Siamese Network (应用篇2) :孪生网络用于图像块匹配 CVPR2015
参考论文:Zagoruyko S, Komodakis N. Learning to compare image patches via convolutional neural networks[J]. computer vision and pattern recognition, 2015: 4353-4361.
会议水平:CVPR2015
1. 摘要 及 目的
作者研究了如何从图像数据中直接学习到一个普适性的相似度函数用于图像匹配。匹配问题是是很多计算机视觉应用问题的基础。作者考虑到图像会发生大规模的形貌尺度等变化,所以直接训练了一个CNN模型进行参数拟合。特别的,作者研究了很多的神经网络框架,主要探索了那些网络结构更胜任图像匹配问题。同时,作者也进行了大量的数据测试,结果证明,采用孪生网络进行图像匹配具有非常大的优势。
2.方法 及 细节

图1. 缩略图。作者的目标在于学习一个通用的相似性测度函数,并应用于图像匹配中。为了编码这样一个函数,作者大量探索了卷积神经网络结构。
为了研究不同网络结构的速度与时间的考量,作者研究了当下最普遍的双通道卷积网络、孪生卷积网络、伪孪生网络。

图2. 作者研究的三种基本的网络框架。左边是双通道卷积网络;右边是孪生卷积网络和伪孪生卷积网络(孪生与伪孪生之间的区别在于孪生网络共享权重,非孪生网络不共享权重)。青色代表Conv+ReLU,,紫色代表Maxpooling,黄色代表全连接层(ReLU函数也存在于全连接层后)。
2.1 2-Channel是什么?有什么好处?
2-channel是把图像对合并成一张图像双通道。对于灰度图像这种方法可以理解,但是对于RGB图像,该方法是否可行?原理在哪里还需要有更加明确的解释。
和孪生结构相比,2-channel方法明显灵活性更大,同时也很容易去训练。但是,通常来讲,训练阶段2-channel结构更浪费时间,因为他需要将标准图像块与所有的候选图像块进行组合,原则上,这是很浪费时间的。
这样算法的最后一层直接是全连接层,输出神经元个数直接为1,直接表示两张图片的相似度。直接用双通道图片进行训练会比较快,比较方便,当然CNN,如果输入的是双通道图片,也就是相当于网络的输入的是2个feature map,经过第一层的卷积后网,两张图片的像素就进行了相关的加权组合并映射,这也就是说,用2-channel的方法,经过了第一次的卷积后,两张输入图片就不分你我了。而Siamese网络是到了最后全连接的时候,两张图片的相关神经元才联系在一起,这就是2-channel 与Siamese给我感觉最大的区别。这个作者后面通过试验,验证了从第一层开始,就把两张图片关联在一起的好处,作者的原话:This is something that indicates that it is important to jointly use information from both
patches right from the first layer of the network.
2.2 作者采用的策略
1. 作者采用了补充材料【1】中提及到的技术,具体为利用small+ReLU代替更大的卷积层,也可以直接理解为加深网络深度而不是拓宽网络宽度。
2. 目标-环境双流网络结构。
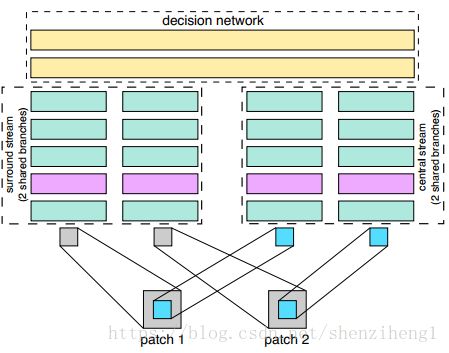
图 3. 目标-环境双流网络架构。实际上作者采用的依旧是孪生网络架构来处理,需要共享权重。实际上可以理解为多分辨率对图像匹配效果的影响。
这个创新点,需要对上面的网络结构稍作修改。假设我们输入的是大小为64*64的一张图片,那么Central-surround two-stream network的意思就是把图片64*64的图片,处理成两张32*32图片,然后再输入网络,那么这两张32*32的图片是怎么计算得到的?这就是Central-surround方法,也就是第一张图片是通过以图片中心,进行裁剪出32*32的图片,也就浅蓝色区域的图片。其实这个就像多尺度一样,在图片处理领域经常采用多分辨率、多尺度,比如什么sift、还有什么高斯金字塔什么的,总之作者说了,多分辨率可以提高两张图片的match效果
3. 空间金字塔网

