参考文章:
《Tree-Based State Tying for High Accuracy Acoustic Modelling Basics Triphone Tying Decision Trees 》, S.J. Young, J.J. Odell, P.C. Woodland 1994.
1.为什么要用三音素建模
单音素建模没有考虑协同发音效应,也就是上下文音素会对当前的中心音素发音有影响,会产生协同变化,这与该音素的单独发音会有所不同(数据统计也就有所不同),为了考虑这个影响,
所以需要使用三音素建模,使得模型描述更加精准。
2.为什么需要状态绑定
原因有两个:1)需要对三音素进行精细建模,则需要大量的数据,而实际上很难获得。
2)如果进行精细建模,则使得模型参数非常巨大。
举个例子: 假设音素表有50个音素,则需要的三音素总个数有:50×50×50=125,000
假设3个状态,每个状态对应1个GMM,1个GMM用8个高斯(44个参数=8+(8+1)×8/2),则1个三音素对应132个参数
总的模型参数有:16500000,显然模型参数非常大。
另外,每个三音素的模型建立,如果要全覆盖,则需要很大的训练数据,一般很难覆盖到。
所以,精细建模不太现实;需要状态绑定来减小参数。
两种聚类方法:
两种方法:1)传统的三音素方法就是模型绑定,也就是归一化三音素,使用一个后验平滑的方法。尽管如此,基于模型的上下文绑定是受限的,因为上下文音素不能
单独的对待。
2)当前中心音素,如果上下文的发音类型相似,则对当前音素的影响是相似的,则可以将这些数据聚为1类;具体要如何制定这些
规则(决策树规则),靠语言发音学家的经验知识,提问。(音素判别,再到状态绑定) 对于节点分裂,需要寻找最佳的问题,按照looklikehood增加的原则。
kaldi可以自动产生问题集,根据音素本身数据上的相似性,自动聚为一类,这不需要语言学知识。

3.这篇文章解决的问题
状态绑定已经可以通过数据驱动,贪婪性聚类完;这篇文章主要解决的是状态绑定是如何通过决策树完成的,它的最大优势是完成看不见
的三音素构建(所谓看不见,其实应该就是通过数据本身的分布相似特点,所构建的3音素)
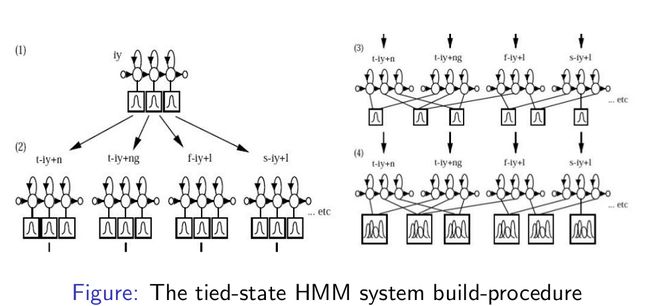
这篇文章改进的主要是第三步:
第一步,单音素标准模型用3个状态,单个状态用1个高斯描述。
第二步,三音素用BW算法训练,拷贝单音素状态输出分布到还没有绑定,覆盖,量少的三音素初始化。
第三步,中心音素相同的三音素被聚类,一个典型的状态被选择出,同类的状态绑定该状态。
第四步,混合分量增加。
第五步,留下问题:为什么使用一个高斯
第六步,Bootstrap,Baum Welch
决策树建立过程:
1. 假如所有状态已被绑定,计算训练数据产生的log似然概率。
2. 寻找问题,将节点分裂成两个子节点,以满足log似然概率最大化为准则。
3. 如果低于阈值或者最大次数,终止这个过程。
![]() ,S表示HMM的状态
,S表示HMM的状态
L(S)表示训练帧集合F的在状态S,HMM模型下似然概率

被观测![]() 的后验概率
的后验概率![]() ,
,
如果概率密度函数是高斯函数,则L(S)进一步被表示为:
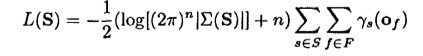
n,表示数据维度,因此整个数据集的Log似然度仅仅依赖于![]() 和
和![]()
在![]() 重估计过程中,前者可以计算得到。
重估计过程中,前者可以计算得到。
对于一个给定状态S的节点,通过寻找问题q,它被分裂成两个子节点![]()
按照装则,使得下面似然度的增量最大化:
![]()
当这个增量为小于阈值时,停止分裂。
最后,对于不同父节点下的叶子节点进行归类,如果Log似然度减少在设定的阈值以内,则合并
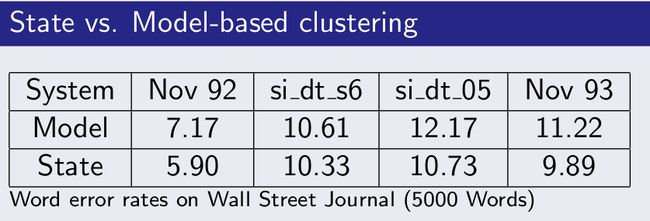
基于数据驱动,与决策树聚类对比
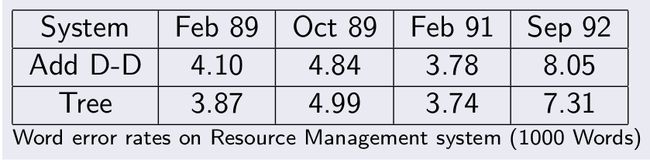
基于状态与基于模型聚类对比