Flink on zepplien的安装配置
Apache Zeppelin 是一个让交互式数据分析变得可行的基于网页的notebook。Zeppelin提供了数据可视化的框架。Flink结合zepplien使用可以让提交Flink任务变的简单化. 从Zeppelin 0.9开始将正式支持Flink 1.10。Flink是一个批流统一的计算引擎,本文将从第一个wordcount的例子为起点来介绍一下Flink on zeplien(on yarn)的配置和使用.
版本说明:
Flink 1.11.0
zepplien: 0.9.0
hadoop 2.9.0
安装配置zepplien
下载安装完后要进行几个简单的配置,不能直接启动,否则后面使用会遇到报错,这里我也是遇到了几个问题,搞了差不多2个小时,才把第一个任务跑起来.
1, tar -zxvf zeppelin-0.9.0-SNAPSHOT.tar.gz
cd zeppelin-0.9.0-SNAPSHOT/conf
mv zeppelin-env.sh.template zeppelin-env.sh
这里面需要添加两个配置
export JAVA_HOME=/home/jason/bigdata/jdk/jdk1.8.0_221
export ZEPPELIN_ADDR=storm1
JAVA_HOME需要指定JDK的路径,并且JDK的版本需要高一点的版本,不然提交任务的时候会遇到下面的报错
org.apache.zeppelin.interpreter.InterpreterException: java.io.IOException: Fail to launch interpreter process:
Apache Zeppelin requires either Java 8 update 151 or newer
at org.apache.zeppelin.interpreter.remote.RemoteInterpreter.open(RemoteInterpreter.java:134)
at org.apache.zeppelin.interpreter.remote.RemoteInterpreter.getFormType(RemoteInterpreter.java:298)
at org.apache.zeppelin.notebook.Paragraph.jobRun(Paragraph.java:433)
at org.apache.zeppelin.notebook.Paragraph.jobRun(Paragraph.java:75)
at org.apache.zeppelin.scheduler.Job.run(Job.java:172)
at org.apache.zeppelin.scheduler.AbstractScheduler.runJob(AbstractScheduler.java:130)
at org.apache.zeppelin.scheduler.RemoteScheduler$JobRunner.run(RemoteScheduler.java:159)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.io.IOException: Fail to launch interpreter process:
Apache Zeppelin requires either Java 8 update 151 or newer
at org.apache.zeppelin.interpreter.remote.RemoteInterpreterManagedProcess.start(RemoteInterpreterManagedProcess.java:130)
at org.apache.zeppelin.interpreter.ManagedInterpreterGroup.getOrCreateInterpreterProcess(ManagedInterpreterGroup.java:65)
at org.apache.zeppelin.interpreter.remote.RemoteInterpreter.getOrCreateInterpreterProcess(RemoteInterpreter.java:110)
at org.apache.zeppelin.interpreter.remote.RemoteInterpreter.internal_create(RemoteInterpreter.java:163)
at org.apache.zeppelin.interpreter.remote.RemoteInterpreter.open(RemoteInterpreter.java:131)
... 13 more
我的JDK版本之前是jdk1.8.0_111,改成jdk1.8.0_221后才可以运行的.
ZEPPELIN_ADDR需要配置成ip地址或者host,如果你的zepplien不是安装在本机的话,否则无法通过ip+port进行访问,或者也可以修改zeppelin-site.xml配置文件里面的zeppelin.server.addr也可以的.
zeppelin.server.addr
storm1
Server binding address
添加hadoop的依赖包
因为要用yarn来调度Flink任务,所以还需要把 flink-shaded-hadoop-2-uber-2.8.3-10.0.jar 这个jar包添加到zeppelin的lib下面.
然后就可以启动zeppelin了,到bin目录下执行
zeppelin-daemon.sh start 如果看到控制台正常输出Zeppelin start [ OK ],那就说明安装完成, 为了确保启动成功了,可以再到log下面看下日志,有没有报错的信息.
在浏览器里面输入ip+port就可以看到zeppelin的UI界面了,如下所示:

配置 Flink Interpreter
在 Zeppelin 中可以使用 3 种不同的 Flink 集群模式。
1, Local
2, Remote
3, Yarn
这里主要介绍yarn的配置方法,local和remote的配置自己可以去试一下.
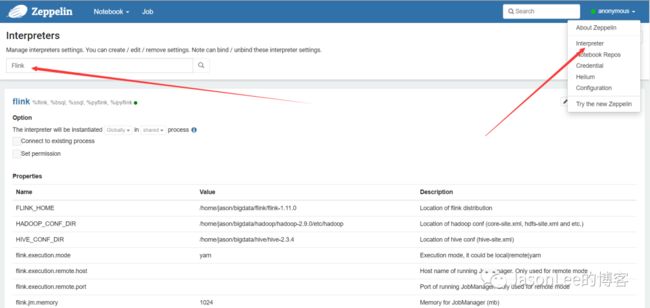
点击右上角的Interpreters进入配置页面,然后在左上角的搜索框输入Flink就可以看到下面有很多Flink相关的配置,点击edit就可以配置了.
其实on yarn模式主要配置前面3个就可以了.
FLINK_HOME /home/jason/bigdata/flink/flink-1.11.0
HADOOP_CONF_DIR /home/jason/bigdata/hadoop/hadoop-2.9.0/etc/hadoop
flink.execution.mode yarn
flink.yarn.queue flink
第4个 flink.yarn.queue 队列其实可以不用配置默认的是default,但是我的队列把default去掉了.所以是需要配置的.
其次还需要注意下面的几个配置,需要根据自己的集群资源合理的设置,不要超过集群可用的资源.

