3156 2936 6092
15989002119 1938 180 2118
18211575961 1527 2106 3633
18320173382 9531 2412 11943
84138413 4116 1432 5548
本地运行模式说明代码是没有问题的,接下两我们打jar包在hadoop集群中运行业务:
代码进行相应的修改(修改部分如下):
public static String path1 = "";
public static String path2 = "";
public static void main(String[] args) throws Exception
{
path1=args[0];
path2=args[1];
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(conf);
if(fileSystem.exists(new Path(path2)))
{
fileSystem.delete(new Path(path2), true);
}
Job job = Job.getInstance(conf);
job.setJarByClass(MsisdnFlowSum.class);
FileInputFormat.setInputPaths(job, new Path(path1));
job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowType.class);
job.setNumReduceTasks(1);
job.setPartitionerClass(HashPartitioner.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowType.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileOutputFormat.setOutputPath(job, new Path(path2));
job.waitForCompletion(true);
}
在集群中的部分运行日志:
16/07/07 14:48:17 INFO client.RMProxy: Connecting to ResourceManager at hadoop22/10.187.84.51:8032
16/07/07 14:48:17 WARN mapreduce.JobSubmitter: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
16/07/07 14:48:18 INFO input.FileInputFormat: Total input paths to process : 1
16/07/07 14:48:18 INFO mapreduce.JobSubmitter: number of splits:1
16/07/07 14:48:18 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1467446290151_0006
16/07/07 14:48:18 INFO impl.YarnClientImpl: Submitted application application_1467446290151_0006
16/07/07 14:48:18 INFO mapreduce.Job: The url to track the job: http://hadoop22:8088/proxy/application_1467446290151_0006/
16/07/07 14:48:18 INFO mapreduce.Job: Running job: job_1467446290151_0006
16/07/07 14:48:23 INFO mapreduce.Job: Job job_1467446290151_0006 running in uber mode : false
16/07/07 14:48:24 INFO mapreduce.Job: map 0% reduce 0%
16/07/07 14:48:30 INFO mapreduce.Job: map 100% reduce 0%
16/07/07 14:48:36 INFO mapreduce.Job: map 100% reduce 100%
16/07/07 14:48:36 INFO mapreduce.Job: Job job_1467446290151_0006 completed successfully
我们接下来查看结果:
[root@hadoop11 local]# hadoop fs -cat /flowdir/part-r-00000
13480253104 180 180 360
13502468823 7335 110349 117684
13560439658 2034 5892 7926
13600217502 1080 186852 187932
13602846565 1938 2910 4848
13660577991 6960 690 7650
13719199419 240 0 240
13726230503 2481 24681 27162
13760778710 120 120 240
13823070001 360 180 540
13826544101 264 0 264
13922314466 3008 3720 6728
13925057413 11058 48243 59301
13926251106 240 0 240
13926435656 132 1512 1644
15013685858 3659 3538 7197
15920133257 3156 2936 6092
15989002119 1938 180 2118
18211575961 1527 2106 3633
18320173382 9531 2412 11943
84138413 4116 1432 5548
从上面的实例可以看出,Hadoop中的自定义数据类型其实是很简单的,但是Hadoop为什么需要自己定义一套数据类型呢?
