用户画像简介
参考文章:推荐系统——用户画像
1. 用户画像
1.1 用户画像定义
用户画像的含义用户画像(persona)的概念最早由交互设计之父Alan Cooper提出:"Personas are a concrete representation of target users." 是指真实用户的虚拟代表,是建立在一系列属性数据之上的目标用户模型。随着互联网的发展,现在我们说的用户画像又包含了新的内涵 ——通常用户画像是根据用户人口学特征、网络浏览内容、网络社交活动和消费行为等信息而抽象出的一个标签化的用户模型。 构建用户画像的核心工作,主要是 利用存储在服务器上的海量日志和数据库里的大量数据进行分析和挖掘 ,给用户贴"标签",而"标签"是能表示用户某一维度特征的标识。
用户画像:也叫用户信息标签化、客户标签;根据用户社会属性、生活习惯和消费行为等信息而抽象出的一个标签化的用户模型。从电商的角度看,根据你在电商网站上所填的信息和你的行为,可以用一些标签把你描绘出来,描述你的标签就是用户画像。构建用户画像的核心工作即是给用户贴“标签”,而标签是通过对用户信息分析而来的高度精炼的特征标识。
用户画像不是推荐系统的目的,而是在构建推荐系统的过程中产生的一个关键环节的副产品,包括但不仅限于用户的注册资料、标签,各种深度学习得到的 embedding 向量。
标签体系是用户画像的基础,本质上用户画像是一系列与用户相关的标签的结构化表示
用户画像是对现实世界中用户的数学建模,主要包括两方面:
- 描述用户,即用户在业务信息维度中的信息投射
- 通过分析挖掘用户尽可能多的数据信息,对用户信息数据进行抽象,提炼,转化。
用户画像关键元素:维度、量化
按照对用户向量化的手段来分,用户画像构建方法分成三类:
- 第一类就是原始数据。直接使用原始数据作为用户画像的内容,如注册资料,行为轨迹等信息,除了数据清洗等工作,数据本身并没有做任何抽象和归纳。这种方法实现简单,但通常对于用户冷启动等场景非常有用。
- 第二类就是统计分析。方法就是通过大量数据进行统计分析,这是最常见的用户画像数据,常见的兴趣标签,就是这一类。
- 第三类就是机器学习。通过机器学习,可以得出人类无法直观理解的稠密向量。比如使用矩阵分解得到的隐因子,或使用深度学习模型学习用户的Embedding向量。这一类用户画像数据通常是不可解释的。
1.2 用户画像数据信息来源
1. 从用户出发:
- 注册资料中的文本,如姓名、个人签名。
- 用户自己生产的内容,如发表的评论、动态、日记等。
- 与用户发生了连接关系的文本,如阅读过的内容。
2. 从物品出发:
- 物品的标题、描述。
- 物品本身的内容(一般指新闻资讯类)。
- 物品基本属性中的文本。
3. 基于物品和用户的文本信息构建基本的用户画像:
- 把所有非结构化的文本结构化,去粗取精,保留关键信息,构建高质量的标签库。
- 根据用户注册数据、行为数据、产生内容,把标签传递给用户。
- 定期更新。
1.3 构建标签库
1.3.1 标签库的评价标准:
- 标签覆盖面:所有的标签在覆盖物品或用户时,能覆盖越多物品越好,覆盖越多用户越好,如果全部标签不能覆盖全部物品或全部用户,那么就会有流量浪费。
- 标签覆盖健康度:量化标签平均覆盖物品的程度,单个标签的物品覆盖数量显然符合齐普夫定律,热门标签严重倾斜,这样倾斜的分布熵较小,所以好的标签库,其标签覆盖分布熵要高,熵越高覆盖越均匀。
