Mean encodings
以下是Coursera上的How to Win a Data Science Competition: Learn from Top Kagglers课程笔记。
学习目标
- Regularize mean encodings
- Extend mean encodings
- Summarize the concept of mean encodings
Concept of mean encoding
均值编码是一种非常强大的技术,它有很多名字,例如:likelihood encoding、target encoding,但这里我们叫它均值编码。我们举一个二分类任务的例子。
| feature | feature_label | feature_mean | target | |
|---|---|---|---|---|
| 0 | Moscow | 1 | 0.4 | 0 |
| 1 | Moscow | 1 | 0.4 | 1 |
| 2 | Moscow | 1 | 0.4 | 1 |
| 3 | Moscow | 1 | 0.4 | 0 |
| 4 | Moscow | 1 | 0.4 | 0 |
| 5 | Tver | 2 | 0.8 | 1 |
| 6 | Tver | 2 | 0.8 | 1 |
| 7 | Tver | 2 | 0.8 | 1 |
| 8 | Tver | 2 | 0.8 | 0 |
| 9 | Klin | 0 | 0.0 | 0 |
| 10 | klin | 0 | 0.0 | 0 |
| 11 | Tver | 2 | 1 | 1 |
我们想对feature变量进行编码,最直接、常用的方式就是label encoding,这就是第二列数据。
平均编码以不同的方式去完成这个任务,它用每个城市自身对应的目标均值来进行编码。例如,对于Moscow,我们有五行,三个0和两个1。 所以我们用2除以5或0.4对它进行编码。用同样的方法处理其他城市。
现在了解一下细节。当我们的数据集非常大,包含数百个不同的城市,让我们试着比较一下。我们绘制了0,1 class的直方图。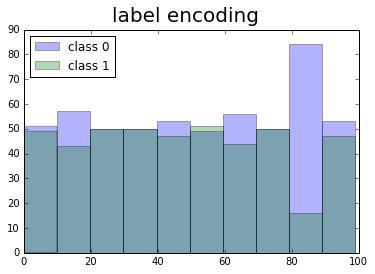
在label encoding的情况下,我们得到的图看起来没有任何逻辑顺序。
但是当我们使用mean encoding对目标进行编码时,类看起来更加可分了,像是被排序过。
一般来说,模型对复杂、非线性的特征目标越依赖,均值编码越有效。例如树模型的深度有限,可以用平均编码来补偿它,可以用它的短板来获得更好的分数。
以上只是一个例子,传递的是一种思想,实际上可以做很多类似的操作。
Ways to use target variable
Goods-number of ones in a group,
Bads-number of zeros
- \(Likelihood = \frac {Goods}{Goods+Bads} = mean(target)\)
- \(Weight of Evidence = \ln(\frac{Goods}{Bads}) * 100\)
- \(Count = Goods = sum(target)\)
- \(Diff = Goods - Bads\)
构造Mean encoding的例子
means= X_tr.groupby(col).target.mean()
train_new[col+'_mean_target'] = train_new[col].map(means)
val_new[col+'_mean_target'] = val_new[col].map(means)将它运用到模型中,出现了严重的过拟合,但是为什么呢?
- Train
| feature | feature_label | feature_mean | target | |
|---|---|---|---|---|
| 8 | Tver | 2 | 0.8 | 0 |
| 9 | Klin | 0 | 0.0 | 0 |
- Validation
| feature | feature_label | feature_mean | target | |
|---|---|---|---|---|
| 10 | klin | 0 | 0.0 | 0 |
| 11 | Tver | 2 | 1 | 1 |
When they are categorized, it's pretty common to get results like in an example, target 0 in train and target 1 in validation. Mean encodings turns into a perfect feature for such categories. That's why we immediately get very good scores on train and fail hardly on validation.
Regularization
在上一节,我们意识到平均编码不能按原样使用,需要对训练数据进行某种正规化。现在我们将实施四种不同的正则化方法。
- 1.CV loop inside training data;
- 2.Smoothing;
- 3.Adding random noise;
- 4.Sorting and calculating expanding mean.
Conclusion
- There are a lot ways to regularize mean encodings
- Unending battle with target variable leakage
- CV loop or Expanding mean for partical tasks.
