tomcat日志监控——flume+kafka+storm+hbase
tomcat日志监控到现在为止已经基本完成,之前我已经说了flume+kafka的相关原理和配置。大家可以看我之前写的文章https://blog.csdn.net/xxs120/article/details/79925393
今天我接着讲我和我的小伙伴们一起完成的过程。
1.kafka消费遇到的问题(望各位提出建议)
flume和kafka已经完成配置,也能实现kafka消费者消费数据。但是我们发现经常出现kafka消费数据重复,我们在网上查阅了很多资料,大部分都是说offset没有正确提交而导致的。但是一直都没有找到解决办法,我们尝试先让flume把日志发送到文件,发现是可以的。然后又改为发送给kafka,咦,又可以消费了,但是依然会遇到重复消费问题。当然,不可能说每次遇到重复消费问题时就做如上调整吧。这明显是不可行的,最后,我直接把flume的版本换成1.8.0的,现在还没有出现问题,不知道是不是实质性的解决的。所以小编在这里希望各位大佬们知道原因的话能够评论回复我,告诉我们原因及解决办法,在此谢谢各位!
当然,我也有猜想,我们知道kafka每次消费都是先消费数据,然后就把数据对应的位置偏移量发送给zookeeper,会不会每次我们测试的时候总是强制关闭消费,导致数据消费了,offset还没有提交,所以出现了重复消费问题。因为确实如果一直消费不关闭的话是没有此问题的,至少我目前没有遇到。希望大家来一起探讨探讨此问题。
2.java代码实现kafka消费数据
为了项目的可行性和规范化,我们使用java代码实现kafka消费数据,要实现这个,注意一些配置即可。直接附上我的代码:
package com.rednum.hadoopwork.kafka;
import java.util.Collections;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import kafka.utils.ShutdownableThread;
public class KafkaConsumerDemo {
public static void main(String[] args) {
Consumer consumerThread=new Consumer(KafkaProperties.TOPIC);
consumerThread.start();
}
}
class Consumer extends ShutdownableThread {
private final KafkaConsumer consumer;
private final String topic;
public Consumer(String topic) {
super("KafkaConsumerExample", false);
Properties props = new Properties();
//配置信息
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.1.208:9092,192.168.1.207:9092,192.168.1.211:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "DemoConsumer");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "60000");
// 序列化key
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.IntegerDeserializer");
// 序列化value
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringDeserializer");
consumer = new KafkaConsumer(props);
this.topic = topic;
}
@Override
public void doWork() {
// 消费者订阅的topic
consumer.subscribe(Collections.singletonList(this.topic));
// 读取数据,读取超时时间为100ms
ConsumerRecords records = consumer.poll(100);
for (ConsumerRecord record : records)
{
//打印日志
System.out.println(
"("+record.value() + ")at offset " + record.offset());
}
}
@Override
public String name() {
return null;
}
@Override
public boolean isInterruptible() {
return false;//在运行中,不能抢占消费者的资源
}
}
class KafkaProperties {
//消费主题
public static final String TOPIC="test1";
// public static final String KAFKA_SERVER_URL="192.168.1.208";
// public static final int KAFKA_SERVER_PORT=9092;
// public static final int KAFKA_PRODUCER_BUFFER_SIZE = 64 * 1024;
// public static final int CONNECTION_TIMEOUT = 100000;
private KafkaProperties(){}
} 3.storm连接kafka
因为我们监控的是tomcat日志,实时产生,所以我们采用流式框架Storm.首先来理解一下storm的原理
1.什么是storm?
