复杂查询
select * from dept;
select d.deptno,d.dname,count(empno),avg(sal),min(sal),max(sal)
from emp e,dept d
where d.deptno=e.deptno
group by d.deptno,d.dname
having count(empno)>1;
group by 子句:
在前面的操作中,都是对表中的每一行数据进行单独的操作。
在有些情况下,需要把一个表中的行分为多个组,然后将这个作为一个整体,获得改组的一些信息,
例如获取部门编号为10的员工人数,
where:
select deptno,count(empno)
from emp
where deptno=10
group by deptno
having:
select deptno,count(empno)
from emp
having deptno=10
group by deptno
注意:having 和group by的位置交换后也是能执行出来的。
或者某个部门的员工的平均工资等,就需要使用group by子句对表中的数据进行分组。
select deptno,avg(sal)
from emp
group by deptno
having deptno=10
注意:
使用group by子句,可以根据表中的某一列或某几列对表中的数据进行分组,多个列之间使用逗号隔开。如果根据多个列进行分组,oracle会首先根据第一列进行分组,然后在分出来的组中在按照第二列进行分组。
SQL> select deptno as "部门编号",count(*) as "员工人数",job as "工作"
2 from emp
3 group by deptno,job
4 order by deptno
5 ;
部门编号 员工人数 工作
-------- ---------- ---------
10 1 CLERK
10 1 MANAGER
10 1 PRESIDENT
20 2 ANALYST
20 2 CLERK
20 1 MANAGER
30 1 CLERK
30 1 MANAGER
30 4 SALESMAN
9 rows selected
having子句:
1、having子句通常与group by 子句一起使用,在完成对分组结果的统计后,
可以使用having子句对分组的结果进行一步筛选。
2、如果在select语句中使用group by 子句,那么having子句将应用股group by子句创建的组;
如果制定了where子句,而没有指定group by子句,那么having子句将应用于where子句的输出,并且这个输出被看做是一个组;
3、如果在select语句中既没指定where子句,也没有制定group by子句,那么having子句将应用from子句的输出,并且将这个输出看做一个组。
理解having子句的最好的方法就是记住select语句中的子句的处理次序:
1、where子句只能接受from子句输出的数据;
2、havi--例7.13在前面例7、11的语句中,添加having祖居,指定调教为员工人数大于3如下:
select deptno as "部门编号",count(*) as "员工人数"
from emp
group by deptno
having count(*)>3ng子句则可以接受来自group by,where,from子句输出的数据。
提示:
如果不使用group by子句,那么having子句的功能与where子句一样,都是定义搜索条件,但是having子句的搜索条件与组有关,而不是与单个的行有关。
第二题: 列出薪金比“SMITH”或“ALLEN”多的所有员工的编号、姓名、部门名称、其领导姓名。
--第一步:找出“SMITH”或“ALLEN”的工资
select ename,sal
from emp
where ename in('SMITH','ALLEN');
select ename,sal
from emp
where ename='SMITH' or ename='ALLEN';
--第二步:以上的查询返回的多行单列的记录,按照子查询的要求在WHERE子句中写合适,
--所以这个时候将上面的查询作为一个子查询出现,继续查询符合此要求的员工的编号、姓名。
select e.empno,e.ename,sal
from emp e
where sal> any( select sal from emp where ename='SMITH' or ename='ALLEN' )
--any:大于最小值
--all大于最大值
select * from emp where sal>1600
--第三步:查询出部门的名称,引入部门表,同时增加消除笛卡尔积的条件
select e.empno,e.ename,sal,d.dname
from emp e,dept d
where sal> any( select sal from emp where ename='SMITH' or ename='ALLEN' ) and e.deptno=e.deptno
--第四步:领导的信息需要emp表自身关联
select e.empno,e.ename,e.sal,d.dname,m.ename
from emp e,dept d,emp m
where e.sal>any(select sal from emp where ename='SMITH' or ename='ALLEN') and e.deptno=e.deptno and
e.mgr=m.empno
any:处理select返回的多个值
--例8.7对scott用户的emp表进行操作,获得工资大于任意一个部门的平均工资的员工信息,如下:
--第一步:获取每一个部门的平均工资
select deptno,avg(sal)
from emp
group by deptno
--第二步:用any处理上个查询出来的多个平均值
select *
from emp
where sal>any(select avg(sal)
from emp
group by deptno)
--例8.8对scott用户的emp表进行操作,获得工资大于所用部门的平均工资的员工
select *
from emp
where sal>all(select avg(sal)
from emp
group by deptno)
--获取员工和员工老板的名字
select e.empno,e.ename||' 的老板是 '||m.ename
from emp e,emp m
where
e.mgr=m.empno
select empno
from emp
where ename='JONES'
select empno
from emp
where ename='KING'
select * from emp;
仔细观察这个表:

第三题:列出所有员工的编号、姓名及其直接上级的编号、姓名,显示的结果按领导年工资的降序排列。