原因在于:
Java中的数据类型在序列化与反序列化的过程中太麻烦了:Java中的数据类型在序列化与反序列化的过程中必须要保证这些类与类之间的关系,从这个角度讲,意味着代码量就很大,数据在网络中传输就很占网宽,而hadoop认为这样太麻烦了,所以有自定义的数据类型,简化了序列化与反序列化的过程,保证了代码量的简洁。
其实如果对hadoop中的自定义数据类型不是很了解的话,我们也可以用现有的hadoop数据类型,比如收LongWritable,Text等来解决业务问题,比如对于上面给的手机上网流量统计业务,我们的代码也可以这么设计:
package FlowSum;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
public class MsisdnFlowSum
{
public static String path1 = "file:///C:\\flowdata.txt";
public static String path2 = "file:///C:\\flowdir\\";
public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(conf);
if(fileSystem.exists(new Path(path2)))
{
fileSystem.delete(new Path(path2), true);
}
Job job = Job.getInstance(conf);
job.setJarByClass(MsisdnFlowSum.class);
FileInputFormat.setInputPaths(job, new Path(path1));
job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setNumReduceTasks(1);
job.setPartitionerClass(HashPartitioner.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileOutputFormat.setOutputPath(job, new Path(path2));
job.waitForCompletion(true);
//查看运行结果:
FSDataInputStream fr = fileSystem.open(new Path("file:///C:\\flowdir\\part-r-00000"));
IOUtils.copyBytes(fr, System.out, 1024, true);
}
public static class MyMapper extends Mapper
{
protected void map(LongWritable k1, Text v1,Context context)throws IOException, InterruptedException
{
//拿到日志中的一行数据
String line = v1.toString();
//切分各个字段
String[] splited = line.split("\t");
//获取我们所需要的字段:手机号、上行流量、下行流量
String msisdn = splited[1];
String upPayLoad = splited[8];
String downPayLoad = splited[9];
String str = ""+upPayLoad+"\t"+downPayLoad;//这样改变即可
//将数据进行输出
context.write(new Text(msisdn), new Text(str));
}
}
public static class MyReducer extends Reducer
{
protected void reduce(Text k2, Iterable v2s,Context context)throws IOException, InterruptedException
{
long payLoadSum = 0L; //计算每个用户的上行流量和
long downLoadSum = 0L; //统计每个用户的下行流量和
long sum = 0L;
for (Text v2 : v2s)
{
String[] splited = v2.toString().split("\t");
payLoadSum += Long.parseLong(splited[0]);
downLoadSum += Long.parseLong(splited[1]);
}
sum = payLoadSum +downLoadSum;
String result = ""+payLoadSum +"\t"+downLoadSum+"\t"+sum;
context.write(k2, new Text(result));
}
}
}
运行结果:
13480253104 180 180 360
13502468823 7335 110349 117684
13560439658 2034 5892 7926
13600217502 1080 186852 187932
13602846565 1938 2910 4848
13660577991 6960 690 7650
13719199419 240 0 240
13726230503 2481 24681 27162
13760778710 120 120 240
13823070001 360 180 540
13826544101 264 0 264
13922314466 3008 3720 6728
13925057413 11058 48243 59301
13926251106 240 0 240
13926435656 132 1512 1644
15013685858 3659 3538 7197
15920133257 3156 2936 6092
15989002119 1938 180 2118
18211575961 1527 2106 3633
18320173382 9531 2412 11943
84138413 4116 1432 5548
上面的程序是hadoop的本地运行模式,结果证明代码是没有问题的,接下来我们在集群中进行测试。
集群运行代码:
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
public class MsisdnFlowSum
{
public static String path1 = "";
public static String path2 = "";
public static void main(String[] args) throws Exception
{
path1 = args[0];
path2 = args[1];
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(conf);
if(fileSystem.exists(new Path(path2)))
{
fileSystem.delete(new Path(path2), true);
}
Job job = Job.getInstance(conf);
job.setJarByClass(MsisdnFlowSum.class);
FileInputFormat.setInputPaths(job, new Path(path1));
job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setNumReduceTasks(1);
job.setPartitionerClass(HashPartitioner.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileOutputFormat.setOutputPath(job, new Path(path2));
job.waitForCompletion(true);
}
public static class MyMapper extends Mapper
{