- 标签经济性: 标签之间的语义相似性要越小越好,因为一个标签占据用户兴趣向量中一个维度,如果两个标签并没提供两个不同的语义,却又占据了两个位置,那么这样的标签库显然性价比很低。
为了满足三个维度,实现的方法有:
- 覆盖面广。除了挖掘文本标签,还可以挖掘视频、音频、图像等标签, 让用户填更多的注册资料,等等,甚至跨公司打通数据也是常有的事。
- 分布健康。建立分类体系,对比较大型的分类,不断细分,这样来人为使分布更加健康,对应的是文本分类技术。
- 语义独立。嵌入学习、隐语义模型、主题模型等方法都是挖掘了数学上互相独立的语义来刻画物品和用户。
好的标签库应该是一个超维空间下的立方体:构建出一个完整的空间,标签之间互相独立。
构建标签库分为两派:中心化和去中心化。
- 中心化构建标签库时专业人员参与较多,也叫专业分类法。比如内容编辑,通常这样的标签库表现为一个分类树,常见于门户网站、电商网站,一个典型电商网站的商品类目分类,常常要几百人团队专门维护。
- 去中心化标签库,则是依赖“集体智慧”,完全依靠用户自行贡献标签,没有人去纠正、指导,与专业分类法相对,这种UGC(用户生成内容)的构建标签的方法叫做大众分类法,如豆瓣上的书影音标签,点评网站标签,这类标签并没有专门团队去纠正指导,所以是去中心化的,还有一种标签,是大多数用户标签的主要构成部分,是来源于挖掘的标签,从非结构化的文本中抽取出标签,构建了标签库,这也不是专业人员产生的,所以也属于去中心化标签这一派。
两类标签对比如下:
| 对比维度 | 中心化 | 去中心化 |
|---|---|---|
| 标签覆盖面 | 小 | 大 |
| 标签覆盖健康度 | 好(均匀) | 不好(倾斜) |
| 标签经济性 | 好(相对独立) | 不好(同义近义多) |
因此,构建一个高质量的标签库,显然不能只依赖其中一种,而应该两者结合使用:
- 从不同的角度构建专业分类体系,而不能只有一个孤立的分类体系。
- 去中心化的标签需要归一化,同义标签保留最常用的,提高标签的经济性。
- 去中心的标签也需要专业人员把控质量
1.4 关于标签挖掘
分析文本,需要将非结构化的文本数据结构化,利用相关的NLP算法分析得到有用信息,从物品端来看主要分为:
- 关键词提取:最基础的标签来源,也为其他文本分析提供基础数据,常用TF-IDF和TextRank。
- 实体识别:人物、位置、著作、影视剧、历史事件和热点事件等,常用基于词典的方法结合 CRF 模型。
- 内容分类:将文本按照分类体系分类,用分类来表达较粗粒度的结构化信息。
- 文本聚类:在无人制定分类体系的前提下,无监督地将文本划分成多个类簇也很常见,虽然不是标签,类簇编号也是用户画像的常见构成。
- 主题模型:从大量已有文本中学习主题向量,然后再预测新的文本在各个主题上的概率分布情况。主题模型也很实用,其实也是一种聚类思想,主题向量也不是标签形式,是用户画像的常用构成。
- 嵌入:也叫作Embedding,从词到篇章,无不可以学习其嵌入表达。嵌入表达是为了挖掘出字面意思之下的语义信息,并且用有限的维度表达出来。
关键词提取
常用的方法有TF-IDF和TextRank,两种方法各有所长,但有一个共同点就是无需标注数据,属于无监督的方式。
TF-IDF
TF全称为词频,IDF为逆文档频率。TF-IDF方法的思维很朴素:在一篇文字中反复出现的词更重要,在所有文本中都出现的词更不重要。这两点分别量化成TF和IDF两个指标:
- • TF,文本中出现的次数,由于在短文本中,词频通常都是 1,因此 TF 在长文本中更加有用。
- • IDF,是提前统计好的,在已有的所有文本中,统计每一个词出现在了多少文本中(记为 n),也就是文档频率,以及一共有多少文本(记为 N)。
IDF计算公式:
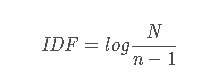
IDF 的计算公式有以下几个特点:
- 所有词的 N 都是一样的,因此出现文本数(n)越少的词,它的IDF值越大。
- 如果一个词的文档频率为0,为防止计算出无穷大的IDF,所以分母中有一个1。
- 对于新词,n应该是0,但也可以默认赋值为所有词的平均文档频率。
IDF 值的本质和信息熵有关,如果一个词在所有文档中都出现,那么这个词出现在文档中的概率很大,但它在一个文档中带来的信息量很小,反之则信息量很大。这也是 TF-IDF 这样一个简单公式的强大之处。
计算出TF和IDF值之后,再提取关键词有以下几种办法:
- 保留TopN个权重最高的标签。
- 设定阈值,保留阈值之上的标签。
- 计算权重均值,保留均值之上的标签。
另外,在某些场景下,还会增加一些其他的过滤措施,如只提取动词和名词作为关键词。
这种方法,只有一个前提条件就是提前计算词典的IDF值,尤其是对于短文本,TF不生效,几乎就是依赖IDF值排序。
TextRank
TextRank算法的思想与PageRank类似,可以概括为:
- 文本中,设定一个窗口宽度,比如 K 个词,统计窗口内的词和词的共现关系,将其看成无向图。
- 所有词初始化的重要性都是 1。
- 每个节点把自己的权重平均分配给和自己有连接的其他节点。
- 每个节点将所有其他节点分给自己的权重求和,作为自己的新权重。
- 如此反复迭代第 3 步、第 4 步,直到所有的节点权重收敛为止。
通过TextRank计算后的词语权重,呈现这个特点:那些有共现关系的会互相支持对方成为关键词。
嵌入向量
常规的抽取标签方法,得到的都是稀疏的,而且为了达到覆盖更广,往往要引入大量的同义或者近义标签。词嵌入可以配合解决这个问题。嵌入是一个数学概念。叫作Embedding。词嵌入能够为每一个词学习得到一个低维度的稠密向量,有了这个向量,可以计算词之间的距离,从而实现标签的归一化,提高标签库的经济性,或者用于文本分类和聚类,得到更抽象的标签。直接根据用户行为学习到的嵌入向量,本身就可以直接作为用户画像的一部分。
一个词可能包含很多语义信息,比如北京,可能包含首都、中国、北方、直辖市、一线城市,等等语义,这些语义单元可以认为在全量语料中是有限的,比如 128个,于是这个词就用一个 128维的向量表达,向量中各个维度值的大小代表了词包含各个语义的量。
获得嵌入向量的方法很多,如 Word2vec、 GloVec 和 FastText。其中最著名的为Word2vec。 Word2vec是用浅层神经网络学习得到每个词的向量表达,Word2vec最大的贡献在于一些工程技巧上的优化,使得百万词在单机上可以在几分钟之内轻松跑出来。
在得到词嵌入向量之后,就可以对原有标签库做扩展或者归一化:相同语义的标签只保留标准的那个,从而提高标签库的经济性。
文本分类
在门户网站时代,每个门户网站都有自己的频道体系。这个频道体系就是一个非常大的内容分类体系,这一做法也延伸到了移动互联网UGC时代。图文信息流App的资讯内容需要被自动分类到不同的频道中,从而能够得到最粗粒度的结构化信息,这也被很多推荐系统用来在用户冷启动时探索用户兴趣。