Storm是基于数据流的实时处理系统,提供了大吞吐量的实时计算能力。通过数据入口获取每条到来的数据,在一条数据到达系统的时候,立即会在内存中进行相应的计算;Storm适合要求实时性较高的数据分析场景。
2.storm集群的基本组件
storm的集群表面上看和hadoop的集群非常像。但是在Hadoop上面你运行的是MapReduce的Job, 而在Storm上面你运行的是Topology。它们是非常不一样的 , 一个关键的区别是: 一个MapReduce Job最终会结束, 而一个Topology运永远运行(除非你显式的杀掉他)。
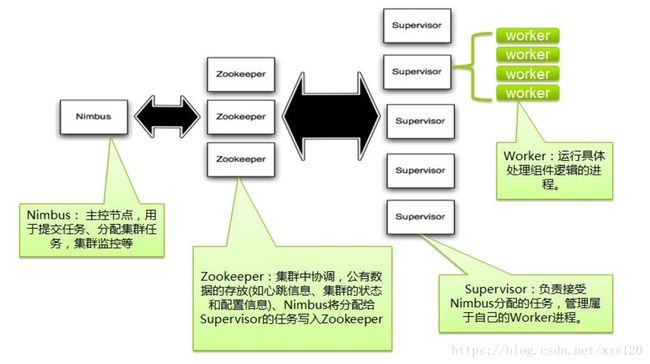
在Storm的集群里面有两种节点: 控制节点(master node)和工作节点(worker node)。控制节点上面运行一个后台程序:Nimbus, 它的作用类似Hadoop里面的JobTracker。Nimbus负责在集群里面分布代码,分配工作给机器, 并且监控状态。每一个工作节点上面运行一个叫做Supervisor的节点(类似 TaskTracker)。Supervisor会监听分配给它那台机器的工作,根据需要 启动/关闭工作进程。每一个工作进程执行一个Topology(类似 Job)的一个子集;一个运行的Topology由运行在很多机器上的很多工作进程 Worker(类似 Child)组成。
3.storm组件和hadoop组件的区别

我们知道hadoop之间其实是以键值对的形式作为数据模型,而storm是以tuple元组的形式作为数据模型。Spout组件主要是获取数据源,Bolt主要是处理数据,计算数据,然后传向其他数据容器,如:MySQL,HBASE等等。
4.Storm连接Kafka
在开发之前一定要记得storm的安装与配置,为了匹配我们的kafka版本,我们用的storm1.1.1,安装与配置教程我在这里就不多说了,大家可以自己到网上去查查,过程还是比较简单的。配置完后启动:
1.主节点启动Nimbus服务
nohup bin/storm nimbus >> /dev/null &
2.子节点都启动Supervisor服务
nohup bin/storm supervisor >> /dev/null &
3.主节点启动drpc服务
nohup bin/storm drpc >> /dev/null &
4.主节点启动UI服务
nohup bin/storm ui >> /dev/null &
5.访问主节点的ip即可进入web管理界面,如:http://192.168.1.42:8080
6.提交jar包到服务器运行
bin/storm jar /home/hadoop/hadoopwork.jar com.rednum.hadoopwork.storm.log.LogTopology mytopology
即bin/storm jar jar包名 包名.类名 拓扑名(随意取即可)
7.有关pom.xml文件里storm的部署
<dependency>
<groupId>org.apache.stormgroupId>
<artifactId>storm-coreartifactId>
<version>1.1.1version>
dependency>
<dependency>
<groupId>org.apache.stormgroupId>
<artifactId>storm-hbaseartifactId>
<version>1.1.1version>
dependency>
<dependency>
<groupId>org.apache.stormgroupId>
<artifactId>storm-kafkaartifactId>
<version>1.1.1version>
<type>jartype>
dependency>
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka_2.10artifactId>
<version>0.8.2.1version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeepergroupId>
<artifactId>zookeeperartifactId>
exclusion>
<exclusion>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
exclusion>
<exclusion>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
<version>0.10.2.1version>
dependency>特别注意:如果在打包到集群上运行,要把如上注释的东西解开,本地运行的话就一定要注释,否则运行时会报错。
然后开始开发,storm连接kakfa,我们使用自定义kafkaSpout获取kafka消费数据,其实就是改写我之前写的kafka消费数据的代码。我们的整体思路是:使用KafkaSpout获取数据源,多个自定义Bolt实现查找日志的ERROR分类,该日志出现的次数,日志的内容等,然后放入hbase表。部分代码如下:
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.topology.TopologyBuilder;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 日志监控程序
*/
public class LogTopology {
private static final Logger LOG = LoggerFactory.getLogger(LogTopology.class);
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
//获取数据
builder.setSpout("spout", new ReadSpout_new("test2"), 1);
//合并同一条日志
builder.setBolt("merge", new MergeBolt(), 1).shuffleGrouping("spout");
//找出日志ERROR类型
builder.setBolt("sort", new SortBolt(), 3).shuffleGrouping("merge");
//计数
builder.setBolt("printer", new CountBolt(), 1).shuffleGrouping("sort");
Config conf = new Config();
conf.setDebug(false);
if (args != null && args.length > 0) {
conf.setNumWorkers(1);
StormSubmitter.submitTopologyWithProgressBar(args[0], conf, builder.createTopology());
} else {
LocalCluster cluster = new LocalCluster();
StormTopology topology = builder.createTopology();
cluster.submitTopology("mypology", conf, topology);
