GeoServer集群部署及性能测试(在虚拟机上实现)
(有个别细微问题我后续还要补充,欢迎提问)
概述
应用vmware在本地构建linux虚拟机集群,包括一个nginx节点,三个GeoServer节点,三个GlusterFS文件系统节点。
软件准备
1.geoserver软件(使用tomcat作为web容器)
2.nginx
3.glusterFS
虚拟系统准备
在vmware中克隆三台CentOS 7 虚拟机,分别安装nginx,geoserver,gfs。
其他几个节点直接再克隆已有的节点,修改相关配置文件。
具体步骤
1.由centos 7 64位虚拟机模板克隆nginx虚拟机节点

虚拟机的设置如下:
注意一定要使用NAT模式,以使得该虚拟机使用宿主机的IP访问公网。
使用NAT模式,就是让虚拟系统借助NAT(网络地址转换)功能,通过宿主机器所在的网络来访问公网。也就是说,使用NAT模式可以实现在虚拟系统里访问互联网。NAT模式下的虚拟系统的TCP/IP配置信息是由VMnet8(NAT)虚拟网络的DHCP服务器提供的,无法进行手工修改,因此虚拟系统也就无法和本局域网中的其他真实主机进行通讯。采用NAT模式最大的优势是虚拟系统接入互联网非常简单,你不需要进行任何其他的配置,只需要宿主机器能访问互联网即可。
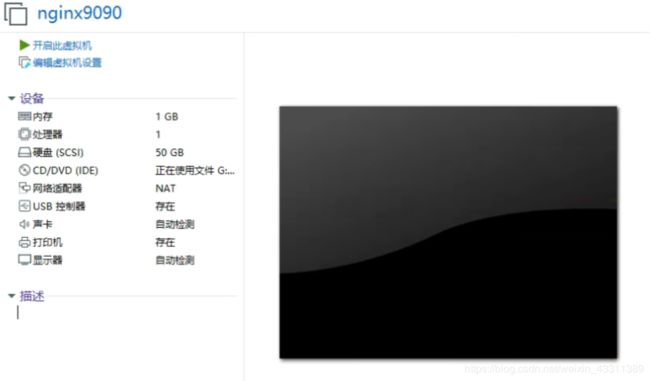
开启虚拟机,开始配置虚拟机的网络。

修改克隆虚拟机的静态IP,修改网卡配置文件
vim /etc/sysconfig/network-scripts/ifcfg-ens33
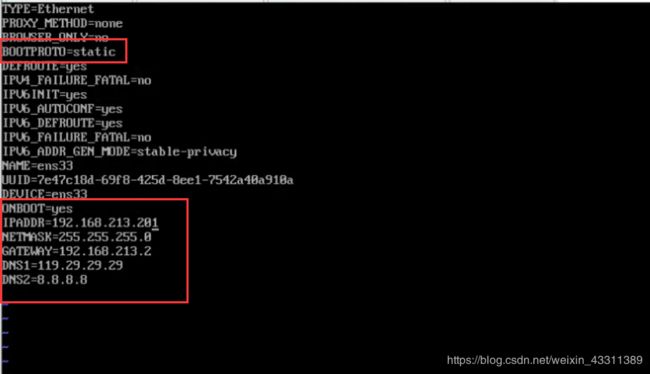
其中IPADDR为该虚拟机在宿主机局域网中的IP,最后的201为我自己规定的,前面的213要查看vmnet8的子网地址,如果没有设置正确,是连不到宿主机的。
在vmware中,编辑–》虚拟网络编辑器可查看。
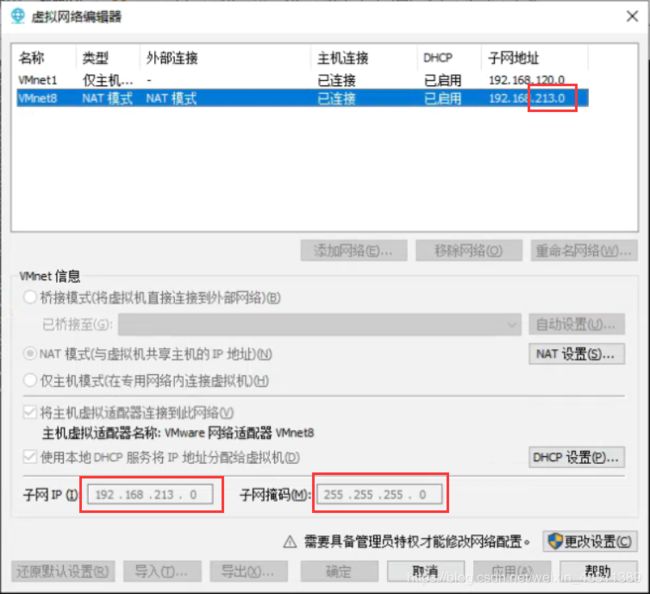
子网掩码填写也如上图。
网关的填写也是有依据的,点击NAT设置,查看网关:

DNS服务器可以只配一个,我用的是两个免费的dns服务器。
Esc :wq保存并退出。
重启网络服务
systemctl restart network
修改主机名称
[root@localhost ~] hostnamectl set-hostname nginx201
[root@localhost ~] hostnamectl --pretty
[root@localhost ~] hostnamectl --static
[root@localhost ~] hostnamectl --transient
nginx201
修改hosts文件,添加如下域名
vim /etc/hosts
192.168.213.201 nginx201
192.168.213.202 geoserver202
192.168.213.203 geoserver203
192.168.213.204 geoserver204
192.168.213.130 gfs130
192.168.213.131 gfs131
192.168.213.132 gfs132

重启虚拟机
reboot
检查hostname 和ifconfig信息。
关机克隆该虚拟机为geoserver202,geoserver203,geoserver204
需要在geoserver202,geoserver203,geoserver204修改的为
1.本机静态IP(分别为192.168.213.202,192.168.213.203,192.168.213.204)
2.主机名(分别为geoserver202,geoserver202,geoserver204)
3.hosts不用再配置。
方法同上。
配完之后互相ping一下测试联通性。

ping不通的话看看windows防火墙关了没。
配完之后就可以使用xshell连接了,vmware里不能复制粘贴太难受。
在nginx201上安装nginx。
略。
配置nginx集群:
打开nginx.conf
vi /usr/local/nginx/conf/nginx.conf
修改如下配置
upstream mygeoserver {
ip_hash;
server 192.168.213.202:8080;
server 192.168.213.203:8080;
server 192.168.213.204:8080;
}
server {
listen 9090;
server_name 192.168.213.201;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
#root html;
#index index.html index.htm;
proxy_pass http://mygeoserver;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
# proxy the PHP scripts to Apache listening on 127.0.0.1:80
#
#location ~ \.php$ {
# proxy_pass http://127.0.0.1;
#}
# pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000
#
#location ~ \.php$ {
# root html;
# fastcgi_pass 127.0.0.1:9000;
# fastcgi_index index.php;
# fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name;
# include fastcgi_params;
#}
# deny access to .htaccess files, if Apache's document root
# concurs with nginx's one
#
#location ~ /\.ht {
# deny all;
#}
}
读取nginx.conf,启动nginx
/usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.conf
在geoserver202,203,304上传jdk,tomcat,geoserver.war
创建目录
mkdir /opt/software
mkdir /opt/module
将软件包放在software目录下,将安装位置放在module下(三个节点都这样操作)。
1.安装jdk(略)
2.安装tomcat(略)
3.部署geoserver项目
将geoserver.war放在webapps目录下:

启动tomcat,自动解压并部署项目

浏览器访问成功。如果没成功,检查端口是否开放。
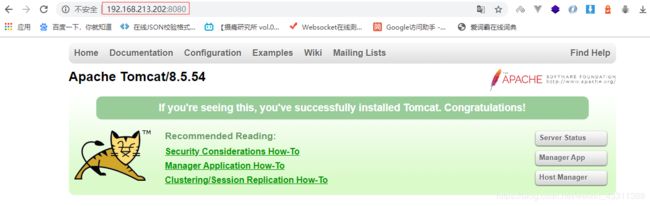
访问geoserver web管理页面