select e.empno,e.ename,m.deptno,m.ename,12*(m.sal+nvl(m.comm,0))
--员工,老板
from emp e,emp m
--员工的老板的编号=老板的编号
where e.mgr=m.empno(+)
--KING这个员工没老板
order by 12*(m.sal) desc;
SELECT e.empno,e.ename,m.empno,m.ename,(m.sal+NVL(m.comm,0))*12 income
FROM emp e,emp m
WHERE e.mgr=m.empno(+)
ORDER BY income DESC;
select * from emp;
--左连接:是在检索结果中除了显示满足连接条件的行外,还显示JOIN关键字左侧表中所有满足检索条件的行。
--例8.26使用做外链接,检索emp表和salgrade表,获取员工的工资等级。
--为了观察做外链接的执行效果,首先使用insert语句向emp 表中添加一些记录,其中sal列的值需要小于700或者
--大于9999,也就是不在工资的等级范围内。
insert into emp values(7937,'Candy',null,null,null,500,null,null);
select * from emp;
--下面使用左连接
select e.empno,e.ename,e.sal,d.grade
from emp e,salgrade d
where e.sal between d.losal and d.hisal(+)
select empno,sal from emp;
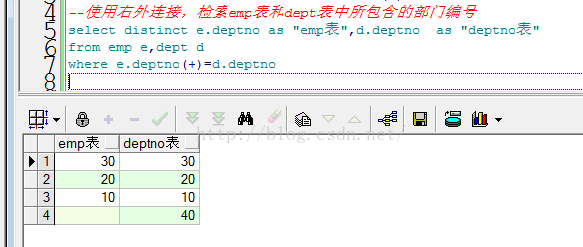
--使用右外连接,检索emp表和dept表中所包含的部门编号
select distinct e.deptno as "emp表",d.deptno as "deptno表"
from emp e,dept d
where e.deptno(+)=d.deptno
dept表:
emp表:

注意:dept表中定义全部的部门号,当一个部门有人了才记录到emp表中。
想显示全部的dept,就在缺失的表上加上+号。
--3、 列出所有员工的编号、姓名及其直接上级的编号、姓名,显示的结果按领导年工资的降序排列。
select e.empno,e.ename,m.deptno,m.ename,12*(m.sal+nvl(m.comm,0))
--员工,老板
from emp e,emp m
--员工的老板的编号=老板的编号
where e.mgr=m.empno(+)--老板
--KING这个员工没老板
order by 12*(m.sal) desc;
--想显示所有的员工,必须在缺失的一个表上加+号
--KING 的e.mgr为空 where e.mgr=m.empno(+)--老板
第四题:列出受雇日期早于其直接上级的所有员工的编号、姓名、部门名称、部门位置、部门人数。
--第一步:列出受雇日期早于其直接上级的所有员工的编号、姓名 —— 自身关联emp表。
select e.empno,e.ename,m.ename
from emp e,emp m
where e.mgr=m.empno(+) and e.hiredate
SELECT e.empno,e.ename
FROM emp e,emp m
WHERE e.mgr=m.empno(+) AND e.hiredate
--第二步:加入部门信息,继续引入部门表
SELECT e.empno,e.ename,d.dname,d.loc
FROM emp e,emp m,dept d
WHERE e.mgr=m.empno(+) AND e.hiredate
SELECT e.empno,e.ename,d.dname,d.loc,temp.count
FROM emp e,emp m,dept d,(select deptno dno,count(empno) count from emp group by deptno) temp
WHERE e.mgr=m.empno(+) AND e.hiredate
select distinct deptno,temp.count
from dept,(select deptno dno,count(empno) count from emp group by deptno) temp
where dept.deptno=temp.dno
注意:
当查询显示的时候需要统计信息,但是又不能直接使用统计函数查询的话,通过子查询在FROM子句之后进行统计。
第五题:列出部门名称和这些部门的员工信息(数量、平均工资),同时列出那些没有员工的部门。
select d.deptno,count(e.empno),avg(e.sal)
from emp e,dept d
where e.deptno(+)=d.deptno
group by d.deptno
外连接:
e.deptno是缺失的,加+号
SELECT d.deptno,d.dname,d.loc,COUNT(e.empno),AVG(e.sal)
FROM emp e,dept d
WHERE e.deptno(+)=d.deptno
GROUP BY d.deptno,d.dname,d.loc;
第六题:列出所有“CLERK”(办事员)的姓名及其部门名称,部门的人数,工资等级。
select e.ename,d.dname,temp.count,s.grade
from dept d,emp e,salgrade s,(select deptno dno,count(empno) count from emp group by deptno) temp
where d.deptno=e.deptno and e.sal between s.losal and s.hisal and e.job='CLERK' and temp.dno=d.deptno
select * from salgrade;
select *
from emp
where job='CLERK'
第七题:列出最低薪金大于1500的各种工作及从事此工作的全部雇员人数及所在部门名称、位置、平均工资。
SELECT temp.job,temp.count,d.dname,e.ename
FROM dept d,(
SELECT e.job job,COUNT(e.empno) count
FROM emp e
GROUP BY e.job
HAVING MIN(e.sal)>1500) temp,
emp e
WHERE e.deptno=d.deptno AND e.job=temp.job;
--第一步:使用emp表按照job分组,统计最低工资(HAVING)和人数
select e.job,count(e.empno),min(e.sal)
from emp e
group by e.job--统计函数是不参与分组的
having min(e.sal)>1500
--第二步:要查询出雇员所在的部门信息,但是以上的查询能跟dept表有关联吗?
