学弟教程-Python-BeautifulSoup使用教程
文章目录
- 一、简介
- 1.1 创建对象
- 1.2 对象说明
- 1.3 遍历
- 二、过程
- 1. 标签选择器
- 1.1 获取元素
- 1.2 获取内容
- 1.3 获取属性
- 1.4 嵌套获取
- 1.5 访问子节点
- 2. 标准选择器
- 2.1 find
- 2.2 find_all
一、简介
1.1 创建对象
from bs4 import BeautifulSoup
# 待处理html文件
html = ...
#使用Python标准库进行解析
soup = BeautifulSoup(html, 'lxml')
1.2 对象说明
BeautifulSoup4将HTML文档转换成的树形结构,个节点都是python对象,所有对象可以归纳为:
tag获得标签及内容,默认是找到的第一个标签内容NavigableString若想获得标签里内容,可用string方法,如:soup.title.stringBeautifulSoup获取整个文档内容Comment特殊的NavigableString,输出内容不包含注释符号
1.3 遍历
- contents 获取tag的所有子节点,返回一个list
- children 获取tag的所有子节点,返回一个生成器
二、过程
示例文件index.html
<html lang="en">
<head>
<meta charset="UTF-8">
<title>爬虫示例文章title>
head>
<body>
<h1 class="title" name="dromouse">
本文专用与爬虫演示
h1>
<p class="story1">
演示部分1<br>
<a class="jump1" href="https://www.google.com.hk/" id="link1">
本超链接用于跳转至谷歌
a><br>
<a class="jump2" href="https://cn.bing.com/" id="link2">
本超链接用于跳转至必应
a>
p>
<p class="story2">演示部分2p>
<div class="panel-body">
<ul class="list" id="list_1">
<li class="element">列表1 数据1li>
<li class="element">列表1 数据2li>
<li class="element">列表1 数据2li>
ul>
<ul class="list list-small" id="list_2">
<li class="element">列表2 数据1li>
<li class="element">列表2 数据2li>
<li class="element">列表2 数据3li>
ul>
div>
body>
html>
Flask应用代码
from flask import Flask,render_template
app = Flask(__name__)
@app.route('/')
def hello_world():
return render_template('index.html')
if __name__ == '__main__':
app.run()
获取指定html
from bs4 import BeautifulSoup
import request
def get_html(url):
res = requests.get(url, 'utf-8')
return res.text
1. 标签选择器
1.1 获取元素
from bs4 import BeautifulSoup
html = get_html('http://127.0.0.1:5000')
soup = BeautifulSoup(html, 'lxml')
print(soup.title)
print(type(soup.title))
print(soup.head)
print(soup.p)
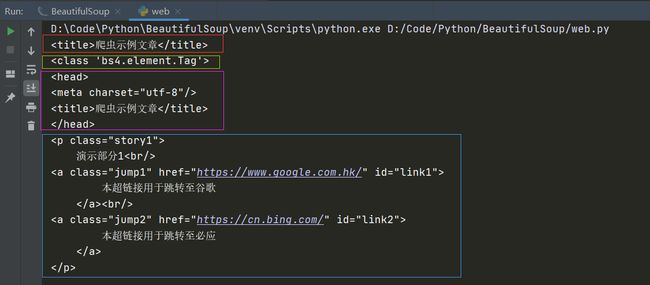
从运行结果可得:
soup.title得到index.html中
soup.head得到index.html中…标签与其中内容
soup.p得到index.html中第一个
…
标签与其中内容1.2 获取内容
from bs4 import BeautifulSoup
html = get_html('http://127.0.0.1:5000')
soup = BeautifulSoup(html, 'lxml')
print(soup.title.text)
print(soup.head.text)
print(soup.p.text)

1.3 获取属性
from bs4 import BeautifulSoup
html = get_html('http://127.0.0.1:5000')
soup = BeautifulSoup(html, 'lxml')
print(soup.h1.attrs['id'])
print(soup.h1['id'])
print(soup.h1['name'])
print(soup.p['id'])
1.4 嵌套获取
from bs4 import BeautifulSoup
html = get_html('http://127.0.0.1:5000')
soup = BeautifulSoup(html, 'lxml')
print(soup.head.title.string)
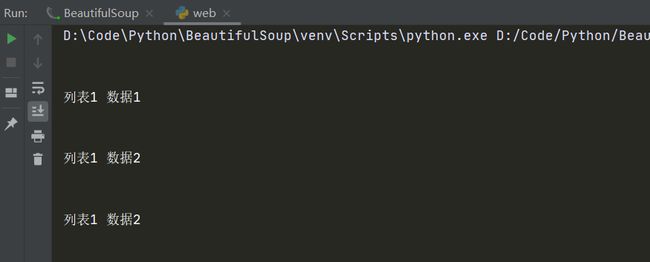
1.5 访问子节点
from bs4 import BeautifulSoup
html = get_html('http://127.0.0.1:5000')
soup = BeautifulSoup(html, 'lxml')
# 获取第一个ul标签子节点内容
for j in soup.ul.children:
print(j.string)
2. 标准选择器
2.1 find
find 返回的是一个bs4.element.Tag 对象,可进一步搜索;若有多个满足的结果,find只返回第一个;若没有则返回 None
from bs4 import BeautifulSoup
html = get_html('http://127.0.0.1:5000')
soup = BeautifulSoup(html, 'lxml')
# 获取id为s1的标签
print(soup.find(id = 's1'))
# 获取class为list的标签
print(soup.find(class_ = 'list'))
# 获取name为demo的标签
print(soup.find(name='demo'))

2.2 find_all
find_all 返回一个由 bs4.element.Tag 对象组成的list,不论找到或是没找到,均是 list
from bs4 import BeautifulSoup
html = get_html('http://127.0.0.1:5000')
soup = BeautifulSoup(html, 'lxml')
print(soup.find_all('p'))
- 例1: 获取所有标签中的超链接
from bs4 import BeautifulSoup
html = get_html('http://127.0.0.1:5000')
soup = BeautifulSoup(html, 'lxml')
for i in soup.find_all('a'):
print(i.get('href'))

