代码下载地址:https://github.com/tazhigang/big-data-github.git
一、需求:求出每一个订单中最贵的商品
二、数据准备
- 数据准备
Order_0000001 Pdt_01 222.8
Order_0000002 Pdt_05 722.4
Order_0000001 Pdt_05 25.8
Order_0000003 Pdt_01 222.8
Order_0000003 Pdt_01 33.8
Order_0000002 Pdt_03 522.8
Order_0000002 Pdt_04 122.4
- 按照订单号将该文件分成若干小文件
- 最终显示
==============================part-r-0000==========================
Order_0000001 Pdt_01 222.8
==============================part-r-0001==========================
Order_0000002 Pdt_05 722.4
==============================part-r-0002==========================
Order_0000003 Pdt_01 222.8
三、创建maven项目
- 项目结构

- 代码
- OrderSortGroupingComparator.java
package com.ittzg.hadoop.orderv2;
import com.ittzg.hadoop.order.OrderBean;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
/**
* @email: [email protected]
* @author: ittzg
* @date: 2019/7/6 17:18
*/
public class OrderSortGroupingComparator extends WritableComparator {
protected OrderSortGroupingComparator() {
super(OrderBean.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
OrderBean orderA = (OrderBean) a;
OrderBean orderB = (OrderBean) b;
return orderA.getOrderId().compareTo(orderB.getOrderId());
}
}
- OrderDriveV2.java
package com.ittzg.hadoop.orderv2;
import com.ittzg.hadoop.order.OrderBean;
import com.ittzg.hadoop.order.OrderPatitioner;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.net.URI;
/**
* @email: [email protected]
* @author: ittzg
* @date: 2019/7/6 16:31
*/
public class OrderDriveV2 {
public static class OrderMapper extends Mapper{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
System.out.println(line);
String[] split = line.split("\t");
OrderBean orderBean = new OrderBean(split[0], split[1], Double.parseDouble(split[2]));
context.write(orderBean,NullWritable.get());
}
}
public static class OrderReduce extends Reducer {
@Override
protected void reduce(OrderBean key, Iterable values, Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
public static void main(String[] args) throws Exception{
// 设置输入输出路径
String input = "hdfs://hadoop-ip-101:9000/user/hadoop/order/input";
String output = "hdfs://hadoop-ip-101:9000/user/hadoop/order/v2output";
Configuration conf = new Configuration();
conf.set("mapreduce.app-submission.cross-platform","true");
Job job = Job.getInstance(conf);
//
job.setJar("F:\\big-data-github\\hadoop-parent\\hadoop-order\\target\\hadoop-order-1.0-SNAPSHOT.jar");
job.setMapperClass(OrderMapper.class);
job.setReducerClass(OrderReduce.class);
job.setMapOutputKeyClass(OrderBean.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class);
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop-ip-101:9000"),conf,"hadoop");
Path outPath = new Path(output);
if(fs.exists(outPath)){
fs.delete(outPath,true);
}
// 设置分区
job.setPartitionerClass(OrderPatitioner.class);
// 设置reduceTask个数
job.setNumReduceTasks(3);
// 设置分组
job.setGroupingComparatorClass(OrderSortGroupingComparator.class);
FileInputFormat.addInputPath(job,new Path(input));
FileOutputFormat.setOutputPath(job,outPath);
boolean bool = job.waitForCompletion(true);
System.exit(bool?0:1);
}
}
四、运行结果
- 网页浏览
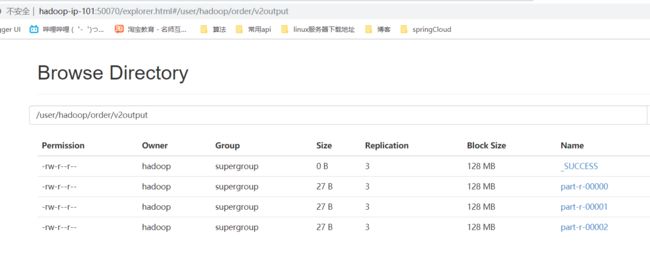
- 文件内容下载浏览


