面试总结
知识回顾以及总结
哎,电子竞技(撸代码),菜是原罪。。。
1 HoneyWell 实习面试问题(5.16)
① 进程间的通信方式有哪几种?
这个问题放在5月份,确实不知道,现在也就那样子了,主要是共享内存、消息管道、套接字等等,说确实是很容易就说出来了,但是还是要自己demo一下,才能掌握得深刻一点。具体的内容可以看这里
个人感觉这个地方还可以发散的知识点还有,Linux下和Windows下创建进程的方式(Linux下创建一个子进程的接口时fork(),Windows下创建一个子进程的接口时CreatreProcess()),以及创建一个子进程时,保存的是什么数据。
②VS编译时(C++编译选项),在Release下,可以设置为MT和MD模式,debug模式下可以设置为MTD和MDd模式,有什么作用?
一般来说,MT模式是把程序运行时的所用到的库编译到obj文件当中,也就是在最终的输出文件中包含了链接库的所有信息,但是这样子输出的文件体积大,对环境的依赖较小(这个地方的知识点我个人感觉很像在问你Dll和Lib的区别);MT模式则不会把运行时所需要的库编译到obj文件当中,而是作为Dll文件在运行时动态的加载进去,这样子输出的文件体积较小,但是对环境的要求很严格。
③智能指针了解吗?
指针指针主要是指shared_ptr、unique_ptr、weak_ptr。这三类指针,其中,shared_ptr是一种可以由多个shared_ptr指针(对象)同时指向一个地址的指针(对象);unique_ptr只能由一个unique_ptr指针(对象)指向同一个地址的,两个unique_ptr不能共享一个地址。weak_ptr是和shared_ptr一起使用的,weak_ptr的增加不会增加引用计数。
2 字节跳动实习面试 7.6
①++前置和后置的区别?
C++ Prime 中有说到,前置操作返回的是左值(左值是可以被取地址的),后置操作返回的是右值(右值是不可以被取地址的)。
对于基础类型的变量和指针前置操作和后置操作基本没有什么性能的差异,因为代码反汇编化后的长度是一样的,所以时间上的开销是一样的。
但是对于复杂的类类型的对象及其迭代器时,前置操作的性能是优于后置操作的,因为后置操作符的底层实现在递增之前创建元素的拷贝,然后返回拷贝。
②在构造函数中能不能调用虚函数?
调用时可以调用的,但是不推荐这样子使用。
首先,回顾一下C++中引入虚函数的作用是为了实现多态(运行时绑定),要达到的是不同的派生类对象在相同的接口下完成不同的功能。
那么,如果在构造函数中调用虚函数时,那么进入派生类的构造函数时,会先进入基类的构造函数,从派生类的构造顺序中我们可以知道(先是基类的构造函数被调用然后再调用派生类的构造函数),那么如果基类首先已经被构造了以后,从构造函数中调用虚函数时,此时的多态指针(基类指针或者是派生类指针)只能指向一个地方,那就是基类,那么此时的虚函数则必然时基类的虚函数,虚函数根本无法起到动态绑定的作用。
3 ARM实习面试 7.16
这次面试先做了一套卷子,后面在上大投秋招岗位的时候居然是一套卷子,记忆比较深刻的知识点主要有
①字符串相关的知识点
char b[5] = "abcd"; //这个时候数组b已经装满了,b[4]='/0'和string是不一样的
//b此时其实是一个指针(指向第一个字符),*b是第一个字符
char c = 'a' - 32; //字符和数字相加减会首先计算ASCII码,变成相应的字符,
//'A'-->65,'a'-->97;'0'-->48;
string d = "1234",string e = d + '5';//字符串加上字符会自动拼接
②斐波那契数列的循环写法,这个题可以看我的牛客网解法
其实能够用循环就不要用递归,自己画递归树会有很多的重复计算。
③链表反转的递归写法,这个题目也是出其不意,循环写法背的滚瓜烂熟的,结果来了一个这个,哎,leetcode上有刷,递归方法的倒数第二行和倒数第三行要好好体会
④实习面试时笔试题的最后一个答题是写出归并算法中的并(merge),具体的可以参照禹哥的思路或者是头头的写法,其实思路是一样的,都是根据头中尾三个index,将原始的数组分成两个,然后从两个数组的头开始比较,小的往最终的数组里面放,然后把小的那个数组的index+1,直到最后某个数组的index已经到尾了,然后把剩下的那个数组的所有元素全部放入到新的数组中。
4 阿里面试 8.9
① 引用和指针的区别?
