有监督深度学习关系抽取论文集合(附代码)
文章目录
- 关系抽取
- Relation Classification via Convolutional Deep Neural Network,COLING 2014
- Relation Extraction:Perspective from Convolutional Neural Networks,NAACL 2015
- Relation Classification via Recurrent Neural Network,2015
- Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification,ACL2016
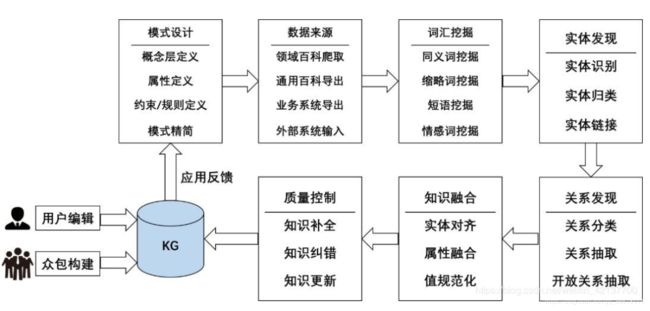
关系抽取
关系抽取的定义如下:给定一个句子X和一对实体
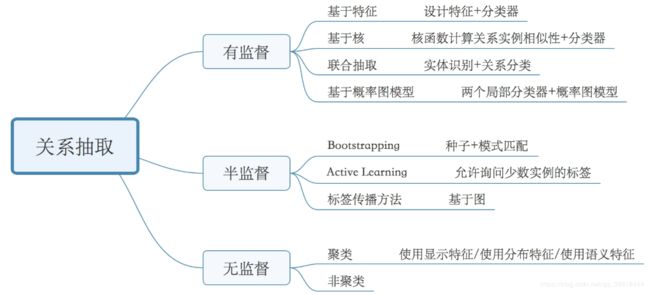
关系抽取可以分为有监督、半监督和无监督三类(图片来源:LINK),本次主要介绍有监督的相关模型。
Relation Classification via Convolutional Deep Neural Network,COLING 2014
本文是使用深度学习解决关系抽取任务的经典模型,以往的关系抽取都依赖于大量的特征工程,烦的一批。本文只需要从文本中构造Lexical Level Features和Sentence Level Features,将它们扔给模型就可以了。首先,让我们看整体的模型架构:
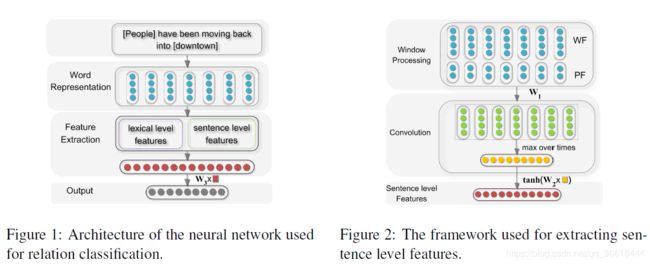
模型主要包括以下三个部分:单词表示、特征提取和输出。该系统不需要任何复杂的句法或语义预处理,系统的输入是一个带有两个标记名词的句子。然后,通过Word Embedding将单词标记转换为向量。然后分别提取词汇级特征和句子级特征,并直接拼接形成最终的特征向量。最后,将特征向量输入softmax分类器中。
- 单词表示
直接使用2010年一项研究训练好的词向量模型(注意word2vec是在2013年提出来的)。 - Lexical Level Features
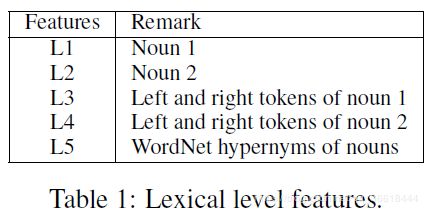
选择标记名词的嵌入词和上下文标记词,以及标记单词在WordNet中的上位词作为词法级别的特征。
- Sentence Level Features
Figure2展示了句子级别的特征提取过程:将Word Feature与Position Feature拼接之后,送入CNN。
- Word Feature:就是单词的本身的词向量。但是为了在卷积的时候也考虑到第一个单词与最后一个单词的上下文,进行了padding的操作,在句首添加x_s,句尾添加x_e。

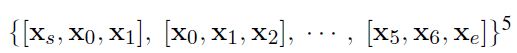
- Position Feature:PF是当前词到w1和w2的相对距离的组合。例如,句子中moving到People和downtown的相对距离分别是3和-3。所以一个单词最后就变成了本身的向量+到两个实体的相对距离。
Relation Extraction:Perspective from Convolutional Neural Networks,NAACL 2015
同样,使用CNN进行关系抽取,数据处理的方式与上一篇文章也类似,需要计算单词相对于实体的位置特征,每个单词的输入向量就变成了如下图所示。其中e表示单词文本的向量,d表示position embedding之后的向量。
![]()