1.KFold scheme
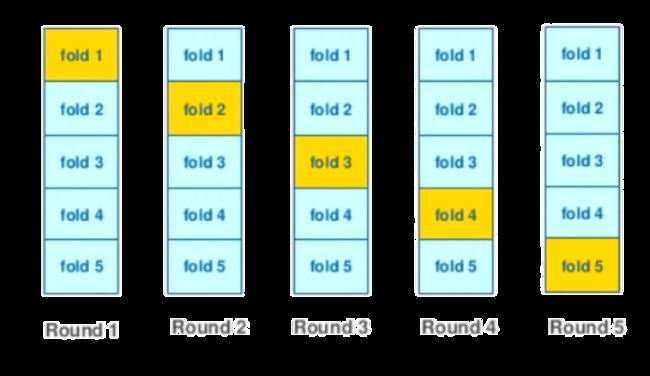
通常做四到五折的交叉验证就能得到不错的结果,无序调整此数字。
代码例子
这个方法看起来已经完全避免了目标变量的泄露,但事实并非如此。
这里我们通过留一法对Moscow进行编码
| feature | feature_mean | target | |
|---|---|---|---|
| 0 | Moscow | 0.50 | 0 |
| 1 | Moscow | 0.25 | 1 |
| 2 | Moscow | 0.25 | 1 |
| 3 | Moscow | 0.50 | 0 |
| 4 | Moscow | 0.50 | 0 |
对于第一行,我们得到0.5,因为有两个1和 其余行中有两个0。 同样,对于第二行,我们得到0.25,依此类推。 但仔细观察,所有结果和由此产生的特征。 它完美地分割数据,具有等于或等的特征的行 大于0.5的目标为0,其余行的目标为1。 我们没有明确使用目标变量,但我们的编码是有偏置的。
目标变量的泄露效果对于KFold scheme仍然是有效的,只是效果温和了点。
在实践中,如果您有足够的数据并使用四或五折,编码将通过这种正规化策略正常工作。 只是要小心并使用正确的验证。
2.Smoothing
- Alpha controls the amount of regularization
- Only works together with some other regularization method
\[\frac{mean(target)*nrows + globalmean*alpha}{nrows+alpha}\]
它具有控制正则化量的超参数alpha。 当alpha为零时,我们没有正则化,并且当alpha接近无穷大时,一切都变成了globalmean。
在某种意义上,alpha等于我们可以信任的类别大小。也可以使用其他一些公式,基本上任何惩罚编码类别的东西都可以被认为是smoothing。
3.Nosie
- Noise degrades the quality of encoding
通过添加噪声,会降低训练数据的编码质量。这种方法很不稳定,很难使它工作。主要问题在于我们需要添加的噪声量。
- How much noise should we add?
太多的噪声会把这个特征变成垃圾,虽然噪声太小意味着更正规化。你需要努力地微调它。
- Usually used together with LOO(Leave one out).
这种方法通常与LOO正则化一起使用。如果你没有很多时间,它可能不是最好选择。
4.Expanding mean
- Least amount of leakage
- No hyper parameters
- Irregular encoding quality
- Built-in in CatBoost.
代码例子
cumsum = df_tr.groupby(col)['target'].cumsum() - df_tr['target']
cumcnt = df_tr.groupby(col).cumcount()
train_new[col + '_mean_target'] = cusum/cumcntcumsum存储目标变量的累计和,直到给定行,cumcnt存储累积计数。该方法引入的目标变量的泄漏量最少,唯一的缺点是特征质量不均匀。但这不是什么大不了的事,我们可以从不同的数据排列计算编码的平均模型。
它被用于CatBoost库中,证明了它在分类数据集上表现非常出色。
Extensions and generalizations
- 如何在回归和多分类任务中进行
Mean encoding - 如何将编码应用于具有多对多关系的领域
- 我们可以根据时间序列中的目标构建哪些功能
- 编码交互和数字特征
Many-to-many relations
- 原始数据
| User_id | APPS | Target |
|---|---|---|
| 10 | APP1;APP2;APP3 | 0 |
| 11 | APP4;APP1 | 1 |
| 12 | APP2 | 1 |
| 100 | APP3;APP9 | 0 |
现在考虑一个例子,基于用在智能手机上已装的APP,预测它是否会安装,这是一个二分类任务。从表中数据可知,每个用户可能有多个应用程序,每个应用程序由多个用户使用,因此这是多对多的关系。而麻烦在于,如何从多对多的关系中提取均值。
- 长数据表示
| User_id | APP_id | Target |
|---|---|---|
| 10 | APP1 | 0 |
| 10 | APP2 | 0 |
| 10 | APP3 | 0 |
| 11 | APP4 | 1 |
| 11 | APP1 | 1 |
把原始数据转为长数据表示,如上表。使用此表,我们可以自然地计算APP的均值编码。但是如何将其映射回用户呢?