在门户时代的内容分类,相对来说更容易,因为那时候的内容都是长文本,长文本的内容分类可以提取很多信息,而如今UGC当道的时代,短文本的内容分类更困难一些。短文本分类方面经典的算法是SVM,现在最常用的工具是Facebook开源的FastText。FastText是一个工具,做两件事,一件事是学习词语的 Embedding 向量,另一件事做文本分类,尤其是句子分类。
实体识别
命名实体,是一类非常有价值的标签,这些是描述客观实体的,从非结构化文本中识别出来有助于构建高质量标签库。命名实体识别,也常常被简称为NER,在NLP技术中也是非常成熟的技术方向,NER问题通常被认为是一种序列标注问题,和分词、词性标注属于同一类问题。
所谓序列标注问题,即给定一个字符序列,从左往右遍历每个字符,一边遍历一边对每一个字符分类,分类的体系因序列标注问题不同而不同:
- 分词问题:对每一个字符分类为词开始、词中间、词结束三类之一。
- 词性标注:对每一个分好的词,分类为定义的词性集合之一。
- 实体识别:对每一个分好的词,识别为定义的命名实体集合之一。
对于序列标注问题,经典的算法是HMM(隐马尔可夫模型 )或者CRF(条件随机场),或者如今深度学习的序列模型也已成熟, BiLSTM 结合 CRF 已经有非常好的效果。实体识别还有比较实用化的非模型做法:词典法。提前准备好各种实体的词典,使用 trie-tree 数据结构存储,拿着分好的词去词典里找,找到了某个词就认为是提前定义好的实体了。
识别文本中的命名实体大致步骤如下:
- 首先,你需要标注数据。
- 然后,定义特征模板,如果采用深度神经网络如 BiLSTM 则可以从文本中自动学习出上下文特征。
- 训练 CRF 模型参数。
- 从文本中识别出命名实体。
文本聚类
文本聚类不需要任何人工知识加入,就可以把文本聚合成少数几堆,每一堆都有其相似语义。
- 首先,对全量文本聚类,得到每一个类的中心;
- 将新来文本向距离最近的类中心靠拢,归入某个聚类;
- 给每一个类赋予一个独一无二的 ID,也可以从该类中找出最能代表该类的主题词来作为类别标签。
文本聚类和分类一样,对标签库的贡献相当。相对于直接挖掘的标签来说,类之间更加独立,符合标签经济性原则。关于聚类方法选择,传统数据挖掘中基于距离的聚类方法,如Kmeans,计算复杂度较大,效果不甚理想。现在更多选择主题模型,作为文本聚类方法。以 LDA 为代表的主题模型能够更准确地抓住主题,并且能够得到软聚类的效果,也就是说可以让一条文本属于多个类簇。
标签选择
做完用户文本、物品文本的结构化,得到诸如标签(关键词、分类等)、主题、词嵌入向量。接下来需要把物品的结构化信息关联到用户。一种简单粗暴的办法是直接把用户产生过行为的物品标签累积在一起。另一种是把用户对物品的行为,如消费或者没有消费看成是一个分类问题。用户用实际行动标注了若干数据,把挑选出他实际感兴趣的特性当成特征选择问题。
最常用的是两个方法:卡方检验(CHI)和信息增益(IG)。基本思想是:
- 把物品的结构化内容看成文档。
- 把用户对物品的行为看成是类别。
- 每个用户看见过的物品就是一个文本集合。
- 在这个文本集合上使用特征选择算法选出每个用户关心的东西
卡方检验和信息增益不同之处在于:前者是针对每一个分类单独筛选一套标签出来,后者是则是全局统一筛选。
用户画像冷启动