模型采用与textCNN一样的框架。最开始获取单词的embedding,并且位置信息也要embedding。得到初始特征矩阵之后,送入带有多size filter的CNN。经过max pooling之后,将不同尺寸的filter的输出结果进行拼接,最后是一个dense。

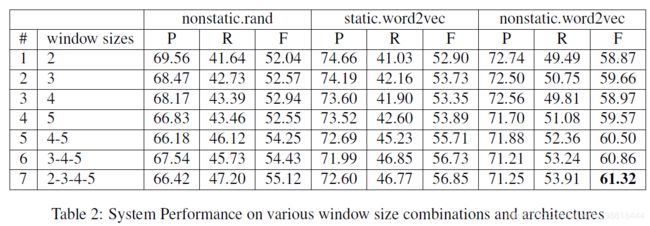
作者也在原文中探讨了filter的大小对效果的影响,所采用的filter的size越多,捕获的不同粒度的特征也就越多,效果越好。这和我们的直觉是一样的:
最终看一段模型的代码:
class PCNN(BasicModule):
'''
the basic model
Zeng 2014 "Relation Classification via Convolutional Deep Neural Network"
'''
def __init__(self, opt):
super(PCNN, self).__init__()
self.opt = opt
self.model_name = 'PCNN'
self.word_embs = nn.Embedding(self.opt.vocab_size, self.opt.word_dim)
self.pos1_embs = nn.Embedding(self.opt.pos_size + 1, self.opt.pos_dim)
self.pos2_embs = nn.Embedding(self.opt.pos_size + 1, self.opt.pos_dim)
feature_dim = self.opt.word_dim + self.opt.pos_dim * 2
# encoding sentence level feature via cnn
self.convs = nn.ModuleList([nn.Conv2d(1, self.opt.filters_num, (k, feature_dim), padding=(int(k / 2), 0)) for k in self.opt.filters])
all_filter_num = self.opt.filters_num * len(self.opt.filters) # 多次卷积输出
self.cnn_linear = nn.Linear(all_filter_num, self.opt.sen_feature_dim) # 输出句子特征维度
# self.cnn_linear = nn.Linear(all_filter_num, self.opt.rel_num)
# concat the lexical feature in the out architecture,句子、词级别向量拼接
# *6表示:两个实体以及实体的上下文一共6个单词
self.out_linear = nn.Linear(all_filter_num + self.opt.word_dim * 6, self.opt.rel_num)
# self.out_linear = nn.Linear(self.opt.sen_feature_dim, self.opt.rel_num)
self.dropout = nn.Dropout(self.opt.drop_out)
self.init_model_weight()
def init_model_weight(self):
'''use xavier to init'''
nn.init.xavier_normal_(self.cnn_linear.weight)
nn.init.constant_(self.cnn_linear.bias, 0.)
nn.init.xavier_normal_(self.out_linear.weight)
nn.init.constant_(self.out_linear.bias, 0.)