从现象上看,指针不用被初始化,引用必须被初始化(这个初始化感觉是可以和定义这个概念做比较的,因为声明和定义这里也是个知识点);指针可以指向空指针,而引用则不能指向空值;指针被初始化以后,可以改变指针本身(即更换指针所指向的地址),而引用被初始化以后则不能被修改。
从本质上看(从编译上看),代码在编译时,分别将指针和引用添加到符号表上(符号表这部分的内容可以看《程序员的自我修养》),符号表上记录的时变量名以及变量所对应的地址。那么当指针变量在符号表上对应的的地址则是指针变量自己的地址,而引用在符号表上对应的地址是其引用对象的地址。引用只是被引用变量的一个别名而已,不具备修改被引用变量的资格。所以,从编译的时就决定了两者的差异性,指针变量对应的地址是它自己,我自己想怎么修改就怎么修改,而引用对应的地址是别人的,这就可由不得他了。
②const关键字的作用?
修饰变量,说明该变量不可以被改变;
修饰指针,分为指向常量的指针和指针常量;(这地地方的知识点容易混淆,下面再解释下)
常量引用,经常用于形参类型,即避免了拷贝,又避免了函数对值的修改;
修饰成员函数,说明该成员函数内不能修改成员变量,也不能调用修改成员变量的函数。(这个作用很容易忘记)
char greeting[] = "HelloWorld";
char test1[] = "ooo";
int a = 1;
//这里的const是就进原则,const靠近谁就修饰谁,
const char* p2 = greeting;
//明显是const char,p2只能指向char类型的地址,但p2可以指向新的char类型的地址(p2可以修改)
p2 = test1;//ok
p2 = &a;//报错,修改类型
*p2 = 'j';//报错
char* const p3 = greeting;//很明显,const修饰p3,说明p3(地址)不允许被修改
p3 = test1;//报错,修改地址
*p3 = 'u';//ok,并且将"HelloWorld"修改为"uelloWorld";p3地址未变,只是里面的值改变了
③为什么要用函数指针?
把指针函数当作形参传递给某些具有一定通用功能的模块。封装成接口来提高代码的灵活性和后期维护的便捷性。具体的可以看这里
④*p与 **p的区别?
我当时回答的是,*p是普通的指针指向一个变量的地址, **p是指向指针变量地址的指针
⑤ 纯虚函数在子类中没有重写的时候会有什么问题?
妈的,这个题当时都没有答上来,自己在平时开发的时候也有遇到过的,这里要是在子类中没有重写的话,编译都会报错!!!
5 网易互娱面试9.20
① 内敛(inline)函数和宏定义的区别?
内联函数在运行时可以调试,而宏定义不可以;
编译器会对内敛函数的参数类型做安全检查,或者自动类型转换,而宏定义函数不会;
内联函数可以访问类的成员变量,而宏定义不可以。
内联函数和普通函数相比可以加快程序的运行速度,在编译时直接镶嵌到目标代码中(缺点就是目标代码体积过大),和C时代的宏函数相比,inline函数更加安全可靠(以增加空间消耗为代价的),更加具体的可以看这里。
宏是在代码处不加任何验证的简单替换,而内敛函数是将代码直接插入到调用处,减少了调用都得时的资源消耗。
②动态链接库(dll)和静态链接库(lib)的区别?
使用静态链接库时,lib 中的指令都全部被直接包含在最终生成的 exe 文件中了,此时exe文件体积会很大。
使用动态链接库时,该 dll 不必被包含在最终exe文件中,exe 文件执行时可以“动态”地引用和卸载这个与 exe独立的 dll 文件,此时exe文件的体积较小。
接下来还可以再问,怎么生成dll与lib?
可以参考这篇文章,这一篇也可以
在windows怎么调用dll与lib?
对于静态链接库(比较简单):
首先,静态链接库的使用需要库的开发者提供生成库的.h头文件和.lib文件。
#pragma comment(lib,"xxxxx.lib")//显式调用
动态链接库
也分为分为隐式调用(与上面lib的调用类似)和显示(动态)调用
HMODULE hDll = LoadLibrary("DLLDemo1.dll");
Func xxx = (AddFunc)GetProcAddress(hDll, "xxx");;
cout<<xxx(3,5)<<endl;
更加具体的可以参考上面的两篇文章
③ 进程与线程相关的知识?
