hive
一、伪分布式
当我们按照hadoop伪分布式集群搭建博客搭建了hadoop以后,发现这是一个空的hadoop,只有YARN,MapReduce,HDFS,而这些实际上我们一般不会直接使用,而是需要另外部署Hadoop的其他组件,来辅助使用。比如我们把数据存储到了hdfs,都是文件格式,用起来肯定不方便,用HIVE把数据从HDFS映射成表结构,直接用sql语句即可操作数据。另外针对分布式数据计算算法MapReduce,需要直接写MapReduce程序,比较复杂,此时使用Hive,就可以通过写SQL语句,来实现MapReduce的功能实现。
操作步骤
1. 安装mysql
安装mysql,配置远程登录,具体参考mysql章节
并配置可以远程登录mysql
2. 下载hive2.1并解压配置环境变量
下载hive2.1
解压到opt目录下,更换目录为hive-2.1.1
# tar zxvf apache-hive-2.1.1-bin.tar.gz
# mv apache-hive-2.1.1-bin hive-2.1.1
配制系统环境变量:
# vim /etc/profile
export HADOOP_HOME=/usr/local/hadoop-2.6.0
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib"
export HIVE_HOME=/opt/hive-2.1.1
export HIVE_CONF_DIR=${HIVE_HOME}/conf
export JAVA_HOME=/opt/jdk1.7.0_79
export PATH=.:$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$PATH
保存后,使配制生效:
# source /etc/profile
3. 修改hive-env.sh文件
修改hive-env.sh文件,在文件底部增加以下环境变量:
# cd /opt/hive-2.1.1/conf
# cp hive-env.sh.template hive-env.sh
# vim hive-env.sh
export JAVA_HOME=/usr/java/jdk1.7.0_79
export HIVE_HOME=/opt/hive-2.1.1
export HIVE_CONF_DIR=/opt/hive-2.1.1/conf
export HIVE_AUX_JARS_PATH=/opt/hive-2.1.1/lib
export HADOOP_HOME=/opt/hadoop-2.6.0
4. 修改hive-site.xml文件
4.1 修改hive-site.xml文件,并将所有的${system:java.io.tmpdir}替换为绝对路径:
# cp hive-default.xml.template hive-site.xml
# vim hive-site.xml
由于在该配置文件中有如下两个配置项注明了hive在HDFS中数据存储的目录,因此我们需要在HDFS上手动创建并赋权限,也就是需要在hdfs上创建/tmp/hive 和/user/hive/warehouse
# hadoop fs -mkdir -p /user/hive/warehouse
# hadoop fs -chmod -R 777 /user/hive/warehouse #递归赋予读写权限
# hadoop fs -mkdir -p /tmp/hive/ #创建/tmp/hive/目录
# hadoop fs -chmod -R 777 /tmp/hive #目录赋予读写权限
hive.exec.local.scratchdir
${system:java.io.tmpdir}/${system:user.name}
Local scratch space for Hive jobs
hive.downloaded.resources.dir
${system:java.io.tmpdir}/${hive.session.id}_resources
Temporary local directory for added resources in the remote file system.
hive.querylog.location
${system:java.io.tmpdir}/${system:user.name}
Location of Hive run time structured log file
hive.server2.logging.operation.log.location
${system:java.io.tmpdir}/${system:user.name}/operation_logs
Top level directory where operation logs are stored if logging functionality is enabled
替换后:
hive.exec.local.scratchdir
/opt/hive-2.1.1/tmp/
Local scratch space for Hive jobs
hive.downloaded.resources.dir
/opt/hive-2.1.1/tmp/${hive.session.id}_resources
Temporary local directory for added resources in the remote file system.