有一种算法可以辅助做到,就是 bandit 算法。bandit 算法并不是指一个算法,而是一类算法。
举两个常用的bandit 算法:汤普森采样算法和UCB 算法
这个冷启动做法,关键点有三个:
- 用于冷启动选择的标签集合有限、互相独立、覆盖内容广;
- 标签索引的内容库要单独准备,保证高质量;
- 为每一个用户都保存 bandit 算法参数,互相不共享。
用户画像的迭代
有了用户画像之后,并不是一成不变,而是需要不断迭代。用户画像的迭代,其实是要平衡经典的“探索”“利用”这一对矛盾。探索与利用,行话又叫做 EE 问题(Exploit和Explore)。假设已经知道了用户的喜好,接下来会大部分给他推荐感兴趣的,小部分去试探新的兴趣。
用户画像需要迭代,目的有两个:
- 更加精细化刻画用户的兴趣,也是一个探索问题;
- 防止陷入用户短期兴趣不能自拔,还是一个探索问题。
所以,迭代就是为了探索更加精细的偏好特征,和之前不曾表现出的偏好特征。探索和利用问题也可以采用前面讲到的bandit算法。除此之外,在已知用户标签的前提下,如何使用标签召回?一种通常的做法是:每一次并不使用全部标签召回,而是按照标签权重加权采样部分标签,用于召回。
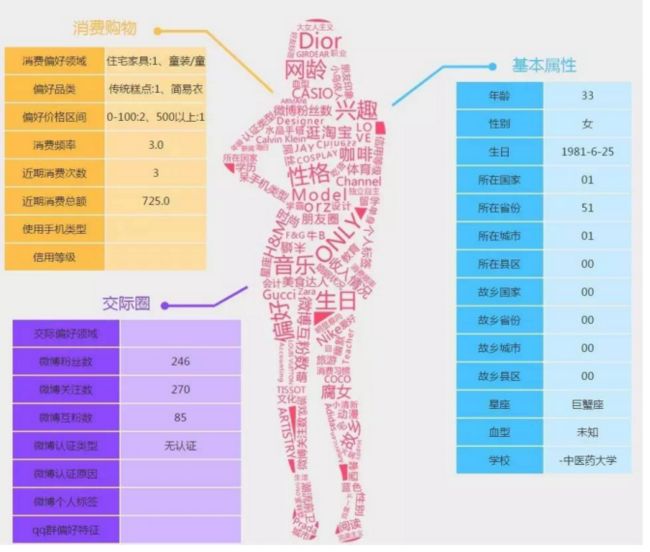
2. 用户画像示例

3. 构建电商用户画像的重大意义
罗振宇在《时间的朋友》跨年演讲举了这样一个例子:当一个坏商家掌握了你的购买数据,他就可以根据你平时购买商品的偏好来决定是给你发正品还是假货以此来提高利润,且不说是否存在这种情况,但这也说明了利用用户画像可以做到“精准营销”,当然这是极其错误的用法。
其作用大体不离以下几个方面:
- 精准营销,分析产品潜在用户,针对特定群体利用短信邮件等方式进行营销;
- 用户统计,比如中国大学购买书籍人数 TOP10;
- 数据挖掘,构建智能推荐系统,利用关联规则计算,喜欢红酒的人通常喜欢什么运动品牌,利用聚类算法分析,喜欢红酒的人年龄段分布情况;
- 进行效果评估,完善产品运营,提升服务质量,其实这也就相当于市场调研、用户调研,迅速下定位服务群体,提供高水平的服务;
- 对服务或产品进行私人定制,即个性化的服务某类群体甚至每一位用户(个人认为这是目前的发展趋势,未来的消费主流)。比如,某公司想推出一款面向5-10岁儿童的玩具,通过用户画像进行分析,发现形象=“喜羊羊”、价格区间=“中等”的偏好比重最大,那么就给新产品提供了非常客观有效的决策依据。
- 业务经营分析以及竞争分析,影响企业发展战略
4. 如何构建电商用户画像
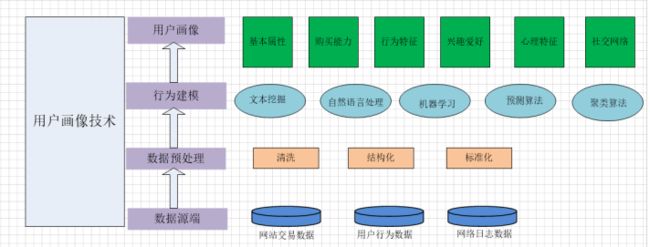
4.1 构建电商用户画像技术和流程
4.2 源数据分析
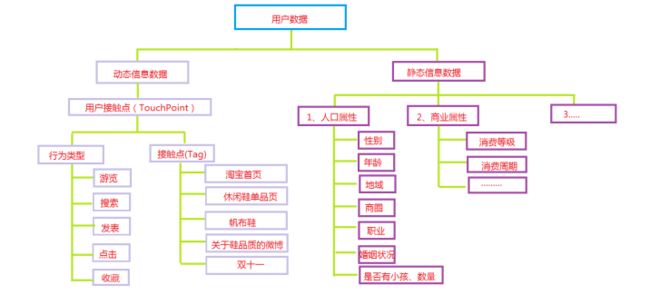
用户数据分为2类:动态信息数据、静态信息数据
静态信息数据来源:
- 用户填写的个人资料,或者由此通过一定的算法,计算出来的数据
- 如果有不确定的,可以建立模型来判断,比如用户的性别注册没有填写,可以建立模型,根据用户的行为来判断用户性别是什么,或者它的概率
动态信息数据来源:
- 用户行为产生的数据:注册、游览、点击、购买、签收、评价、收藏等等。
- 用户比较重要的行为数据:游览商品,收藏商品、加入购物车、关注商品
根据这些行为特性可以计算出:用户注册时间、首单时间、潮妈族、纠结商品、最大消费、订单数量、退货数量、败家指数、品牌偏好等等。