for conv in self.convs:
nn.init.xavier_normal_(conv.weight)
nn.init.constant_(conv.bias, 0)
def forward(self, lexical_feature, word_feautre, left_pf, right_pf):
left_emb = self.pos1_embs(left_pf) # (batch_size, max_len, word_dim)
right_emb = self.pos2_embs(right_pf) # (batch_size, max_len, word_dim)
sentence_feature = torch.cat([word_feautre, left_emb, right_emb], 2) # (batch_size, max_len, word_dim + pos_dim *2)
# conv part
x = sentence_feature.unsqueeze(1)
x = self.dropout(x)
x = [F.relu(conv(x)).squeeze(3) for conv in self.convs]
x = [F.max_pool1d(i, i.size(2)).squeeze(2) for i in x]
x = torch.cat(x, 1)
sen_level_emb = x
# combine lexical and sentence level emb
x = torch.cat([lexical_feature, sen_level_emb], 1)
x = self.dropout(x)
x = self.out_linear(x)
return x
Relation Classification via Recurrent Neural Network,2015
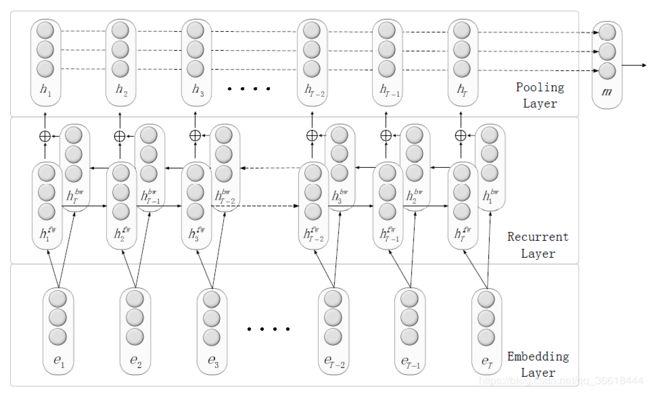
对于RNN,由于模型学习整个单词序列,因此在正向或反向递归传播时,可以自动获得每个单词的相对位置信息。因此,在单词序列中注释目标名就足够了,不需要改变输入向量。所以position信息就不在作为输入,而是在句子中加入“< e1> people ”这样的标记来表明实体的位置。
Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification,ACL2016
在上文的基础上引入注意力机制。深度学习中的注意力机制(Attention Mechanism)和人类视觉的注意力机制类似,就是在众多信息中把注意力集中放在重要的点上,选出关键信息,而忽略其他不重要的信息。在关系抽取中,注意力机制让分类器把“目光”重点放在对分类贡献大的词汇上。
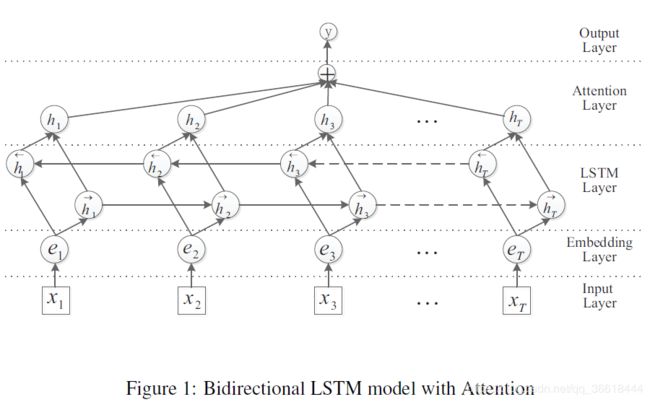
Attention的操作只需要三个公式就可以概括:

其中,H是BiLSTM的输出。α就是传说中的“注意力”,其实就是一个学习到的权重。这部分实现在代码里也很简单:
class Att_BLSTM(BasicModule):
def __init__(self):
super().__init__()
# net structures and operations
self.word_embeddings = nn.Embedding(cfg.vocab_size, cfg.word_dim) # embedding层
self.lstm = nn.LSTM(
input_size=cfg.word_dim,
hidden_size=cfg.lstm_hidden_dim//2, # 注意这里是双向的,所以除以二输出才能是hidden_dim
num_layers=cfg.layers_num,
bias=True,
batch_first=True,
dropout=0,
bidirectional=True,
)
self.tanh = nn.Tanh()
self.emb_dropout = nn.Dropout(0.3)
self.lstm_dropout = nn.Dropout(0.3)
self.linear_dropout = nn.Dropout(0.5)
self.weight_W = nn.Parameter(torch.Tensor(cfg.lstm_hidden_dim, cfg.lstm_hidden_dim))
self.weight_proj = nn.Parameter(torch.Tensor(cfg.lstm_hidden_dim, 1))
self.dense = nn.Linear(
in_features=cfg.lstm_hidden_dim,
out_features=cfg.rel_num,
bias=True
)
# initialize weight
nn.init.uniform_(self.weight_W, -0.1, 0.1)
nn.init.uniform_(self.weight_proj, -0.1, 0.1)
def forward(self, words,sentence):
x = torch.cat([words.long(), sentence.long()], 1)
embeds = self.word_embeddings(x) # [seq_len, bs, emb_dim]
embeds = self.emb_dropout(embeds)
lstm, _ = self.lstm(embeds) # [seq_len, bs, hid_dim]
# # # Attention过程,与论文中三个公式对应
u = torch.tanh(torch.matmul(lstm, self.weight_W))
att = torch.matmul(u, self.weight_proj) # 此时得到α
att_score = F.softmax(att, dim=1)
scored_x = lstm * att_score
# # # Attention过程结束
feat = torch.sum(scored_x, dim=1)
y = self.dense(feat)
return y
未完待续…