java性能调优实战笔记

01 | 如何制定性能调优标准?
有哪些参考因素可以体现系统的性能
CPU:有的应用长期占用CPU资源,导致其他资源无法争夺到CPU而响应缓慢。如代码递归导致的无限循环,正则表达式引起的回溯,JVM频繁的FULL GC,以及多线程编程造成的大量上下文切换等。
内存:当内存空间占满时,对象无法回收,会导致内存溢出、内存泄露等。
磁盘I/O:它无法与内存的读写速度相提并论。
网络:带宽过低时,传输数据大或并发量大都会产生性能瓶颈。
异常:抛出异常需要构建异常栈,非常消耗系统性能。
数据库:大量数据库读写操作,会导致磁盘I/O性能瓶颈。
锁竞争:锁的使用会带来上下文切换,从而给系统带来性能开销。
衡量一般系统的性能的指标
响应时间:包括数据库响应时间、服务端响应时间、网络响应时间、客户端响应时间
吞吐量:包括磁盘吞吐量和网络吞吐量
计算机资源分配使用率:CPU占用率、内存使用率、磁盘I/O、网络I/O
负载承受能力:系统响应时间随着系统并发数增加而延长,直到系统无法处理这么多请求,抛出大量错误时就到了极限。
02 | 如何制定性能调优策略?
性能测试:微基准性能测试和宏基准性能测试
性能调优:优化代码、优化设计、优化算法、时间换空间、空间换时间、参数调优
兜底策略确保系统稳定性:限流熔断和扩容
03 | 字符串性能优化不容小觑,百M内存轻松存储几十G数据
String利用字符串常量池,减少同一值的字符串对象的重复创建。此外,String.intern也可以节省内存
split()方法使用正则表达式,使用不恰当会引起回溯问题,很可能导致CPU居高不下,可以用indexOf方法代替split完成字符串分割。
04 | 慎重使用正则表达式
正则表达式的优化
1、少用贪婪模式,多用独占模式。因为它会引起回溯问题
2、减少分支选择,三次indexOf效率可能会比(X|Y|Z)高
3、减少捕获嵌套
05 | ArrayList还是LinkedList?使用不当性能差千倍
对于ArrayList循环遍历,切忌不要使用for,要用iterator遍历。
加餐 | 推荐几款常用的性能测试工具
ab:适用于单个接口的性能测试。
jmeter:简单的并发测试,整个业务流程测试,组合测试,csv动态导入变量,录制测试脚本等。
LoadRunner :基本包括了jmeter的常用功能,支持ip欺骗。
06 | Stream如何提高遍历集合效率?
在串行处理操作中,Stream在执行每一步蹭操作时,并不会处理数据,而是将这些中间操作串联起来,最终由终结操作触发,生成一个数据处理链表,通过java8中的Spliterator迭代器进行数据处理;此时,每执行一次迭代,就是对所有的无状态中间操作进行数据处理,而对有状态的中间操作,就需要迭代处理完所有的数据,再进行处理操作;最后就是进行终结操作的数据处理。
在并行处理操作中,Stream对蹭操作基本跟串行处理方式一样的,但在终结操作中,Stream将结合ForkJoin框架对集合进行切分处理,ForkJoin框架将每个切片的处理结果Join合并起来。
这个 Demo 的需求是过滤分组一所中学里身高在 160cm以上的男女同学
Map> stuMap = stuList.stream().filter((Student s) -> s.getHeight() > 160) .collect(Collectors.groupingBy(Student ::getSex));
查找出一个长度最长,并且以张为姓氏的名字
List names = Arrays.asList(" 张三 ", " 李四 ", " 王老五 ", " 李三 ", " 刘老四 ", " 王小二 ", " 张四 ", " 张五六七 ");
String maxLenStartWithZ = names.stream()
.parallel()
.filter(name -> name.startsWith(" 张 "))
.mapToInt(String::length)
.max()
.toString();
环境:

stream在上述环境下的测试情况:

07 | 深入浅出HashMap的设计与优化
解决哈希冲突的方法有开放定址法、再哈希函数法、链地址法
默认LoadFactor 0.75 初始大小 16 边界值Threshold 16*0.75=12
我们还可以在预知存储数据量的情况下,提前设置初始容量(初始容量=预知数据量/加载因子)。这样做的好处是可以减少resize()操作,提高HashMap的效率。
我们初始容量时,一般是2的整数次幂,原因如下:
hashmap的元素的索引位置计算如下(n-1)&hash n为数组长度
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
2的幂次方减1都是每位为1,&操作后,这能让每一个位置都能添加到元素,均匀分布元素,减少哈希冲突,提高查询效率。
08 | 网络通信优化之I/O模型:如何解决高并发下I/O瓶颈?
传统I/O的性能问题:
1、多次内存复制,数据先从外部设备复制到内核空间,再从内核空间复制到用户空间,这就发生了两次内存复制操作。这种操作会导致不必要的数据拷贝和上下文切换,从而降低I/O的性能。
2、阻塞。发生大量连接请求时,就需要创建大量监听线程。如果线程没有数据就绪就会被挂起,然后进入阻塞状态。一旦发生线程阻塞,这些线程将会不断地抢夺CPU资源,从而导致大量的CPU上下文切换,增加系统的性能开销。
如何优化I/O操作:
1、使用缓冲区优化读写流操作
2、使用DirectBuffer减少内存复制,DirectBuffer直接将复制步骤简化为从内核空间复制到外部设备,绕过了从用户空间到内核空间的复制,减少了数据拷贝。
3、避免阻塞,优化I/O操作。Channel组件有自己的处理器,可以完成内核空间和磁盘之间的I/O操作。Selector组件不断轮询所有Channel,避免阻塞。
09 | 网络通信优化之序列化:避免使用Java序列化
java序列化的缺陷:
1、无法跨语言
2、易被攻击
3、序列化后流太大
4、序列化性能太差
推荐使用Protobuf序列化替换Java序列化
10 | 网络通信优化之通信协议:如何优化RPC网络通信?
无论从响应时间还是吞吐量上来看,单一TCP长连接 + Protobuf序列化实现的RPC通信框架都有着非常明显的优势。
RMI是JDK自带的RPC通信框架,它在高并发场景下的性能瓶颈如下:
1、java默认序列化
2、TCP短连接,在高并发情况下,大量请求会带来大量连接的创建和销毁,这对系统来说无疑是非常消耗性能的。
3、阻塞式网络I/O
一个高并发场景下的RPC通信优化路径
1、选择合适的通信协议
2、使用单一长连接
3、优化Socket通信(1)实现非阻塞I/O (2)高效的Reactor线程模型 (3)串行设计 (4)零拷贝
4、量身定做报文格式
5、编码、解码可选择Protobuf序列化
6、调整linux的TCP参数设置选项
11 | 答疑课堂:深入了解NIO的优化实现原理
Tomcat在I/O读写操作比较多时,使用NIO线程模型有明显优势。
select函数:在超时时间内,监听用户感兴趣的文件描述符上的可读可写和异常事件的发生,最大监听1024个文件描述符
poll函数与select函数功能类似,但由于它的文件描述符是链表形式存储,所以监听的文件描述符数量不受限
epoll函数使用事件驱动方式代替轮询扫描fd(文件描述符),它把文件描述符放到内核的一个事件表中,事件表基于红黑树实现,所以在大量I/O请求的场景下,插入和删除的性能高
零拷贝和线程模型优化能提高性能
线程模型有以下三个主要组件:
事件接收器Acceptor:主要负责接收请求连接
事件分离器Reactor:接收请求后,会将建立的连接注册到分离器中,依赖于循环监听多路复用器Selector,一旦监听到事件,就会将事件dispatch到事件处理器
事件处理器Handlers:事件处理器主要是完成相关的事件处理,比如读写I/O操作
单线程Reactor线程模型

多线程Reactor线程模型

主从Reactor线程模型

可以通过以下几个参数来设置Acceptor线程池和Worker线程池
acceptorThreadCount:Acceptor线程数量,默认为1
maxThreads:专门处理I/O的Worker线程数量,默认是200
acceptCount:Tomcat的Acceptor线程是负责从accept队列中取出该connection,然后交给工作线程去执行相关操作,这里acceptCount指accept队列大小
maxConnections:有多少个socket连接到Tomcat上。BIO中一个线程处理一个连接,一般maxConnections等于maxThreads,NIO中,maxConnections应该设置比maxThreads大。默认是10000。
12 | 多线程之锁优化(上):深入了解Synchronized同步锁的优化方法
jvm在jdk1.6中引入分级锁来优化synchronized,当一个线程获取锁时,首先对象锁将成为一个偏向锁,这样做是为了优化同一线程重复获取导致用户态与内核态的切换问题;其次如果有多个线程竞争锁资源,锁将会升级为轻量级锁,它适用于短时间内持有锁,且分锁交替切换的场景;轻量级锁还使用自旋锁来避免线程用户态与内核态的频繁切换,大大地提高了系统性能;但如果锁竞争太激烈了,那么同步锁将会升级为重量级锁。
在高并发场景下,当大量线程同时竞争同一个锁资源时,偏向锁会被撤销,发生stop the world后,开启偏向锁无疑会带来更大的性能开锁,可以通过jvm参数关闭偏向锁来调优系统性能。在高负载、高并发场景下,我们可以通过设置jvm参数来关闭自旋锁,优化系统性能。
动态编译实现锁消除、锁粗化、减小锁粒度可以提高系统性能。
13 | 多线程之锁优化(中):深入了解Lock同步锁的优化方法
AQS类结构中包含一个基于链表实现的等待队列(CLH队列),用于存储所有阻塞线程,AQS中有一个state变量,该变量对ReentrantLock来说表示加锁状态,该队列的操作均通过CAS实现。下图是整个获取锁的流程。