hive.querylog.location
/opt/hive-2.1.1/tmp/
Location of Hive run time structured log file
hive.server2.logging.operation.log.location
/opt/hive-2.1.1/tmp/root/operation_logs
Top level directory where operation logs are stored if logging functionality is enabled
4.2 修改hive-site.xml文件,修改文件中的元数据的连接,驱动,用户名,密码
hive-site.xml中相关元数据信息配制:
javax.jdo.option.ConnectionDriverName,将对应的value修改为MySQL驱动类路径;
javax.jdo.option.ConnectionURL,将对应的value修改为MySQL的地址;
javax.jdo.option.ConnectionUserName,将对应的value修改为MySQL数据库登录名;
javax.jdo.option.ConnectionPassword,将对应的value修改为MySQL数据库的登录密码:
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
Driver class name for a JDBC metastore
javax.jdo.option.ConnectionURL
jdbc:mysql://192.168.208.110:3306/hive?createDatabaseIfNotExist=true
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
javax.jdo.option.ConnectionUserName
root
Username to use against metastore database
javax.jdo.option.ConnectionPassword
11111
password to use against metastore database
将MySQL驱动包添加到Hive的lib目录下:mysql-connector-java-5.1.38-bin.jar
5. hive的启动及测试:
对hive元数据初始化(mysql中hive元信息初始化、建表等):
# schematool -initSchema -dbType mysql
# hive
6. 注意
注:如果要用beeline -u jdbc:hive2://ip:10000进行连接,需要修改hdfs的core-site.xml配置
hadoop.proxyuser.root.hosts
*
hadoop.proxyuser.root.groups
*
# 备注:hadoop.proxyuser.XXX.hosts 与 hadoop.proxyuser.XXX.groups 中XXX为异常信息中User:* 中的用户名部分,这里用户名都是root,所以hdfs的core-site.xml中的标签名为hadoop.proxyuser.root.hosts与hadoop.proxyuser.root.groups
二、分布式
当我们按照hadoop完全分布式集群搭建博客搭建了hadoop以后,发现这是一个空的hadoop,只有YARN,MapReduce,HDFS,而这些实际上我们一般不会直接使用,而是需要另外部署Hadoop的其他组件,来辅助使用。比如我们把数据存储到了hdfs,都是文件格式,用起来肯定不方便,用HIVE把数据从HDFS映射成表结构,直接用sql语句即可操作数据。另外针对分布式数据计算算法MapReduce,需要直接写MapReduce程序,比较复杂,此时使用Hive,就可以通过写SQL语句,来实现MapReduce的功能实现。
操作步骤
注意:首先需要注意的是让Hadoop完全分布式环境跑起来,然后只需要在namenode节点安装hive即可!
1. hive包下载
hive2.1.1下载地址
2. 解压缩配置环境变量
# cd /opt # hive包的目录放到服务器的opt目录下
# tar -xzvf apache-hive-2.1.1-bin.tar.gz # 将压缩包进行解压
# mv apache-hive-2.1.1-bin hive2.1.1 #更换hive的目录名为hive2.1.1
# vim /etc/profile # 修改环境变量配置文件
export JAVA_HOME=/opt/jdk1.8
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/opt/hadoop2.6.0
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HIVE_HOME=/opt/hive2.1.1
export HIVE_CONF_DIR=$HIVE_HOME/conf
export CLASSPATH=.:$HIVE_HOME/lib:$CLASSPATH
export PATH=$PATH:$HIVE_HOME/bin
# source /etc/profile #使配置生效
3. 修改Hive配置
3.1 生成 hive-site.xml配置文件
# cd /opt/hive2.1.1/conf/
# cp hive-default.xml.template hive-site.xml
3.2 创建HDFS目录
注意:我们需要在HDFS创建/user/hive/warehouse,/tmp/hive这两个目录,因为在修改hive-site.xml配置文件的时候需要使用该目录!
# hdfs dfs -mkdir -p /user/hive/warehouse # 创建warehouse目录
# hdfs dfs -chmod 777 /user/hive/warehouse # 给warehouse目录进行赋权
# hdfs dfs -mkdir -p /tmp/hive/ # 创建warehouse目录
# hdfs dfs -chmod 777 /tmp/hive # 给warehouse目录进行赋权
3.3 修改hive-site.xml文件中的临时目录
将${system:java.io.tmpdir}全部替换为/opt/hive2.1.1/tmp/【该目录需要自己手动建】,将${system:user.name}都替换为root
hive.exec.local.scratchdir
${system:java.io.tmpdir}/${system:user.name}
Local scratch space for Hive jobs
hive.downloaded.resources.dir
${system:java.io.tmpdir}/${hive.session.id}_resources
Temporary local directory for added resources in the remote file system.
hive.querylog.location
${system:java.io.tmpdir}/${system:user.name}
Location of Hive run time structured log file
hive.server2.logging.operation.log.location
${system:java.io.tmpdir}/${system:user.name}/operation_logs
Top level directory where operation logs are stored if logging functionality is enabled
替换后
hive.exec.local.scratchdir
/opt/hive2.1.1/tmp/root
Local scratch space for Hive jobs
hive.downloaded.resources.dir
/opt/hive2.1.1/tmp/${hive.session.id}_resources
Temporary local directory for added resources in the remote file system.