三个节点都这样布置完并启动后,集群还并不能够使用。因为三个geoserver节点所使用的数据目录并不一致,我们要将其配置到统一的文件系统路径上。所以我们接下来搭建GlusterFS分布式文件系统。
1.克隆三台虚拟机,分别为gfs130,gfs131,gfs132。各自需要修改的配置有:
- 静态ip;
- hosts文件 域名映射;
- 主机名;
修改静态ip(各个节点ip为130,131,132):
vim /etc/sysconfig/network-scripts/ifcfg-ens33
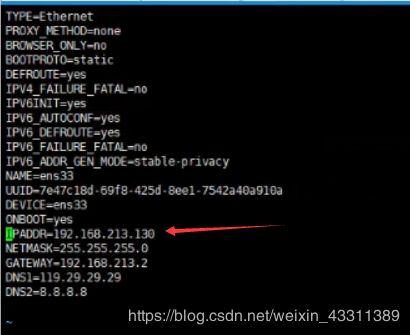
修改hosts文件映射
vim /etc/hosts
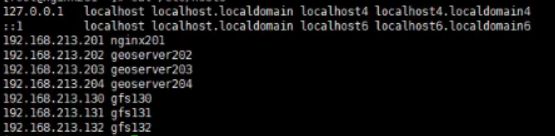
修改主机名
hostnamectl set-hostname gfs130
hostnamectl --pretty
hostnamectl --static
hostnamectl --transient
reboot重启机器。
修改另外两个文件系统节点的配置信息。
基本信息修改完后,在另三台机器上安装GlusterFS。
步骤如下:
安装glusterfs(三台都要执行)
#安装glusterfs
yum install centos-release-gluster
yum install -y glusterfs glusterfs-server glusterfs-fuse glusterfs-rdma
#启动gluster服务
systemctl start glusterd.service
systemctl enable glusterd.service
在gfs132上执行,将gfs130,gfs131加入集群
gluster peer probe gfs130
gluster peer probe gfs131
在gfs132上看集群状态
[root@gfs132 ~]# gluster peer status
Number of Peers: 2
Hostname: gfs131
Uuid: 9a746d3b-ee5e-4f6a-9bb5-f437dc871fcf
State: Peer in Cluster (Connected)
Hostname: gfs130
Uuid: 1625a441-fd0f-47cd-ab13-f1cf97dc407d
State: Peer in Cluster (Connected)
[root@gfs132 ~]#
在gfs132上执行,创建3副本的复制卷。glusterfs使用现有Linux文件系统创建glusterfs文件系统。
#创建卷
[root@gfs132 ~]# gluster volume create app-data replica 3 transport tcp gfs130:/gfs-data/ gfs131:/gfs-data/ gfs132:/gfs-data/ force
volume create: app-data: success: please start the volume to access data
# 列出卷
[root@gfs132 ~]# gluster volume list
app-data
#查看卷信息
[root@gfs132 ~]# gluster volume info
Volume Name: app-data
Type: Replicate
Volume ID: a3f4999a-bfcd-4db5-8a4d-b040568ffa20
Status: Started
Snapshot Count: 0
Number of Bricks: 1 x 3 = 3
Transport-type: tcp
Bricks:
Brick1: gfs130:/gfs-data
Brick2: gfs131:/gfs-data
Brick3: gfs132:/gfs-data
Options Reconfigured:
performance.client-io-threads: off
nfs.disable: on
storage.fips-mode-rchecksum: on
transport.address-family: inet
features.quota: on
features.inode-quota: on
features.quota-deem-statfs: on
[root@gfs132 ~]#
# 启动卷
[root@gfs132 ~]# gluster volume start app-data
volume start: app-data: success
[root@gfs132 ~]# gluster volume quota app-data enable
volume quota : success
[root@gfs132 ~]# gluster volume quota app-data limit-usage / 30GB
volume quota : success
# 查看卷状态
[root@gfs132 ~]# gluster volume status
Status of volume: app-data
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick gfs130:/gfs-data 49152 0 Y 1120
Brick gfs131:/gfs-data 49152 0 Y 1112
Brick gfs132:/gfs-data 49152 0 Y 1346
Self-heal Daemon on localhost N/A N/A Y 1366
Quota Daemon on localhost N/A N/A Y 1355
Self-heal Daemon on gfs131 N/A N/A Y 1138
Quota Daemon on gfs131 N/A N/A Y 1101
Self-heal Daemon on gfs130 N/A N/A Y 1140
Quota Daemon on gfs130 N/A N/A Y 1129
Task Status of Volume app-data
------------------------------------------------------------------------------
There are no active volume tasks
[root@gfs132 ~]#
#挂载 将创建的app-data卷挂载到gfs132 的/gfs-share 目录上。
[root@gfs132 ~]# mkdir /gfs-share && mount -t glusterfs gfs132:app-data /gfs-share
#开机自动挂载
[root@node-1 ~]# echo "localhost:app-data /gfs-share/ glusterfs defaults 0 0" >> /etc/fstab
查看/gfs-share目录。上传测试文件到该目录下。如果文件系统中其他节点下gfs-data看到了上传的文件,证明实现了文件共享,GlusterFS集群基本搭建完成。