每个用户都有许多APP,但不都是“APP1,APP2,APP3”。因此我们用向量表示(0.1,0.2,0.1),我们还可以从向量中收集各种统计数据,比如均值、标准差、最大最小值等等。
Time series
- Time structure allows us to make a lot of complicated features.
- Rolling statistics of target variable.
一方面,这是一种限制,另一方面,它允许我们只做一些复杂的特征。考虑一个例子:
| Day | User | Spend | Amount | Prev_user | Prev_spend_avg |
|---|---|---|---|---|---|
| 1 | 101 | FOOD | 2.0 | 0.0 | 0.0 |
| 1 | 101 | GAS | 4.0 | 0.0 | 0.0 |
| 1 | 102 | FOOD | 3.0 | 0.0 | 0.0 |
| 2 | 101 | GAS | 4.0 | 6.0 | 4.0 |
| 2 | 101 | TV | 8.0 | 6.0 | 0.0 |
| 2 | 102 | FOOD | 2.0 | 3.0 | 2.5 |
我们需要预测用户会为哪个类别花钱。 我们有两天的时间,两个用户, 和三个支出类别。 一些好的特征是用户在前一天消费总额,所有用户在给定类别中花费的平均金额。 因此,在第1天,用户101花费6美元,用户102花费$3。 因此,我们认为这些数字是第2天的未来值。 同样,可以按类别划分平均金额。
我们拥有的数据越多,可以创造的特征就越复杂。
Interactions and numerical features
- Analyzing fitted model
- Binning numeric and selecting interactions
在实践中,通常需要编码数字特征以及进行特征组合。要对数字特征进行编码,我们只需要对其进行分区,然后将其视为分类。我们以没有进行任何编码的原始特征和决策树模型为例。
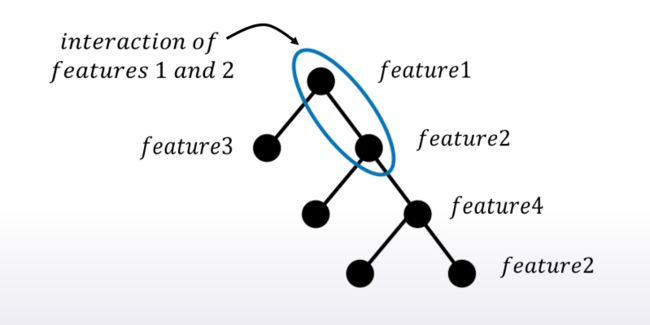
如何为数字特征分组?
如果数字特征有很多分裂点,则表示它于目标有一些复杂的依赖,并且试图去编码它。此外这些精确的分裂点可用于对特征进行分类,所以通过分析模型结构,我们既可以识别这些可疑的数字特征,又可以找到很好的方法去给它分组。如何挑选特征组合?
先看决策树中如何提取交互特征。参照上图,如果两个特征在相邻的节点中,则这两个特征在相互作用。考虑到这点,我们可以遍历模型中的所有树,计算每个特征组合出现的次数。最常见的组合可能值得进行均值编码。
例如,如果我们发现feature1和feature2这一对特征最常见,我们可以在数据中连接这些特征,这意味编码产生交互。
Correct validation reminder
- Local experiments:
- Estimate encodings on X_tr
- Map them to X_tr and X_val
- Regularize on X_tr
- Validate model on X_tr/X_val split
- Submission:
- Estimate encodings on whole Train data
- Map them on Train and Test
- Regularize on Train
- Fit on Train

End
- Main advantages:
- Compact transformation of categorical variables
- Powerful basis for feature engineering
- Disadvantages:
- Need careful validation, there a lot of ways to overfit
- Significant improvements only on specific datasets