Utils.sleep(40000);
cluster.killTopology("test");
cluster.shutdown();
}
}
}import com.rednum.hadoopwork.tools.CQ_SendMessege;
import java.util.Map;
import org.apache.storm.state.State;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseStatefulBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class MergeBolt extends BaseStatefulBolt {
private OutputCollector collector;
private String output;
private static final Logger LOG = LoggerFactory.getLogger(MergeBolt.class);
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
this.output = "";
}
@Override
public void execute(Tuple input) {
try {
String sentence = input.getStringByField("value");
// System.out.println("!!!!!!!!!!!sentence"+sentence);
LOG.info("!!!!!!!!!!!!!!!"+sentence);
if (sentence.matches("^\\d{1,2}(-){1}\\d{1,2}.*")) {
if (!output.equals("")) {
collector.emit(input, new Values(output));
}
output = sentence;
}else{
output= output+sentence;
}
//// System.out.println("#################");
}catch (Exception e) {
System.out.println("合并失败");
e.printStackTrace();
//消息提醒
CQ_SendMessege cqsm = new CQ_SendMessege();
cqsm.send_to("日志监控系统出错"+e.toString());
}
}
@Override
public void initState(State t) {
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("value"));
}
}import com.rednum.hadoopwork.tools.CQ_SendMessege;
import java.util.Calendar;
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
import org.apache.storm.state.State;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseStatefulBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
*
* @author Administrator
*/
public class CountBolt extends BaseStatefulBolt {
private OutputCollector collector;
private Map counters;
private Random rand;
private static final Logger LOG = LoggerFactory.getLogger(CountBolt.class);
private int count;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
this.counters = new HashMap();
this.rand = new Random();
this.count = 0;
}
@Override
public void execute(Tuple input) {
try {
Calendar c = Calendar.getInstance();
int hour = c.get(Calendar.HOUR_OF_DAY);
if (hour == 0) {
this.counters = new HashMap();
}
//引用hbase
Hbase_for_log hbase = new Hbase_for_log();
HashMap map = new HashMap();
String time_str = input.getString(1);
String content = input.getString(0);
content = content.substring(content.indexOf(time_str) + time_str.length());
if (!counters.containsKey(content)) {
time_str = time_str + "@" + rand.nextInt(1000);
map.put("start_time", time_str);
map.put("end_time", "");
map.put("Frequency", 1);
counters.put(content, map);
hbase.insert(time_str, "", 1, input.getString(0));
LOG.info("【1】" + input.getString(0));
// System.out.println("【1】 " + input.getString(0));
// CQ_SendMessege cqsm = new CQ_SendMessege();
// cqsm.send_to("tomcat错误 "+input.getString(0));
//存库操作
} else {
map = counters.get(content);
String time_start = (String) map.get("start_time");
time_start = time_start.substring(0, time_start.indexOf("@") - 1);
if (time_start.equals(time_str)) {
count++;
if (count == 5) {
CQ_SendMessege cqsm = new CQ_SendMessege();
cqsm.send_to("kafka 重复消费 请前往处理");
}
}
map.put("end_time", time_str);
int Frequence = (int) map.get("Frequency") + 1;
map.put("Frequency", Frequence);
counters.put(content, map);