在gfs130和gfs131的/gfs-data中


geoserver集群访问GlusterFS文件系统集群
前面提到了让各个GeoServer节点能够访问统一的文件系统目录,这里就介绍如何将GFS集群的app-data卷挂载到geoserver各个节点上。
但是在真正让geoserver节点可访问文件系统集群之前,需要做另外一个工作:集群时间同步。集群时间不同步会导致对数据的计划任务等不协调,造成数据混乱。更重要的是,集群时间不同步,GFS文件系统的卷,是不会让你挂载到客户端来访问的。
关于集群时间同步的详细内容,请问一下度娘。
随意选择一个节点做集群时间服务器,其他几个节点开启定时任务和该节点进行时间同步。
时间服务器配置(必须root用户)
(1)检查ntp是否安装
[root@gfs132~]# rpm -qa|grep ntp
ntp-4.2.6p5-10.el6.centos.x86_64
ntpdate-4.2.6p5-10.el6.centos.x86_64
(2)修改ntp配置文件
vi /etc/ntp.conf
修改内容如下
a)修改1(授权192.168.213.0-192.168.213.255网段上的所有机器可以从这台机器上查询和同步时间)
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap为
restrict 192.168.213.0 mask 255.255.255.0 nomodify notrap
b)修改2(集群在局域网中,不使用其他互联网上的时间)
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst为
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
c)添加3(当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步)
server 127.127.1.0
fudge 127.127.1.0 stratum 10
(3)修改/etc/sysconfig/ntpd 文件
[root@gfs132 ~]# vim /etc/sysconfig/ntpd
增加内容如下(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes
(4)重新启动ntpd服务
[root@gfs132 ~ ]# service ntpd status
...
[root@gfs132 ~ ]# service ntpd start
(5)设置ntpd服务开机启动
[root@gfs132 ~ ]# chkconfig ntpd on
其他机器配置(必须root用户)
(1)在其他机器配置10分钟与时间服务器同步一次
[root@geoserver202 ~]# crontab -e
编写定时任务如下:
*/10 * * * * /usr/sbin/ntpdate gfs132
[root@geoserver202 ~]# crontab -e
no crontab for root - using an empty one
crontab: installing new crontab
[root@geoserver202 ~]#
geoserver节点安装GlusterFS客户端
配置完集群时间同步后,在每一台geoserver节点上安装GlusterFS客户端,去挂载文件服务器的卷。
1.安装客户端,逐一运行如下命令