14 | 多线程之锁优化(下):使用乐观锁优化并行操作
LongAdder在高并发场景下会比AtomicInteger和AtomicLong的性能更好,代价就是会消耗更多的内存空间。
LongAdder的原理就是降低操作共享变量的并发数,就是将单一共享变量的操作压力分散到多个变量值上,将竞争的每个写线程的value值分散到一个数组中,不同线程会命中数组的不同槽中,降低竞争压力。
LongAdder在操作后返回值只是一个近似准确的数值,但是LongAdder最终返回的是一个准备的值,所以在一些实时性要求比较高的场景下,LongAdder并不能取代AtomicInteger或AtomicLong
15 | 多线程调优(上):哪些操作导致了上下文切换?
在并发程序中,并不是启动更多的线程就能让程序最大限度地并发执行。线程数量设置太小,会导致程序不能充分利用系统资源;线程数量设置太大,又可能带来资源的过度竞争,导致上下文切换带来额外的系统开销。一般单个逻辑简单,且速度相对来非常快的情况下,我们可以使用单线程。而在逻辑相对复杂场景下,等待时间长又需要大量计算的场景,建议使用多线程来提高系统的整体性能。
16 | 多线程调优(下):如何优化多线程上下文切换?
锁优化方式:
1、减少锁持有时间
2、降低锁的粒度(锁分离、锁分段)
3、非阻塞乐观锁代替竞争锁
在性能方面:
1、优化wait/notify的使用,避免上下文切换。(建议使用Lock锁结合Condition接口替代Synchronized内部锁中的wait/notify,实现等待/通知。这样做不仅可以解决Object.wait(long)无法区分等待超时还是线程被唤醒,还可以解决线程过早被唤醒的问题)
2、合理设置线程池大小,避免过多的上下文切换
3、使用协程实现非阻塞等待
4、减少Java虚拟机的垃圾回收
17 | 并发容器的使用:识别不同场景下最优容器

18 | 如何设置线程池大小?
线程池过小会使cpu得不到充分的利用,过大又会导致过多的上下文切换而增大系统开销。
19 | 如何用协程来优化多线程业务?
在Java中可以用Kilim框架来实现协程。协程是一种轻量资源,即使创建上千协程,对于系统来说也不是很大的负担。目前,java在Linux系统下采用的是用户线程加轻量级线程,一个用户线程映射到一个内核线程,即1:1线程模型。
答疑课堂:模块三热点问题解答
vmstat可以监控进程上下文切换的情况。
pidstat可以监测到具体线程的上下文切换。
jstack查看线程堆栈的运行情况。
加餐 | 什么是数据的强、弱一致性?
happen-before原则:java内存模型的一些“天然”先行发生关系,这些先行发生关系无须任何同步器就已存在。
happen-before的8大原则:
1、单线程happen-before:同一线程中,书写操作happen-before后面的操作
2、锁happen-before:同一锁的unlock操作happen-before此锁的lock操作
3、volatile的happen-before:对一个volatile变量的写操作happen-before此变量的任意操作
4、happen-before的传递性。
5、线程启动的happen-before:同一线程的start方法happen-before线程的其它方法。
6、线程中断的happen-before:对线程interrupt方法的调用happen-before被中断线程的检测到中断发送的代码
7、线程终结happen-before:线程所有操作都happen-before线程的终止检测。
8、对象创建的happen-before:一个对象的初始化完成先于它的finalize方法调用。
20 | 磨刀不误砍柴工:欲知JVM调优先了解JVM内存模型

