mapreduce流程梳理
在Map阶段:RecordReader --> mapper.map() ---> partitioner ---->[字节数组内存缓冲区] --->Spill(Sort / Combiner) ---> merge(Combiner)
在Reduce阶段: copy --->[字节数组内存缓冲区] --->Spill(Sort / Combiner) --->merger(Combiner ) --->分组函数--->Reducer.reduce()
用户可以定制部分(当不设置则采用默认操作):
1)inputFormat
2)RecordReader
3)partitioner
4)Combiner
5)job.setSortComparator() 对应sort过程的据图排序逻辑
6)job.setGroupingComparator() 对应reduce阶段分组函数的处理逻辑
shuffle阶段调优:1)增加内存缓冲区大小;2)高效的序列化机制;3)增加Reduce端copy线程数量。
Map阶段:
1)使用 job.setInputFormatClass()定义的 InputFormat将输入的数据集分割成小数据块 split,同时InputFormat提供一个 RecordReader的实现。例如,当使用 TextInputFormat,它提供的 RecordReader 会将文本的行号作为 Key,这一行的文本作为 Value, 然后调用自定义 Mapper 的map方法,将一个个< LongWritable,Text>键值对输入给 Mapper 的 map方法。
2)在写内存环形缓冲区会先调用 job.setPartitionerClass() 对这个 Mapper 的输出结果进行分区,每个分区映射到一个Reducer。缓冲区满达到80%时,会spill数据到磁盘,该过程涉及到排序和combine,如果设置combine函数则做聚合操作;每个分区内又调用 job.setSortComparatorClass() 设置的 Key 比较函数类排序(这本身就是一个二次排序)。如果没有通过 job.setSortComparatorClass() 设置 Key 比较函数类,则使用 Key 实现的 compareTo() 方法,当key是整形类型则按照数字大小排序,当key是字符串时则按照字典顺序进行排序;
3)merge阶段,对spill到磁盘上的文件进行合并操作,合并操作过程中牵涉到combine逻辑,这个阶段结束会生成两个文件,一个是index文件和data文件,其中index文件标记data文件中不同的地址是对应的reduce该拉取的数据;
4)整个map阶段结束就会通知jobtracker,对应的reduce就会从map阶段merger出的文件通过http协议进行数据的拉取操作。
Reduce阶段:
1)通过http协议从对应map中拉取自己的数据到字节数组内存缓冲区;
2)Spill阶段与map过程中Spill的处理逻辑一样,只是排序和Combiner的对象是从多个map端拉取的数据;
3)merge阶段与map过程处理逻辑一样,该过程还会涉及到分组函数,使用 job.setGroupingComparatorClass()方法设置分组函数类。只要这个比较器比较的两个 Key 相同,它们就属于同一组,它们的 Value 放在一个 Value 迭代器,而这个迭代器的 Key 使用属于同一个组的所有Key的第一个Key;
5)Reduer.reduce()方法的调用,reduce()方法的输入时所用的Key和其Value迭代器。
关注点:所谓的排序操作都是对key进行的
启发:其实MR就是利用分而治之思路,当数据量或者任务比较大时,如何提高并行计算度,利用服务器集群资源并充分压榨服务器资源达到计算速度的要求,若不采用分治来解决,有可能要等待很长时间甚至问题无解。在现实生活中,分治思想到处可见。
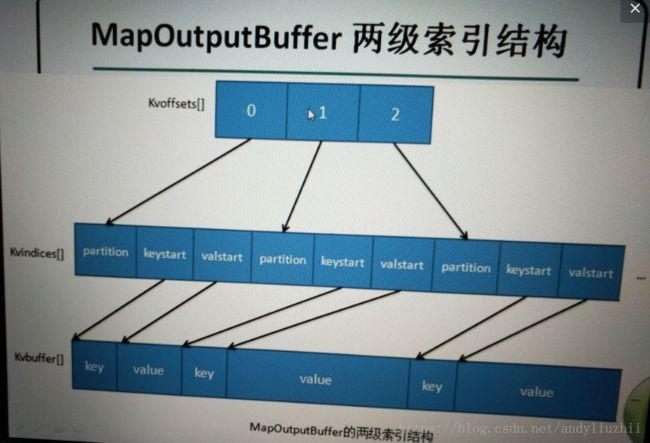
参数梳理:

1).mapreduce.reduce.shuffle.input.buffer.percent分配环形缓冲区的百分比2).mapreduce.reduce.shuffle.memory.limit.percent 从一个map拉取数据时用到的最大内存大小,当从一个map端拉取的数据大于这个值就直接落盘,否则,到内存缓冲区3)mapreduce.reduce.shuffle.merge.percent 达到这个值,线程从内存中merge到一个文件并且spill到磁盘
注释:merge线程至少要2个内存对应的file进行merge,所以2应该大于3
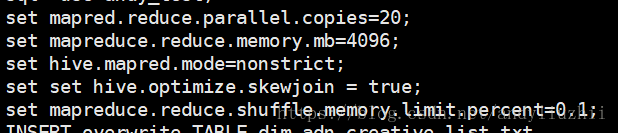
set mapred.reduce.parallel.copies=20;set mapreduce.reduce.memory.mb=4096;set hive.mapred.mode=nonstrict;set set hive.optimize.skewjoin = true; set mapreduce.reduce.shuffle.memory.limit.percent=0.1;
block_size : hdfs的文件块大小,默认为64M,可以通过参数dfs.block.size设置
total_size : 输入文件整体的大小input_file_num : 输入文件的个数1)默认map个数如果不进行任何设置,默认的map个数是和blcok_size相关的。default_num = total_size / block_size;2)期望大小可以通过参数mapred.map.tasks来设置程序员期望的map个数,但是这个个数只有在大于default_num的时候,才会生效。goal_num = mapred.map.tasks;3)设置处理的文件大小可以通过mapred.min.split.size 设置每个task处理的文件大小,但是这个大小只有在大于block_size的时候才会生效。split_size = max(mapred.min.split.size, block_size);split_num = total_size / split_size;4)计算的map个数compute_map_num = min(split_num, max(default_num, goal_num))除了这些配置以外,mapreduce还要遵循一些原则。 mapreduce的每一个map处理的数据是不能跨越文件的,也就是说min_map_num >= input_file_num。 所以,最终的map个数应该为:final_map_num = max(compute_map_num, input_file_num)经过以上的分析,在设置map个数的时候,可以简单的总结为以下几点:(1)如果想增加map个数,则设置mapred.map.tasks 为一个较大的值。(2)如果想减小map个数,则设置mapred.min.split.size 为一个较大的值。(3)如果输入中有很多小文件,依然想减少map个数,则需要将小文件merger为大文件,然后使用准则2。