yum install centos-release-gluster
yum -y install glusterfs
yum -y install glusterfs-client
mkdir /mnt/glusterfs
mount -t glusterfs gfs132:app-data /mnt/glusterfs
echo "gfs132:app-data /mnt/glusterfs/ glusterfs defaults 0 0" >> /etc/fstab
需要注意的是,客户端的glusterfs 版本一定要和server端一致。否则会出现挂载失败的问题。我这里是如下版本:
Package glusterfs-7.5-1.el7.x86_64 already installed and latest version
挂载成功后,查看挂载目录,发现能访问到之前上传的测试数据。
为geoserver软件设置统一GFS文件路径
修改geoserver的数据目录
在确保了glusterfs集群正确启动,客户端正确挂载的情况下,将如下路径的文件配置参数进行修改。
/opt/module/apache-tomcat-8.5.54/webapps/geoserver/WEB-INF/web.xml
将geoserver的数据目录修改为挂载上的GFS共享文件目录,如下所示:
-param>
<param-name>GEOSERVER_DATA_DIR</param-name>
<param-value> /mnt/glusterfs</param-value>
</context-param>
查看geoserver web管理页面,如果数据被清空或更新为当前数据目录下的内容,证明配置生效。如果还是默认的那些服务,重启geoserver即可。
发布wmts服务进行性能测试
用ftp将大小为900M的tiff上载至gfs132:gfs-share目录下。实现各节点数据共享。上传的文件较大时,客户端可能会有延迟显示文件信息(稍等一会儿,客户端刷新几次,具体为什么会这样,我的研究深度有限,目前还未做深入探究)。
首先用geoserver发布wms服务。
如下图
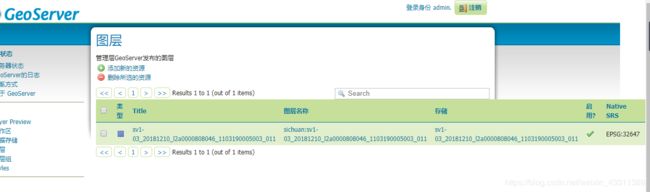
我现在可以直接用如下代码按照wms服务的方式去访问了
var aerial = new Cesium.WebMapServiceImageryProvider({
url: 'http://192.168.213.201:9090/geoserver/sichuan/wms',//使用nginx代理
layers: 'sichuan1:sv1-03_20181210_l2a0000808046_1103190005003_011',
parameters: {
service: 'WMS',
format: 'image/png',
transparent: true
}
});
viewer.imageryLayers.addImageryProvider(aerial);
但是为了提高服务访问速度,我们采用wmts服务的方式来进行访问。点击“tile layer”,找到对应的服务,选择一种预览方式,查看服务情况。
放大缩小没有问题,第一次浏览可能会有些卡顿,这是因为访问这个服务geoserver在给这副地图实时生成瓦片,多预览一段时间后会好的多。另外初期可能在控制台上得到许多400 bad request错误,没有关系,那是因为有的瓦片还没生产出来,只要有正确的瓦片返回,则服务是没有问题的。