在java6中,永久代在非堆内存区;到了Java7版本,永久代的静态变量和运行时常量池被合并到堆中;而到了Java8,永久代被元空间取代了。

方法区就是永久代,永久代与堆有交集。元空间使用本地内存。
21 | 深入JVM即时编译器JIT,优化Java编译
编译后的字节码文件主要包括常量池和方法表集合这两部分。
在字节码转换为机器码的过程中,虚拟机中还存在着一道编译,就是即时编译
虚拟机为每个方法准备了两类计数器:方法调用计数器和回边计数器。在确定虚拟机运行参数的前提下,这两个计数器都有一个确定的阈值,当计数器超过阈值溢出了,就会触发JIT编译。
编译优化技术:
1、方法内联:对于方法体代码不大又频繁调用,这个时间和空间消耗大。方法内联的优化行为就是把目标方法的代码复用到发起调用的方法之中,避免发生真实的方法调用。
一般我们可以通过如下方式提高方法内联:
- 设置jvm参数来减少热点阈值或增加方法体阈值,以便更多的方法进行内联,也意味着占用更多的内存
- 避免方法中写大量代码,习惯使用小方法体
- 尽量使用final、private、static关键字修饰方法,编码方法因为继承,会需要额外的类型检查
2、逃逸分析:是判断对象是否被外部方法引用或外部线程访问的分析技术。
- 栈上分配
- 锁消除
- 标量替换
Class.forName()除了将类的.class文件加载jvm中,还对类进行解释,执行类中的static块,还会执行静态变量赋值。ClassLoader不会做初始化,只是一个链接操作。
22 | 如何优化垃圾回收机制?