protected void map(LongWritable k1, Text v1,Context context)throws IOException, InterruptedException
{
//拿到日志中的一行数据
String line = v1.toString();
//切分各个字段
String[] splited = line.split("\t");
//获取我们所需要的字段:手机号、上行流量、下行流量
String msisdn = splited[1];
String upPayLoad = splited[8];
String downPayLoad = splited[9];
String str = ""+upPayLoad+"\t"+downPayLoad;//这样改变即可
//将数据进行输出
context.write(new Text(msisdn), new Text(str));
}
}
public static class MyReducer extends Reducer
{
protected void reduce(Text k2, Iterable v2s,Context context)throws IOException, InterruptedException
{
long payLoadSum = 0L; //计算每个用户的上行流量和
long downLoadSum = 0L; //统计每个用户的下行流量和
long sum = 0L;
for (Text v2 : v2s)
{
String[] splited = v2.toString().split("\t");
payLoadSum += Long.parseLong(splited[0]);
downLoadSum += Long.parseLong(splited[1]);
}
sum = payLoadSum +downLoadSum;
String result = ""+payLoadSum +"\t"+downLoadSum+"\t"+sum;
context.write(k2, new Text(result));
}
}
}
进度日志:
16/07/07 15:12:34 INFO client.RMProxy: Connecting to ResourceManager at hadoop22/10.187.84.51:8032
16/07/07 15:12:34 WARN mapreduce.JobSubmitter: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
16/07/07 15:12:34 INFO input.FileInputFormat: Total input paths to process : 1
16/07/07 15:12:35 INFO mapreduce.JobSubmitter: number of splits:1
16/07/07 15:12:35 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1467446290151_0007
16/07/07 15:12:35 INFO impl.YarnClientImpl: Submitted application application_1467446290151_0007
16/07/07 15:12:35 INFO mapreduce.Job: The url to track the job: http://hadoop22:8088/proxy/application_1467446290151_0007/
16/07/07 15:12:35 INFO mapreduce.Job: Running job: job_1467446290151_0007
16/07/07 15:12:41 INFO mapreduce.Job: Job job_1467446290151_0007 running in uber mode : false
16/07/07 15:12:41 INFO mapreduce.Job: map 0% reduce 0%
16/07/07 15:12:46 INFO mapreduce.Job: map 100% reduce 0%
16/07/07 15:12:54 INFO mapreduce.Job: map 100% reduce 100%
16/07/07 15:12:54 INFO mapreduce.Job: Job job_1467446290151_0007 completed successfully
查看运行结果:
[root@hadoop11 local]# hadoop fs -cat /flowdir2/part-r-00000
13480253104 180 180 360
13502468823 7335 110349 117684
13560439658 2034 5892 7926
13600217502 1080 186852 187932
13602846565 1938 2910 4848
13660577991 6960 690 7650
13719199419 240 0 240
13726230503 2481 24681 27162
13760778710 120 120 240
13823070001 360 180 540
13826544101 264 0 264
13922314466 3008 3720 6728
13925057413 11058 48243 59301
13926251106 240 0 240
13926435656 132 1512 1644
15013685858 3659 3538 7197
15920133257 3156 2936 6092
15989002119 1938 180 2118
18211575961 1527 2106 3633
18320173382 9531 2412 11943
84138413 4116 1432 5548
从上面也说明了一个道理,对于知识的运用,是需要灵活的掌握。
如果问题,欢迎留言指正!
总结:
1、简述Hadoop中数据类型的相关概念
1>凡是Hadoop中的数据类型必须要实现Writable接口,并且凡是作为key的数据类型还必须要实现WritableComparable接口,能做key的一定可以做value,能做value的未必能做key。
2>Java中的基本数据类型与Hadoop中的基本数据类型对照:
Long LongWritable
String Text
Integer IntWritable
Boolean BooleanWritable
3>Java中的基本数据类型与Hadoop中的基本数据类型的转化关系:
对于Java中的基本数据类型,通过调用Hadoop中的构造方法即可转化问Hadoop中的基本数据类型,如new LongWritable(123L);
对于Hadoop中的基本数据类型:Text是通过toString()方法,其它类型是通过调用get()方法即可转化为Java中的基本数据类型。
2、在MR的Mapper阶段和Reducer阶段编写程序时,为什么不用Java中的数据类型而要用Hadoop中的数据类型?
因为Java中的数据类型在序列化与反序列化的过程中必须要保持这些类与类之间的关系,从这个角度讲,意味着代码量就很大。而Hadoop中自定义的数据类型,简化了序列化与反序列化的过程,保证了代码量的简洁。
3、自定义数据类型报错:
java.lang.Exception: java.lang.RuntimeException: java.lang.NoSuchMethodException: com.zmy.hadoop.mr.flowCountWritable.FlowType.()
at org.apache.hadoop.mapred.LocalJobRunner$Job.runTasks(LocalJobRunner.java:462)
at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:529)

原因:查看自定义的数据类型中无参构造函数是否写了,没写的话,序列化的时候会报错.