图 4. 空间金字塔策略应用到孪生网络。
空间金字塔池化采样:这个又称之为SPP(Spatial pyramid pooling)池化,这个又什么用呢?这个跟上面的有点类似,这个其实就类似于多图片多尺度处理,我们知道现有的卷积神经网络中,输入层的图片的大小一般都是固定的,这也是我之前所理解的一个神经网络。直到知道SPP,感觉视觉又开阔了许多,菜鸟又长见识了。我们知道现在的很多算法中,讲到的训练数据图片的大小,都是什么32*32,96*96,227*227等大小,也就是说训练数据必须归一化到同样的大小,那么假设我的训练数据是各种各样的图片大小呢?我是否一定要把它裁剪成全部一样大小的图片才可以进入卷积神经网络训练呢?这就是SPP算法所要解决的问题,训练数据图片不需要归一化,而且江湖传说,效果比传统的方法的效果还好。
4. 数据增强、
To combat overfitting we augment training data by flipping both patches in pairs horizontally and vertically and rotating to 90, 180, 270 degrees.为了防止出现过拟合,作者也进行了数据增强,具体为水平和垂直翻转,旋转图像对90度,180度,270度。
2.3 损失函数
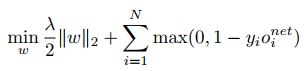
w指神经网络中的权重。o是指第i个训练样本的神经网络输出。yi∈{-1 or +1}是样本的标签,-1是指负样本对/非匹配对,+1是指正样本对/匹配对。
作者使用了一个较大的学习率1.0 with 动量 0.9.权重衰减仍使用了0.0005. 批训练的尺寸为128. 权重采用了随机初始化的方式。
如果输入的是一个负样本,那么损失函数就会增加,必须要降低网络的输出o。这就满足了输入一个负样本对,网络输出也很小,即相似度分数较低。
如果输入的是一个正样本,损失函数会随着o的增加而降低。这就满足了输入一个正样本对,网络输出很大,即相似度分数很高。
3. 结论
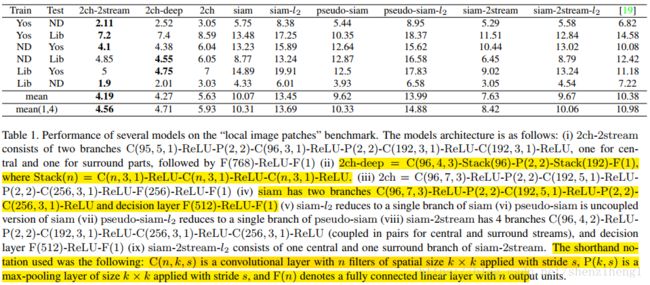
此图此表毫无疑问在支持作者的观点2-channel就是好。通过对比iii和iv确实在同等实验条件下2ch确实取得了明显的优势。这个是从实验中观测到的。具体为什么?作者也没有讲,初步感觉可能是卷积过程中,两幅图乡发生了偶联?几个卷积下来,判别性的信息更加丰富了?但是这种方法是不是可以应用到3D块匹配的学习中,我还是保留态度的,需要实际测试一下。(在做iii和iv实验对比过程中,其实结构也并不是完全一致的,有学者也提出了类似的疑问,第二个全连接层2-ch使用了256个神经元,但是Siamese就是用了512个神经元。在排除参数没有训练稳定情况下,出现这种情况确实让人惊讶)
此外,关于获得的特征图如何做相关处理?作者并没有采用相关函数计算相关系数的形式,直接采用了全连接层(只含有一个神经元),可谓简单粗暴啊!

4. 补充材料
【1】同样数目的神经元,加深网络深度模型性能要优于拓宽网络深度: K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. CoRR, abs/1409.1556, 2014. 3
【2】空间金字塔池化研究多尺度图像查询:He K, Zhang X, Ren S, et al. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904-1916.