hive.querylog.location
/opt/hive2.1.1/tmp/root
Location of Hive run time structured log file
hive.server2.logging.operation.log.location
/opt/hive2.1.1/tmp/root/operation_logs
Top level directory where operation logs are stored if logging functionality is enabled
3.4 修改hive-site.xml文件,修改文件中的元数据的连接,驱动,用户名,密码
hive-site.xml中相关元数据信息配制:
javax.jdo.option.ConnectionDriverName,将对应的value修改为MySQL驱动类路径;
javax.jdo.option.ConnectionURL,将对应的value修改为MySQL的地址;
javax.jdo.option.ConnectionUserName,将对应的value修改为MySQL数据库登录名;
javax.jdo.option.ConnectionPassword,将对应的value修改为MySQL数据库的登录密码:
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
Driver class name for a JDBC metastore
javax.jdo.option.ConnectionURL
jdbc:mysql://192.168.210.70:3306/hive?createDatabaseIfNotExist=true
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
javax.jdo.option.ConnectionUserName
root
Username to use against metastore database
javax.jdo.option.ConnectionPassword
11111
password to use against metastore database
hive.metastore.schema.verification
false
Enforce metastore schema version consistency. True: Verify that version information stored in metastore matches with one from Hive jars. Also disable automatic schema migration attempt. Users are required to manully migrate schema after Hive upgrade which ensures proper metastore schema migration. (Default) False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.
3.5 下载mysql驱动,并上传到hive中
mysql驱动下载地址
下载后,上传到/opt/hive2.1.1/lib目录下
3.6 修改hive-env.sh文件
# cd /opt/hive2.1.1/conf
# cp hive-env.sh.template hive-env.sh
打开hive-env.sh配置并且添加以下内容:
export HADOOP_HOME=/opt/hadoop2.6.0
export HIVE_CONF_DIR=/opt/hive2.1.1/conf
export HIVE_AUX_JARS_PATH=/opt/hive2.1.1/lib
4. 启动hive
# cd /opt/hive2.1.1/bin
# schematool -initSchema -dbType mysql # 对数据库进行初始化
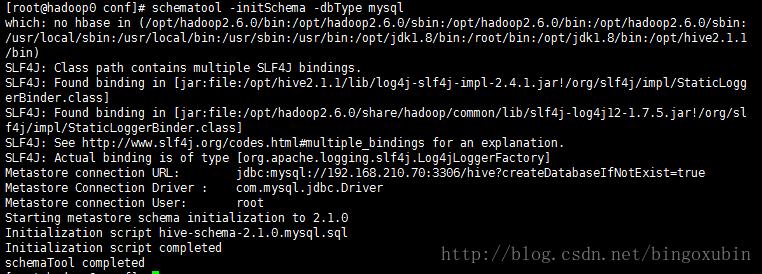
三、beeline
当在伪分布式hadoop2.6.0集群中,部署添加了hive2.1.1后,发现输入hive命令,可以进行连接hive,但是用beeline连接连不上。如果用beeline连不上,那就不能通过jdbc来操作hive数据仓库了,这样就影响使用,比较麻烦,下面提供解决办法!
操作步骤
如果要用beeline -u jdbc:hive2://ip:10000进行连接hive,需要修改hdfs的core-site.xml配置
hadoop.proxyuser.root.hosts
*
hadoop.proxyuser.root.groups
*
*备注:hadoop.proxyuser.XXX.hosts 与 hadoop.proxyuser.XXX.groups 中XXX为异常信息中User:中的用户名部分,这里用户名都是root,所以hdfs的core-site.xml中的标签名为hadoop.proxyuser.root.hosts与hadoop.proxyuser.root.groups
beeline 的连接和关闭
Hive安装后的初始化
#cd /opt/hive2.1.1/bin
#schematool -initSchema -dbType mysql # 对数据库进行初始化
此时hive命令即可使用,但是如果想要通过beeline进行连接。
使用beeline连接
Error: Could not open client transport with JDBC Uri: jdbc:hive2://192.168.159.131:10000: java.net.ConnectException: Connection refused (state=08S01,code=0)
这个是因为hive中的hiveServer2没有启动起来,启动的命令是: hive --service hiveserver2
需要启动hiveserver2服务
nohup hive --service hiveserver2 &
ps -aux| grep hiveserver2
beeline -u jdbc:hive2://192.168.186.55:10000/default
四、hql
当在伪分布式集群上,搭建部署了hive以后,发现hive无法执行带where语句的sql,那hive将无法使用,下面介绍解决该问题的方案!