GC的吞吐量一般不能低于95%
GC的性能衡量指标:吞吐量、停顿时间、垃圾回收频率
可以通过GCViewer、GCeasy工具找开日志文件,图形化界面查看整体的GC性能
通常CMS和G1回收器的响应速度快,Paraller Scavenge回收器的吞吐量高
jdk8默认使用Parallel Scavenge(年经代)+Serial Old(老年代)垃圾收集器。
23 | 如何优化JVM内存分配?
查看堆内存配置的默认值
java -XX:+PrintFlagsFinal -version | grep HeapSize
ps -ef|grep java
jmap -heap 17284在jdk7中,默认年轻代和老年代的比例是1:2,可通过-XX:NewRatio重置该配置项,Eden和Survivor比例可通过XX:SurvivorRatio配置。在jdk7中,如果开启了-XX:+UseAdaptiveSizePolicy配置项,JVM将会动态调整Java堆中各个区域的大小以及进入老年代的年龄,-XX:NewRatio和-XX:SurvivorRatio将会失效,而jdk8是默认开启的。
jvm调优参考指标:GC频率、内存、吞吐量、延时、CPU占用
具体调优方法:
- 调整堆内存空间减少fullgc
- 调整年经代减少MinorGC
- 调整Eden、Survivor区比例
jvm内存调优通常和GC调优是互补的
full gc会对堆外内存进行回收
24 | 内存持续上升,我该如何排查问题?
#查看具体线程使用系统资源情况
top -Hp pid
#vmstat命令常用来观察进程的上下文切换
vmstat 1 3
#pidstat是sysstat中的一个组件(yum install sysstat),它是深入到线程级别的
#-r表示监控内存使用情况,1表示每秒,3表示采样次数,-t表示查看该进程下的线程内存使用率
pidstat -p 123456 -r 1 3 -t
#jstat可以监测java应用程序实时运行情况,如
jstat -gc pid
cpu占用过高排查思路
-
top 查看占用cpu的进程 pid
-
top -Hp pid 查看进程中占用cpu过高的线程id tid
-
printf '%x/n' tid 转化为十六进制
-
jstack pid |grep tid的十六进制 -A 30 查看堆栈信息定位
jvm old区占用过高排查思路
-
top查看占用cpu高的进程
-
jstat -gcutil pid 时间间隔 查看gc状况
-
jmap -dump:format=b,file=name.dump pid 导出dump文件
-
用visualVM分析dump文件
推荐两篇排查jvm问题的文章
https://mp.weixin.qq.com/s/ji_8NhN4NnEHrfAlA9X_ag
https://mp.weixin.qq.com/s/IPi3xiordGh-zcSSRie6nA
25 | 答疑课堂:模块四热点问题解答
调用substring方法会调用new String构造函数,利用原来字符串 ,如果仅仅substring获取一小段字符,而原来的string字符串被substring引用导致无法回收,从而导致内存泄露。
26 | 单例模式:如何创建单一对象优化系统性能?
Joshua Bloch大神说过:“单元素的枚举类型已成为实现Singleton的最佳方法”。它能避免反射攻击。
饿汉式单例枚举实现:
package com.shuangyueliao;
public enum K {
ONE;
private DBConnection connection = null;
K() {
connection = new DBConnection();
}
public DBConnection getConnection() {
return connection;
}
}
class DBConnection {
}
class Test {
public static void main(String[] args) {
DBConnection conn1 = K.ONE.getConnection();
DBConnection conn2 = K.ONE.getConnection();
System.out.println(conn1 == conn2);
}
}
懒汉式单例枚举实现:
package com.shuangyueliao;
class DBConnection {
private DBConnection() {
}
public static DBConnection getInstance() {
return Singleton.ONE.getConnection();
}
private enum Singleton {
ONE;
private DBConnection connection = null;
Singleton() {
connection = new DBConnection();
}
public DBConnection getConnection() {
return connection;
}
}
}
class Test {
public static void main(String[] args) {
DBConnection conn1 = DBConnection.getInstance();
DBConnection conn2 = DBConnection.getInstance();
System.out.println(conn1 == conn2);
}
}
27 | 原型模式与享元模式:提升系统性能的利器
原型模式:通过给出一个原型对象指明所创建的对象的类型,然后使用自身实现的克隆接口来复制这个原型对象。clone方法是一个本地方法,它可以直接操作内存中的二进制流,所以性能相对new实例化来说,更佳。
享元模式:主要用于减少创建对象的数量,运行共享技术有效地支持大量细粒度的对象。
28 | 如何使用设计模式优化并发编程?
如果需要传递或隔离一些线程变量时,我们可以考虑使用上下文设计模式。在数据库读写分离的业务场景中,则经常会用到ThreadLocal实现动态切换数据源操作。需要注意ThreadLocal的内存泄漏问题。
当主线程处理每次请求都非常耗时,就可能出现阻塞,这时我们可以将主线程业务分工到新的业务线程中,从而提高系统的并行处理能力。而Thread-Per-Message设计模式以及Worker-Thread设计模式则都是通过多线程分工来提高系统并行处理能力的设计模式。
29 | 生产者消费者模式:电商库存设计优化
AQS中存在一个同步队列(CLH队列),当一个线程没有获取到锁就会进入到同步队列中进行阻塞,如果被唤醒后获取到锁,则移除同步队列。除此之外,AQS还存在一个条件队列,通过addWaiter方法,可以将await()方法调用的线程放入到条件队列中,线程进入等待状态。当调用signal以及signalAll方法后,线程将被唤醒,并从条件队列中删除,之后进入到同步队列中。条件队列是通过一个单向链表实现的,所以Conition支持多个等待队列。
Lock中的Condition的await/signal/signalAll实现的生产者消费者模式,是基于Java代码层实现的,所以在性能和扩展性方法都更有优势。
30 | 装饰器模式:如何优化电商系统中复杂的商品价格策略?
代码如下:
@Data
public class Order {
private int id;
private String orderNo;
// 总支付金额
private BigDecimal totalPayMoney;
private List list;
}
@Data
public class OrderDetail {
private int id;
private int orderId;
// 商品详情
private Merchandise merchandise;
// 支付单价
private BigDecimal payMoney;
}
/**
* 商品
*/
@Data
public class Merchandise {
private String sku;
private String name;
// 商品单价
private BigDecimal price;
// 支持促销类型
private Map supportPromtions;
} /**
* 促销类型
*/
public enum PromotionType {
/**
* 优惠券
*/
COUPON
/**
* 红包
*/
, PACKET
}
/**
* 优惠券
*/
@Data
public class UserCoupon {
private int id;
private int userId;
private String sku;
private BigDecimal coupon;
}
/**
* 红包
*/
@Data
public class UserRedPacket {
private int id;
private int userId;
private String sku;
private BigDecimal redPacket;
}/**
* 促销类型
*/
@Data
public class SupportPromotions implements Cloneable {
private int id;
// 促销类型 1\优惠券 2\红包
private PromotionType promotionType;
// 优先级
private int priority;
// 用户领取该商品的优惠券
private UserCoupon userCoupon;
// 用户领取该商品的红包
private UserRedPacket userRedPacket;
@Override
protected SupportPromotions clone() throws CloneNotSupportedException {
SupportPromotions supportPromotions = null;
supportPromotions = (SupportPromotions) super.clone();
return supportPromotions;
}
}
public interface IBaseCount {
BigDecimal countPayMoney(OrderDetail orderDetail);
}public class BaseCount implements IBaseCount {
@Override
public BigDecimal countPayMoney(OrderDetail orderDetail) {
orderDetail.setPayMoney(orderDetail.getMerchandise().getPrice());
System.out.println("商品原单价金额为: " + orderDetail.getPayMoney());
return orderDetail.getPayMoney();
}
}public abstract class BaseCountDecorator implements IBaseCount {
private IBaseCount count;
public BaseCountDecorator(IBaseCount count) {
this.count = count;
}
@Override
public BigDecimal countPayMoney(OrderDetail orderDetail) {
BigDecimal payTotalMoney = new BigDecimal(0);
if (count != null) {
payTotalMoney = count.countPayMoney(orderDetail);
}
return payTotalMoney;
}
}public class CouponDecorator extends BaseCountDecorator{
public CouponDecorator(IBaseCount count) {
super(count);
}
@Override
public BigDecimal countPayMoney(OrderDetail orderDetail) {
BigDecimal payTotalMoney = new BigDecimal(0);
payTotalMoney = countCouponPayMoney(orderDetail);
return payTotalMoney;
}
private BigDecimal countCouponPayMoney(OrderDetail orderDetail) {
BigDecimal coupon = orderDetail.getMerchandise().getSupportPromtions().get(PromotionType.COUPON).getUserCoupon().getCoupon();
orderDetail.setPayMoney(orderDetail.getPayMoney().subtract(coupon));
return orderDetail.getPayMoney();
}
}public class RedPackDecorator extends BaseCountDecorator {
public RedPackDecorator(IBaseCount count) {
super(count);
}
@Override
public BigDecimal countPayMoney(OrderDetail orderDetail) {
BigDecimal payTotalMoney = new BigDecimal(0);
payTotalMoney = countCouponPayMoney(orderDetail);
return payTotalMoney;
}
private BigDecimal countCouponPayMoney(OrderDetail orderDetail) {
BigDecimal redPacket = orderDetail.getMerchandise().getSupportPromtions().get(PromotionType.PACKET).getUserRedPacket().getRedPacket();
System.out.println("红包优惠金额: " + redPacket);
orderDetail.setPayMoney(orderDetail.getPayMoney().subtract(redPacket));
return orderDetail.getPayMoney();
}
}public class PromotionFactory {
public static BigDecimal getPayMoney(OrderDetail orderDetail) {
Map supportPromotionsList = orderDetail.getMerchandise().getSupportPromtions();
IBaseCount baseCount = new BaseCount();
if (supportPromotionsList != null && supportPromotionsList.size() > 0) {
for (PromotionType promotionType : supportPromotionsList.keySet()) {
baseCount = protmotion(supportPromotionsList.get(promotionType), baseCount);
}
}
return baseCount.countPayMoney(orderDetail);
}
private static IBaseCount protmotion(SupportPromotions supportPromotions, IBaseCount baseCount) {
if (supportPromotions.getPromotionType() == PromotionType.COUPON) {
baseCount = new CouponDecorator(baseCount);
} else if (supportPromotions.getPromotionType() == PromotionType.PACKET) {
baseCount = new RedPackDecorator(baseCount);
}
return baseCount;
}
public static void main(String[] args) {
Order order = new Order();
init(order);
for (OrderDetail orderDetail : order.getList()) {
BigDecimal payMoney = PromotionFactory.getPayMoney(orderDetail);
orderDetail.setPayMoney(payMoney);
System.out.println("最终支付金额:" + orderDetail.getPayMoney());
}
}
public static void init(Order order) {
}
} 31 | 答疑课堂:模块五思考题集锦
jdk1.8中,java提供了CompleteFuture类,它是基于异步函数式编程。相对阻塞式等待返回结果,它通过回调的方式来处理计算结果,实现了异步非阻塞,从性能上来说它更加优越。在Dubbo2.7.0版本中,它也是基于CompletableFuture实现了异步通信。
应对高并发的流量削峰可以通过漏桶算法和令牌算法限流。
漏桶算法可以通过限制容量池大小来控制流量,而令牌算法可能通过限制发放令牌的速率来控制流量。
32 | MySQL调优之SQL语句:如何写出高性能SQL语句?
不适当使用sql语句会导致慢查询,如习惯使用select *或select count(*),在大数据表中使用limit m,n分页查询以及对非索引字段进行排序。
limit如果有使用应对索引,通常刚开始的分页查询效率比较理想,但越往后,分页查询的性能就越差。
例如limit 10000,10,数据库需要查询10010条记录,最后返回10条记录。也就是有10000条记录被查询出来没有被使用。
此时可利用子查询优化分页:
select * from `demo`.`order` where id> (select id from `demo`.`order` order by order_no limit 10000, 1) limit 20;
子查询遍历跟select * from `demo`.`order` limit 10000, 20差不多,而且主查询扫描了更多的行,但因为返回行数只有20行,执行效率得到了明显提升。
33 | MySQL调优之事务:高并发场景下的数据库事务调优
未提交读、已提交读、可重复读、可序列化
InnoDB中的已提交读和可重复读是基于多版本并发控制MVCC实现高性能事务。
MVCC对普通的select不加锁
34 | MySQL调优之索引:索引的失效与优化
建议使用自增字段作为主键
前缀索引能有效提高索引的查询速度
35 | 记一次线上SQL死锁事故:如何避免死锁?