生成的瓦片存储在我们设定的数据目录下
多浏览几次该服务,会越来越流畅。
另外的话,可以用geoserver内嵌的geowebcache预先为服务生成切片,不在服务访问的时候实时生产瓦片,进一步提高访问速度。请参考我的博客:
geoserver生产地图瓦片并发布wmts服务,并用cesium进行加载
链接-----------------------------------------------------
https://blog.csdn.net/weixin_43311389/article/details/99979275
使用cesium加载wmts服务
要加载发布图层的切片地图服务,我们首先要找到几个重要参数:
工作空间:图层名称

服务地址:
http://192.168.213.202:8080/geoserver/gwc/service/wmts/rest/sichuan:sv1-03_20181210_l2a0000808046_1103190005003_011/{style}/{TileMatrixSet}/{TileMatrix}/{TileRow}/{TileCol}?format=image/png
获取方式:

打开wmts能力文档后,搜索对应的工作空间名称和图层名

向下查找找到对应的服务链接

另外还需要找到style,坐标系等参数,我这里的服务没有设置那么多,用默认值就可以了。
选择获取tile对象的ResourceURL,style是图层样式,TileMatrixSet是采用瓦片坐标系格式,TileMatrix(url需要将{TileMatrix}改为{TileMatrixSet}:{TileMatrix})代表该坐标系下的缩放级别,TileRow和TileCol代表着瓦片行列坐标。
var wmtsImageryProvider = new Cesium.WebMapTileServiceImageryProvider({
url: 'http:///192.168.213.201:9090/geoserver/gwc/service/wmts/rest/sichuan:sv1-03_20181210_l2a0000808046_1103190005003_011/{style}/{TileMatrixSet}/{TileMatrixSet}:{TileMatrix}/{TileRow}/{TileCol}?format=image/png',
layer: 'sichuan:sv1-03_20181210_l2a0000808046_1103190005003_011',
style: '',
format: 'image/png',
tileMatrixSetID: 'EPSG:900913' //一般使用EPSG:3857坐标系
});
viewer.imageryLayers.addImageryProvider(wmtsImageryProvider);
效果
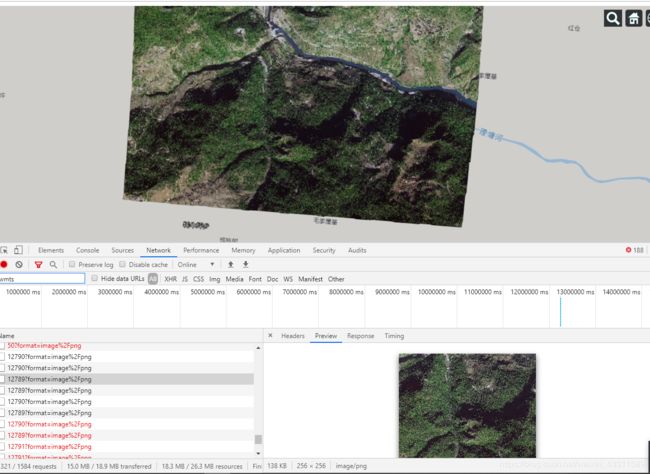
打开控制台,查看请求,可以看到每次请求发送的具体参数,其中一个例子是:
http://192.168.213.201:9090/geoserver/gwc/service/wmts/rest/sichuan:sv1-03_20181210_l2a0000808046_1103190005003_011//EPSG%3A900913/EPSG%3A900913:13/3199/6698?format=image%2Fpng
这个链接的意思就是访问这个wmts瓦片服务在EPSG:900913坐标系下第13级,3199行,6698列的一个瓦片数据。
注意事项
使用nginx做负载均衡,如果做了ip_hash,是以用ip_hash,户(一个用户访问ip)为单位的,一旦nginx分配了一个节点为该用户提供服务,那么无论后续这个用户访问量再大,并发请求数再多,也只使用被分配的这个节点来处理。其他节点不会帮忙计算,就是一个干,六个看。
那nginx起到了什么作用呢?它其实是用来处理多用户并发的,它将来自不同用户的请求分发给不同的节点负责处理,达到了负载均衡的目的。就单个用户来说,即使这个用户访问量再大,也不会调动其他节点来帮忙,它只应用他被分配的节点的资源,nginx的作用没有发挥。
那么geoserver服务的响应时间受什么影响呢?我画了一张草图做了一些分析:

可以看到,一个服务的响应时间为请求等待时间+服务器计算时间+网页内容下载时间+浏览器渲染时间。我们这里讨论服务端的性能,就把最后两项浏览器的参数去掉,只留前两项。
如果当前服务请求没有达到geoserver服务器能承受的最大并发数,则响应时间只受服务器计算时间的影响,就是服务器性能本身。如果当前超过了最大并发数,则需要进行等待,响应时间即为等待时间和计算时间之和。
现在遇到一个问题,就是我需要知道,如果要求的响应时间为5S,能处理多大的并发数呢?假设每个地图用户访问平均发起50个地图服务请求,算出这个并发数处以50,就是单个节点5S内能够同时服务的用户数。
编写脚本以不同地图范围参数瞬时访问该地图服务,查看5S之内能返回多少个请求,即为要求的并发数。

在我的节点资源为8C/3g的时候,5秒能够处理2000并发。所以折合成用户数,就是可以同时满足40用户同时访问。
脚本编写待续
整理待续
补充待续