--以上的查询和dept表之间并没有关联字段,那么如果没有关联字段,一定会有笛卡尔积产生,
--但是多表查询必须要消除笛卡尔积,所以必须联系;
--以上的查询可以和emp表的job字段关联;
--要引入的dept表也可以和emp表的deptno字段关联;
select e.job job ,count(e.empno) count
from emp e
group by e.job
having min(e.sal)>1500
select temp.job,temp.count,d.dname,e.ename
from dept d,(select e.job job ,count(e.empno) count
from emp e
group by e.job
having min(e.sal)>1500) temp,emp e
where e.deptno=d.deptno and temp.job=e.job
--第三步:求出一个部门的平均工资,使用emp表在子查询中统计
select temp.job,temp.count,d.dname,e.ename,res.avg
from dept d,(select e.job job ,count(e.empno) count
from emp e
group by e.job
having min(e.sal)>1500) temp,emp e,(select deptno dno,avg(sal) avg
from emp
group by deptno) res
where e.deptno=d.deptno and temp.job=e.job and res.dno=d.deptno
--8、列出在部门“SALES”(销售部)工作的员工姓名、基本工资、雇佣日期、部门名称、假定不知道销售部的部门编号。
select e.ename,e.sal,e.hiredate,d.dname
from emp e,dept d
where e.deptno=d.deptno and d.dname='SALES'
select * from emp;
第九题:列出薪金高于公司平均薪金的所有员工,所在部门,上级领导,公司的工资等级。
select e.ename,d.deptno,d.dname,m.ename,s.grade
from dept d,emp e,emp m,salgrade s
where e.mgr=m.empno(+) and e.deptno=d.deptno and e.sal between s.losal and s.hisal and e.sal>(select avg(sal)
from emp)
第十题:列出与“SCOTT”从事相同工作的所有员工及部门名称,部门人数。
--列出与“SCOTT”从事相同工作的所有员工及部门名称,部门人数。
SELECT e.empno,e.ename,e.job,d.dname,temp.count
from emp e,dept d,(select deptno dno,count(empno) count from emp e group by deptno) temp
where e.deptno=d.deptno and temp.dno=d.deptno and e.job=(select job from emp where ename='SCOTT')AND e.ename<>'SCOTT'
注意:e.ename<>'SCOTT'把本身除去
11、列出公司各个工资等级雇员的数量、平均工资。
--列出公司各个工资等级雇员的数量、平均工资。
select s.grade,count(e.empno),avg(e.sal)
from salgrade s,emp e
where e.sal between s.losal and s.hisal
group by s.grade
12、列出薪金高于在部门30工作的所有员工的薪金的员工姓名和薪金、部门名称。
select e.ename,e.empno,e.sal,d.deptno
from emp e,dept d
where e.sal>all(select sal from emp where deptno=30) and e.deptno=d.deptno
13、列出在每个部门工作的员工数量、平均工资和平均服务期限。
select d.deptno,d.dname,d.loc,count(e.empno),avg(e.sal),AVG(MONTHS_BWTWEEN(SYSDATE,e.hiredate)/12) year
from emp e,dept d
--d.deptno是完整的,e.deptno 部门有人的时候,才被写在emp
where e.deptno(+)=d.deptno
group by d.deptno,d.dname,d.loc
注意:平均服务期限AVG(MONTHS_BWTWEEN(SYSDATE,e.hiredate)/12) year
14、列出所有员工的姓名、部门名称和工资。
select e.ename,d.dname,e.sal
from dept d,emp e
where d.deptno=e.deptno
15、列出所有部门的详细信息和部门人数。
select d.deptno,d.dname,d.loc,count(e.empno)
from dept d,emp e
where d.deptno=e.deptno(+)
group by d.deptno,d.dname,d.loc