CREATE TABLE `order_record` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`order_no` int(11) DEFAULT NULL,
`status` int(4) DEFAULT NULL,
`create_date` datetime(0) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `idx_order_status`(`order_no`,`status`) USING BTREE
) ENGINE = InnoDB
此时,我们会发现两个事务已经进入死锁状态。
只在可重复读或以上隔离级别下的特定操作才会取得gap lock或next-key lock,在update和delete时,除了基于唯一索引的查询之外,其它索引查询时都会获取gap lock或next-key lock,即锁住其扫描的范围。主键索引也属于唯一索引,所以主键索引是不会使用gap lock或next-key lock。
下列order_no为非唯一索引,此时又是RR事务隔离级别,所以以下select for update的加锁类型为gap lock,这里的gap范围是
(4,+∞)。
SELECT id FROM demo.order_record where order_no = 4 for update;执行查询sql语句获取的gap lock并不会阻塞,而当我们执行以下插入sql时,会在插入间隙上再次获取插入意向锁。插入意向锁其实也是一种gap锁,它与gap lock是冲突的,所以当其它事务持有该间隙的gap lock时,需要等待其它事务释放gap lock之后,才能获取到插入意向锁。
接下来的插入操作为了获取到插入意向锁,都在等待对方事务的gap锁释放,于是就造成了循环等待,导致死锁。
避免死锁的措施:
1、在InnoDB中,参数innodb_lock_wait_timout是用来设置超时时间的。
2、MySQL默认开启死锁检测机制,当检测到死锁后会选择一个最小(锁定资源最少的事务)进行回滚innodb_deadlock_detect=on
死锁的四个必要条件:互斥、占有且等待、不可强占用、循环等待。只要系统发生死锁,这些条件必然成立。
其它常见的sql死锁问题:如果我们之前使用辅助索引来更新数据库,就需要修改为使用聚簇索引来更新数据库。如果两个更新事务使用了不同的辅助索引,或一个使用了辅助索引,一个使用聚簇索引,就都有可能导致锁资源的循环等待。由于本身两个事务互斥,就构成了以上死锁的四个必要条件了。