进程是CPU分配资源的最小单元(windows下的每一个服务都是一个进程,进程就是一个exe文件,可以自己点开任务管理器看,所以CPU分配资源的时候就要将一个exe文件运行所需要的所有内存资源全部分配完毕),线程是CPU调度的最小单元(但是由于现在的CPU不是一直执行一个exe文件的,每个进程的程序片段都只能运行一部分时间(run状态),这个程序片段就是线程)。
线程的同步方式和机制(有的也叫做线程间的通信,也对因为一个进程中的多个线程通信的作用就是为了同步)。
实际上,互斥和同步对应着线程间通信发生的两种情况:
当有多个线程访问共享资源而不使资源被破坏时(互斥);
当一个线程需要将某个任务已经完成的情况通知另外一个或多个线程时(同步);
从大的方面讲,线程的同步可分用户模式的线程同步和内核对象的线程同步两大类。用户模式中线程的同步方法主要有原子访问和临界区等方法。其特点是同步速度特别快,适合于对线程运行速度有严格要求的场合。
用户模式里面主要锁家族和条件变量(说法太多了,具体看这里)
内核对象的线程同步则主要由事件、等待定时器、信号量以及信号灯等内核对象构成。由于这种同步机制使用了内核对象,使用时必须将线程从用户模式切换到内核模式,而这种转换一般要耗费近千个CPU周期,因此同步速度较慢,但在适用性上却要远优于用户模式的线程同步方式。
win32下面有四种线程的(内核对象)同步方式,完整版可以看这里
临界区、互斥量(这两个主要用于互斥控制,线程互斥是一种特殊的线程同步),信号量、事件对象(都是以通知的方式进行同步控制)。
临界区:通过对多线程的串行化来访问公共资源,速度快,适合用于数据访问。
互斥量:互斥对象和临界区很像,只有拥有互斥对象的线程才有访问公共资源的权限,因为互斥对象只有一个,能保证公共资源不会同时被多个线程访问。互斥量也是内核对象,他与关键段都有线程的所有权所以不能用于线程的同步,互斥量能够用于不同进程之间的线程互斥问题,并且可以完美解决某进程意外终止所造成的“遗弃”问题。
信号量:它允许多个线程在同一个时刻访问同一资源,但是需要限制在同一时刻访问的资源的最大线程线程数目。
事件对象:通过通知操作的方式是来保持线程的同步,还可以方便实现对多个资源的优先级比较操作。
④ CPU的调度策略?
当时只记得大概的印象,答不出来。。。有四种,具体的可以看这里
每当CPU空闲时,操作系统必须按照一定的策略从就绪队列当中选择一个进程来执行。
调度的对象:进程或线程。其方式与原则是一样的。所以经常以进程来说明。
FIFO队列:先来先服务(CPU来服务),新增的进程插入到就绪队列的尾部,CPU每次从就绪队列头部获取进程。
优先级队列:给每个进程赋予一个优先级序号,CPU切换时,在就绪队列查找优先级最高的执行。
SJF短作业优先:CPU切换时,在就绪队列查找任务耗时最短的进程(时间长短根据历史记录推测)。
轮转调度算法:在FIFO基础上增加了一个时间片,CPU获取就绪队列头部的进程,在时间片范围内执行完任务则切换到下一个进程,如果没有执行完,将当前未执行完的进程加入到FIFO尾部,然后切换到下一进程。
⑤hash表解决地址冲突的方法?
这里就简单的说两个好了,
开放定址法(也称为线性探测法):当有两个数据在散列函数计算下产生的结果是一样的时候,一般就是后面那个数据在前面数据已经占住了坑位的情况下,则自动往后找一个空位。
链地址法:(hashmap用的就是这个)
当两个数存在的冲突的时候,则在原来的地方新增一个链表来存放冲突的数据,若后面还有冲突的数据,则继续往链表后面添加数据。
⑥计算一个class的字节数?
里面包含了虚函数等,这里涉及到的知识有虚函数表的实现机制!!!,以及this指针。
计算如下class Base1的大小
class Base1
{
public:
int base1_1;
int base1_2;
void f1(){ cout << "f1" << endl; }
void f2(){ cout << "f2" << endl; }
virtual void base1_fun1() {}
virtual void base1_fun2() {}
};
直接看结果。

由上图可知,对象b1的字节数为12字节,怎么来的呢?两个int类型的变量(8)一个虚函数表的指针(4),因此整个类的大小是12字节。这个地方要注意了class中的成员函数是不占字节数的,也就是说成员函数不是放在对象里面的。。。调用的时候就涉及到了对this指针的知识点了,这个等会再说。
如果涉及到了继承,再怎么计算class的大小呢?