对于Combiner有几点需要说明的是:1)有很多人认为这个combiner和map输出的数据合并是一个过程,其实不然,map输出的数据合并只会产生在有数据spill出的时候,即进行merge操作。2)与mapper与reducer不同的是,combiner没有默认的实现,需要显式的设置在conf中才有作用。3)并不是所有的job都适用combiner,只有操作满足结合律的才可设置combiner。combine操作类似于:opt(opt(1, 2, 3), opt(4, 5, 6))。如果opt为求和、求最大值的话,可以使用,但是如果是求中值的话,不适用。4)一般来说,combiner和reducer它们俩进行同样的操作。
特别值得注意的一点,一个combiner只是处理一个结点中的的输出,而不能享受像reduce一样的输入(经过了shuffle阶段的数据),这点非常关键
自定义partitioner的情况:
1)全局排序,只设置一个Reduce task,完全发挥不出集群的优势,而且能应对的数据量也很受限。最佳的方式是自己定义一个Partitioner,用输入数据的最大值除以系统Reduce task数量的商作为分割边界,也就是说分割数据的边界为此商的1倍、2倍至numPartitions-1倍,这样就能保证执行partition后的数据是整体有序的。2)解决数据倾斜:对于某些数据集,由于很多不同的key的hash值都一样,导致这些键值对都被分给同一个Reducer处理,而其他的Reducer处理的键值对很少,从而拖延整个任务的进度。当然,编写自己的Partitioner必须要保证具有相同key值的键值对分发到同一个Reducer。
3)自定义的Key包含好几个字段,比如自定义key是一个对象,包括type1,type2,type3,只需要根据type1去分发数据,其他字段用作二次排序。
4)全国分省份的数据,经常需要将相同省份的数据输入到同一个文件中,可以通过重写Partitioner 达到目的;分配reduce的数目等于要输出的文件数,并且一个文件中的数据为同一个key的数据
5)hadoop Partitioner使用及注意点job.setPartitionerClass(AgePartitioner.class);中设置的partitioner不生效,map的context.write()这个方法逻辑MapTask.javapublic void write(K key, V value) throws IOException, InterruptedException { collector.collect(key, value, partitioner.getPartition(key, value, partitions)); }其中partitioner是在哪里定义的呢?在NewOutputCollector类中,该类作为MapTask内部类。 private class NewOutputCollector extends org.apache.hadoop.mapreduce.RecordWriter { private final MapOutputCollector collector; private final org.apache.hadoop.mapreduce.Partitioner partitioner; private final int partitions; @SuppressWarnings("unchecked") NewOutputCollector(org.apache.hadoop.mapreduce.JobContext jobContext, JobConf job, TaskUmbilicalProtocol umbilical, TaskReporter reporter ) throws IOException, ClassNotFoundException { collector = createSortingCollector(job, reporter); partitions = jobContext.getNumReduceTasks(); if (partitions > 1) { partitioner = (org.apache.hadoop.mapreduce.Partitioner) ReflectionUtils.newInstance(jobContext.getPartitionerClass(), job); } else { partitioner = new org.apache.hadoop.mapreduce.Partitioner() { @Override public int getPartition(K key, V value, int numPartitions) { return partitions - 1; } }; } } 我们来看看构造函数之中,如果partitions大于1就从配置中读取我们自己的Partitioner对象并实例化给引用,否则自己就创建一个实例。那partitions是从jobContext.getNumReduceTasks();读取出来的,这个要怎么配置呢?job.setNumReduceTasks(number);
配置该值之后,那么就可以使用我们自己定义的分区函数了
50030端口的scheduler能看不同队列的 调度情况,看看有没有积压的任务。
参考资料 MR shuffle详解:https://blog.csdn.net/cnhk1225/article/details/50859216