点击首页面的Flink Basics,zeppelin自带了几个Flink的demo,先跑一下demo看是否能跑通.
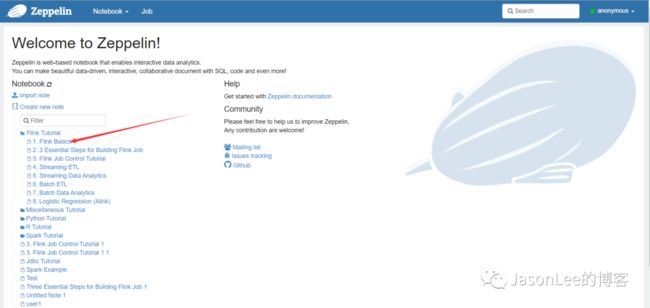
直接点击运行就可以了,我这里是自己修改了,原始的有batch,streaming的demo.随便跑一个就行.
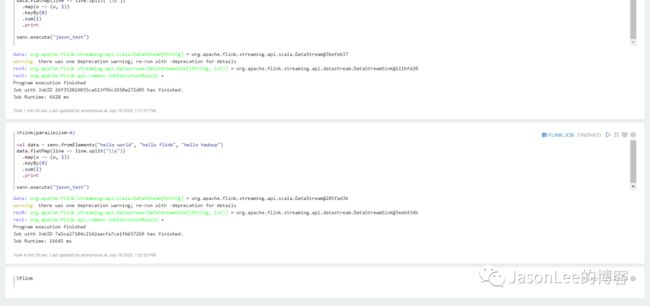
你会发现任务启动不了,还是报上面的JDK版本过低的问题,虽然我们在上面已经设置过了环境变量,但是zeppelin启动Interpreter的时候,没有把环境变量传入,具体的解决方法如下: 需要修改zeppelin/bin目录下的common.sh文件.
直接找到66行,把java_ver_output=$("${JAVA:- 后面的改为自己的JDK的路径就可以了,重启一下zeppelin. 然后再点刚才的运行按钮, zeppelin会先在yarn上启动一个session模式的集群,然后在把任务提交到这个集群上.
点击右上角的Flink job就可以跳到Flink的WEB UI看到Job的详细信息如下图所示.
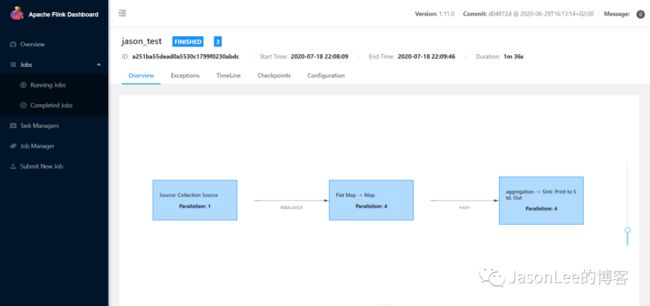
再来看一下最后打印的结果是否正确,在taskmanager的stdout可以看到输出的结果.

结果也没有问题,还需要注意任务的并行度不能大于slot的总数,如果想要修改并行度的话可以在paragraph里面设置如下所示:
%flink(parallelism=4)
val data = senv.fromElements("hello world", "hello flink", "hello hadoop")
data.flatMap(line => line.split("\\s"))
.map(w => (w, 1))
.keyBy(0)
.sum(1)
.print
senv.execute("jason_test")
在zeppelin里面点击完运行后,需要耐心的等待一会儿,整个任务提交的过程感觉还是有点慢,多等一会儿就行了,如果等了很长时间任务还没提交成功,可以到zeppelin的log下面看下打印的日志有没有报错,一定要看日志,可以帮助我们快速的定位问题.
这篇文章主要介绍了Flink on zeppelin的安装以及配置,如何在on yarn模式上提交一个streaming的任务.后面会有更多关于zeppelin的使用介绍.
更多spark和flink的内容可以关注下面的公众号

推荐阅读:
Flink源码分析:WindowOperator底层实现
JasonLee,公众号:JasonLee的博客Flink源码分析:WindowOperator底层实现