出现死锁的步骤
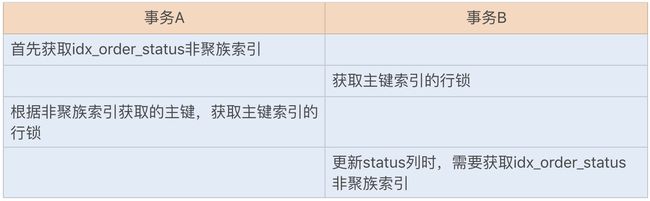
综上可知,在更新操作时,我们应该尽量使用主键来更新表字段,这样可以有效避免一些不必要的死锁发生。
36 | 什么时候需要分表分库?
在一些非海量数据的大青中,我们可以考虑使用分区来优化表性能。
我们解决分布式事务有两种通用的方式:两阶事务提交(2pc)以及补偿事务提交(tcc)
37 | 电商系统表设计优化案例分析
1、不同商品类别存在差异,如何设计商品表结构
通过一个公共表字段来存储一些具有共性的字段,创建单独的商品类型表,例如手机商品一个表、服饰商品一个表。但这种方式也有缺点,那就是可能会导致表非常多。为了更好实现全文搜索,需要结合搜索引擎,将商品详细信息存储到键值数据库。
2、双十一购物车商品数量大增,购物车系统出现性能瓶颈怎么办?
冷热数据方案来存储购物车的商品信息,用户一般都会首选最近放入购物车的商品,这些商品信息是热数据,而之前放入购物车是冷数据。将热数据提前放入redis缓存中,如将购物车近一个月的商品信息都存放到Redis中,且至少为一个分页的信息。
3、订单表海量数据,如何设计订单表结构
分表分库,对于join查询,可以冗余一些不常修改的配置表来实现,如商品的基础信息。对于分页查询,通过冗余订单信息到大数据中。后台管理系统通过大数据来查询订单信息,这种方式可以解决分表分库带来的分页查询问题。
目前互联网公司一般建议逻辑上实现各个表之间的关联,而不建议使用外键来实现实际的表关联。
38 | 数据库参数设置优化,失之毫厘差之千里