hbase.insert((String) map.get("start_time"), time_str, Frequence, input.getString(0));
LOG.info("【" + Frequence + "】" + input.getString(0));
// System.out.println("【" + Frequence + "】" + input.getString(0));
// if (Frequence == 5 || Frequence == 20 || Frequence == 100) {
// CQ_SendMessege cqsm = new CQ_SendMessege();
// cqsm.send_to("错误次数 【" + Frequence + "】" + input.getString(0));
// }
}
} catch (Exception e) {
System.out.println("计数失败");
e.printStackTrace();
//消息提醒
CQ_SendMessege cqsm = new CQ_SendMessege();
cqsm.send_to("日志监控系统出错" + e.toString());
}
}
@Override
public void initState(State t) {
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("value"));
}
} 5.storm连接hbase
我们创建好hbase表log_info。附上代码:
import com.rednum.hadoopwork.tools.CQ_SendMessege;
import java.io.IOException;
import java.util.Calendar;
import java.util.HashMap;
import java.util.Random;
import java.util.logging.Level;
import java.util.logging.Logger;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
/*
* To change this license header, choose License Headers in Project Properties.
* To change this template file, choose Tools | Templates
* and open the template in the editor.
*/
/**
*
* @author Administrator
*/
public class Hbase_for_log {
private static Configuration conf;
private static final String TABLE_NAME = "log_info";
public Hbase_for_log() {
conf = HBaseConfiguration.create();
}
public static void main(String[] args) {
create_tab();
}
private static void create_tab() {
try {
Configuration conf = HBaseConfiguration.create();
String[] familys = {"values"};
HBaseAdmin admin = new HBaseAdmin(conf);
if (admin.tableExists(TABLE_NAME)) {
System.out.println("table already exists!");
} else {
HTableDescriptor tableDesc = new HTableDescriptor(TABLE_NAME);
for (int i = 0; i < familys.length; i++) {
tableDesc.addFamily(new HColumnDescriptor(familys[i]));
}
admin.createTable(tableDesc);
System.out.println("create table " + TABLE_NAME + " ok.");
}
} catch (Exception e) {
System.out.println("创建hbase表出错" + e.toString());
e.printStackTrace();
}
}
public void insert(String start_time, String end_time, int Frequency, String content) {
long timestamp = System.currentTimeMillis();
String rowkey = start_time;
try {
addRecord(TABLE_NAME, rowkey, "values", "start_time", start_time, timestamp);
addRecord(TABLE_NAME, rowkey, "values", "end_time", end_time, timestamp);
addRecord(TABLE_NAME, rowkey, "values", "Frequency", String.valueOf(Frequency), timestamp);
addRecord(TABLE_NAME, rowkey, "values", "content", content, timestamp);
} catch (Exception e) {
System.out.println("########################################存入数据库发生错误" + e.toString());
//消息提醒
CQ_SendMessege cqsm = new CQ_SendMessege();
cqsm.send_to("日志监控系统Hbase存库出错" + e.toString());
}
}
public static void addRecord(String tableName, String rowKey,
String family, String qualifier, String value, long version) {
try {
HTable table = new HTable(conf, tableName);
Put put = new Put(Bytes.toBytes(rowKey));
put.add(Bytes.toBytes(family), Bytes.toBytes(qualifier), version, Bytes.toBytes(value));
table.put(put);
} catch (IOException e) {
e.printStackTrace();
CQ_SendMessege cqsm = new CQ_SendMessege();
cqsm.send_to("日志监控系统Hbase存库出错" + e.toString());
}
}
}至此,tomcat日志监控已基本完成,如有疑问,欢迎广大同僚相互探讨!