操作步骤
hive连接执行sql,可以执行带where语句的sql,但是采用beeline连接,无法执行带where的sql语句,报could not initialize calss org.apache.hadoop.hive.ql.optimizer.calcite.translator.SqlFunctionConverter
解决方案:
在/etc/profile中加入配置:
export HIVE_AUX_JARS_PATH=/opt/hive-2.1.1/lib
五、内存溢出
搭建了hadoop伪分布式集群,并且在其上搭建了hive环境,但是在执行HQL语句的时候,老是报内存溢出,很麻烦,只需要简单设置,就可以解决该问题。
操作方案
运行程序过程中,报内存溢出:java.sql.SQLException: Error running query: java.lang.OutOfMemoryError: PermGen space
解决方案:
在/opt/hive-2.1.1/conf/hive-env.sh
export HADOOP_HEAPSIZE=102400
六、元数据
搭建了hadoop伪分布式集群,并且在其上搭建了hive环境,hive运行报HiveMetaStoreClient错误。
解决办法
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.metastore.HiveMetaStoreClient
修改hive-site.xml,将value修改为false即可!
hive.metastore.schema.verification
false
Enforce metastore schema version consistency. True: Verify that version information stored in metastore matches with one from Hive jars. Also disable automatic schema migration attempt. Users are required to manully migrate schema after Hive upgrade which ensures proper metastore schema migration. (Default) False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.
七、demo
代码实例
package oa.epoint.com.hive;
import java.io.UnsupportedEncodingException;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class HiveTest {
private static String driveName = "org.apache.hive.jdbc.HiveDriver";
private static String url = "jdbc:hive2://100.2.5.2:10000/default";
// private static String url = "jdbc:hive2://192.168.1.131:10000/test";
private static String user = "hdfs";
private static String passwd = "d010";
private static String sql = "";
private static String sql1 = "";
private static ResultSet res;
public static void main(String[] args) {
Connection con = null;
Statement stm = null;
try {
con = getConnection();
stm = con.createStatement();
String tableName = "stu2";
dropTable(stm, tableName);
createTable(stm, tableName);
selectData(stm, tableName);
} catch (ClassNotFoundException e) {
e.printStackTrace();
System.out.println(driveName + " not found! ");
System.out.println(e.getMessage());
} catch (SQLException e1) {
e1.printStackTrace();
System.out.println("connection error! ");
System.out.println(e1.getMessage());
} finally {
try {
if (res != null) {
res.close();
res = null;
}
if (stm != null) {
stm.close();
stm = null;
}
if (con != null) {
con.close();
con = null;
}
} catch (SQLException e2) {
e2.printStackTrace();
System.out.println("close connection or statement error! ");
System.out.println(e2.getMessage());
}
}
}
private static Connection getConnection() throws ClassNotFoundException, SQLException {
Class.forName(driveName);
Connection con = DriverManager.getConnection(url, user, passwd);
System.out.println("connection success!");
return con;
}
private static void dropTable(Statement stm, String tableName) throws SQLException {
sql = "drop table if exists " + tableName;
System.out.println("Running:" + sql);
stm.executeUpdate(sql);
}
private static void createTable(Statement stm, String tableName) throws SQLException {
sql = "create table if not exists " + tableName + " (stuid string, name string, sex string, age int) clustered by (stuid) into 2 buckets STORED AS ORC";
System.out.println("Running:" + sql);
stm.executeUpdate(sql);
sql1 = "insert into "+tableName+"(stuid,name,sex,age) values ('1001','xubin1','man',25),('1002','xubin2','man',26),('1003','xubin3','man',27),('1004','xubin4','man',28)";
stm.executeUpdate(sql1);
String id,name,gender,num;
try {
id = new String("1001".getBytes(),"iso8859-1");
name = new String("徐彬1".getBytes(),"iso8859-1");
gender = new String("男".getBytes(),"iso8859-1");
num = "25";
sql1 = "insert into stu1 values('$ID','$NAME','$GENDER',$NUM)";
stm.execute(sql1.replace("$ID", id).replace("$NAME", name).replace("$GENDER", gender).replace("$NUM", num));
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
private static void selectData(Statement stm, String tableName) throws SQLException {
sql = "select * from " + tableName;
System.out.println("Running:" + sql);
res = stm.executeQuery(sql);
while (res.next()) {
String uid = res.getString(1);
String ufname = res.getString(2);
String ulname = res.getString(3);
String udate = res.getString(4);
System.out.println(uid + "\t" + ufname + "\t" + ulname + "\t" + udate );
}
}
}
beeline -u jdbc:hive2://ip:10000/default -n user -p passwd
beeline
!connect jdbc:hive2://ip:10010/default