mysql改进LRU(最近最少使用)算法来实现淘汰非热点数据,默认情况下,读取到的新页并不是直接放入LRU列表的首部,而是LRU列表长度的5/8处,目的是为了避免由于一些不常查询sql偶尔一些查询就把之前热点数据淘汰的情况。
39 | 答疑课堂:MySQL中InnoDB的知识点串讲
略
40 | 如何设计更优的分布式锁?
在同样的服务器配置下,Redis的性能最好,Zookeeper次之,数据库最差。从实现方式和可靠性来说,Zookeeper实现方式简单,且基于分布式集群,可以避免单点问题,可靠性高。因此,对业务性能要求不是特别高的场景中,建议使用Zookeeper实现分布式锁。
41 | 电商系统的分布式事务调优
分布式事务的实现有多种方式,例如XA协议实现的二阶提交(2PC)、三阶提交(3PC),以及TCC补偿性事务。
2PC

2PC缺点:
1、所有节点准备完成之后,事务管理器才会发出进行全局事务提交的通知,如果这个过程很长,节点长时间占用资源,影响节点的性能。一旦资源管理器挂了,会出现一直阻塞,可以设置事务超时时间来解决。
2、仍存在数据不一致性,例如,最后通知提交全局事务时,由于网络,部分节点收不到通知而没有提交事务
3PC的出现是为了减少此类问题的发生:3PC把2PC的准备阶段分为了准备阶段和预处理阶段,第一阶段只是询问各节点可执行事务,在第二阶段,所有节点反馈可以执行事务,才开始执行事务操作,最后在第三阶段执行提交或回滚。并且在事务管理器和资源管理器中都引入了超时机制。超时之后,继续提交事务。
tcc采用最终一致性的方式实现一种柔性分布式事务。tcc是基于服务层实现的一种二阶事务提交。
43 | 如何使用缓存优化系统性能?
前端缓存技术
1、本地缓存(接口返回304状态码+Not Modified字符串)
2、网关缓存(CDN)
服务层缓存技术
1、进程缓存,因为JVM堆内存有限,一般缓存数量量不大、更新频率较低的数据
2、分布式缓存,一般不建议使用Ehcache缓存有一致性要求的数据,建议使用Redis,它读速度超过10W/s
如何解决数据库与缓存数据一致性问题?
产生原因:
1、先删除缓存,此时另一线程查询数据把旧数据放到缓存中,接着旧数据在数据库中被删除。
2、如果先去数据库删除,而缓存删除失效同样数据会出现不一致。
所以,我们还是需要先做缓存删除再去完成数据库操作
可以使用一个线程安全队列来缓存更新或删除数据,当A操作变更数据时,会先删除缓存,此时通过线程安全方式将缓存数据存到队列中,并通过一个线程进行数据库的数据删除操作。当有另一个查询请求B进来时,发现缓存中没有该值,则会去队列查看数据是否在被更新或删除,如果队列有则阻塞等待,直到A操作数据库成功后唤醒线程再去数据库中查询数据。
我们在考虑缓存时,如果数据更新比较频繁且对数据有一定的一致性要求,通常不建议使用缓存。
44 | 记一次双十一抢购性能瓶颈调优
无论是服务宕机还是异步发送给MQ,都存在请求数据丢失的可能。例如,当第三方支付回调系统时,写入订单成功了,此时通过异步来扣减库存和累计积分,如果应用服务挂了,MQ还没有存储到消息,那即使重启服务,请求数据也无法复原。
重试机制是还原丢失消息的一种解决方案。在以上的回调案例中,我们可在写入订单时,同时在数据库写入一条异步消息状态,之后再返回第三方支付操作成功结果。在异步业务处理请求成功后,更新该数据库表中的异步消息状态。假设我们重启服务,那么系统就会重启时去数据库中查询是否有未更新的异步消息,如果有则重新生成MQ业务处理消息,供各个业务方消费处理丢失的请求数据。
Nginx是基于漏桶算法实现的限流,这样能够保证请求的实时处理速度。
问题:在提交订单之后会进入支付阶段,此时系统是冻结了库存的,一般我们会给用户一定的等待时间,这样容易出现一些用户恶意锁库存,导致抢到商品的用户没办法去支付购买该商品。
可在预扣库存前设置一个购买资格,购买资格是300,预扣库存是100不变,不会出现商品超卖的问题。