16、列出各种工作的最低工资及从事此工作的雇员姓名。
select e.ename,e.job,e.sal
from emp e,(select job,min(e.sal) min
from emp e
group by job) temp
where temp.job=e.job and e.sal=temp.min
17、列出各个部门的MANAGER(经理)的最低薪金、姓名、部门名称、部门人数。
第一步:找到所有部门的经理
select deptno,min(sal)
from emp
where job='MANAGER'
group by deptno
第二步:找到姓名,但是以上的子查询,不能再出现其他的字段
select e.ename,e.sal
from emp e,(
select deptno dno,min(sal) sal
from emp
where job='MANAGER'
group by deptno
) temp
WHERE e.deptno=temp.dno AND e.sal=temp.sal AND e.job='MANAGER';
第三步:加入部门的名称信息
select e.ename,e.sal,e.ename
from emp e,(
select deptno dno,min(sal) sal
from emp
where job='MANAGER'
group by deptno
) temp,dept d
WHERE e.deptno=temp.dno AND e.sal=temp.sal AND e.job='MANAGER' and d.deptno=e.deptno
第四步:统计部门人数
select e.ename,e.sal,e.ename,res.count
from emp e,(
select deptno dno,min(sal) sal
from emp
where job='MANAGER'
group by deptno
) temp,dept d, ( SELECT deptno dno,COUNT(empno) count FROM emp GROUP BY deptno) res
WHERE e.deptno=temp.dno AND e.sal=temp.sal AND e.job='MANAGER' and d.deptno=e.deptno and res.deptno=d.deptno
18、列出所有员工的年工资,所在部门名称,按年薪从低到高排序。
select d.dname,(e.sal+nvl(e.comm,0))*12 yearsal
from dept d,emp e
where d.deptno=e.deptno
order by yearsal desc
19、查出某个员工的上级主管及所在部门名称,并要求出这些主管中的薪水超过3000。
自己写的:
select e.empno,e.eame,d.dname,m.empno,m.ename
from emp e,dept d
where e.mgr=d.empno(+) and e.deptno and d.deptno and m.sal>3000
答案:
SELECT DISTINCT m.ename,d.dname,m.sal
FROM emp e,emp m,dept d
WHERE e.mgr=m.empno AND m.deptno=d.deptno AND m.sal>3000;
20、求出部门名称中,带‘S’字符的部门员工的工资合计、部门人数。
SELECT d.dname,SUM(e.sal),COUNT(e.empno)
FROM emp e,dept d
WHERE e.deptno(+)=d.deptno AND d.dname LIKE ‘%S%’
GROUP BY d.dname;
21、给任职日期超过30年或者在87年雇佣的雇员加薪,加薪原则:10部门增长10%,20部门增长20%,30部门增长30%,依次类推。
UPDATE emp SET
sal=(1 + deptno/100)*sal
WHERE MONTHS_BETWEEN(SYSDATE,hiredate)/12>30
OR TO_CHAR(hiredate,’yyyy’)=1987;
以上的所有题目作为DML操作的总结,这些题目结果都不重要,关键是解决问题的思路,这些只能通过代码的不断练习。
二、总结
1、 多表查询:在进行查询语句编写的时候,一定要确定所需要关联的数据表,而且只要是表的关联查询,就一定会存在笛卡尔积的问题,使用关联字段消除此问题。
在使用多表查询的时候要考虑到左右连接的问题,Oracle之外的数据库可以使用SQL:1999语法控制左右连接;
2、 所有的统计函数是用于进行数据统计操作的,而统计要在分组中进行(或者是单独使用),分组使用GROUP BY子句,是在某一列上存在重复数据的时候才会使用分组操作,而分组后的过滤使用HAVING子句完成,所有的分组函数可以嵌套,但是嵌套之后的分组函数之中不能再有其他的查询字段,包括分组字段;
3、 子查询:结合限定查询、多表查询、分组统计查询完成各个复杂查询的操作,子查询一般在WHERE和FROM之后出现较多;
4、 数据库的更新操作一定要受到事务的控制(事务的锁机制),事务的两个命令:COMMIT、ROLLBACK(解锁),每一个连接到数据库上的用户都使用一个SESSION表示;
5、 数据表的分页查询显示依靠ROWNUM伪列,以后在开发之中必定100%要使用。