再写一个子类
class Derive1 :public Base1
{
int derive1;
int derive2;
virtual void derive1_fun1() { cout << "this is derive1" << endl; }
void d1(){ cout << "derive" << endl; }
};
还是直接看结果好了。。。
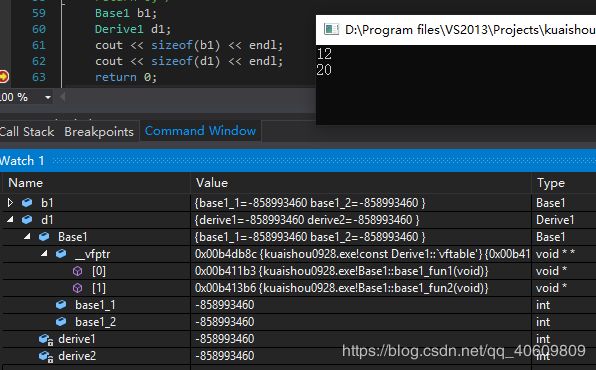
这里可以看到子类对象d1的大小是20字节,是直接在父类(12字节)的基础上直接加上了子类里面的两个int 类型变量的大小。而且很诡异的是,子类里面重新写了一个虚函数,但是在d1的内存分布里面居然没有看到。。。这个地方还是需要去看这篇文章,里面写的很详细,其实子类的虚函数地址就在父类的虚函数表的下面,但是现在看不到。好了这部分就不在叙述了,现在来看看,我们的成员函数到底是放在哪里的,每个对象是如何调用其成员函数的?
先看看类的成员函数的分布情况。其中每个对象的成员函数是一样的,那么就没要必要再为每个对象分配一个成员函数了,所以采用如下布局是最科学的。显然,这样做会大大节约存储空间。C++编译系统正是这样做的,因此每个对象所占用的存储空间只是该对象的数据部分(虚函数指针和虚基类指针也属于数据部分)所占用的存储空间,而不包括函数代码所占用的存储空间。
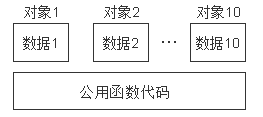
这里需要先了解一下内存的分布情况: C++程序的内存格局通常分为四个区:全局数据区(data area),代码区(code area),栈区(stack area),堆区(heap area)(即自由存储区)。
全局数据区存放全局变量,静态数据和常量;所有类成员函数和非成员函数代码存放在代码区(划重点!!!);为运行函数而分配的局部变量、函数参数、返回数据、返回地址等存放在栈区;余下的空间都被称为堆区。根据这个解释,我们可以得知在类的定义时,类成员函数是被放在代码区,而类的静态成员变量在类定义时就已经在全局数据区分配了内存,因而它是属于类的。对于非静态成员变量,我们是在类的实例化过程中(构造对象)才在栈区或者堆区为其分配内存,是为每个对象生成一个拷贝,所以它是属于对象的。
下面我们再来讨论下类的静态成员函数和非静态成员函数的区别:静态成员函数和非静态成员函数都是在类的定义时放在内存的代码区的,因而可以说它们都是属于类的,但是类为什么只能直接调用静态类成员函数,而非静态类成员函数(即使函数没有参数)只有类对象才能调用呢?原因是类的非静态类成员函数其实都内含了一个指向类对象的指针型参数(即this指针),因而只有类对象才能调用(此时this指针有实值)。这里主要参考的这篇文章的。
6 华为一面9.25
唉,太菜了。。。
一开始做了一个笔试题,说是什么一个完全二叉树,叶子节点要么有两个孩子要么没有孩子,给出这个树的所有节点数和高度,求这个树的形态???
当时给面试官说思路的时候,他说我的思路基本上是对的,但是代码写得太毛糙。。。
但是回来和室友讨论了一下,感觉他的题目有些问题,一个完全二叉树就是倒数第二层肯定是先填完。再来填最后一层,还是按照从左到右填。
①成员变量在初始化的列表中初始化和在构造函数中初始化的区别?
开胃菜
C++构造函数中初始化成员参数列表初始化成员(必须用原因:对象成员的初始化,const修饰的成员的初始化,引用成员的初始化(这两者都是因为不能再初始化后就不能再修改了,=赋值是不行的),子类调用父类的构造函数初始化父类成员) 参数列表在构造函数执行之前执行,参数列表中执行的是初始化(所有的成员,无论是否出现在参数列表中,都会有初始化),参数列表的执行顺序与类中成员的声明顺序,与类的继承顺序相一致构造函数中执行的一般是赋值多重继承,虚继承构造函数的参数初始化列表的区别
类对象的构造顺序是这样的:
1.分配内存,调用构造函数时,隐式/显示的初始化各数据成员;
2.进入构造函数后在构造函数中执行一般赋值与计算。
所以从上面可以知道,有三种情况需要必须用初始化列表进行初始化,那么当成员变量为对象,且该对象只有对象只有含参数的构造函数,也必须使用初始化列表初始化。
更加详细的可以往这里瞅,very good!!!
②用vector存放一组数据,删除其中小于3的数据,使用erase函数结合用lambda表达式写,一行搞定!
一脸懵逼,完全没有见到过。。。后面查了才知道。用的是remove_if这个函数
data.erase(remove_if(data.begin(), data.end(), [](int a){return a < 3; }),data.end());
//remove_if()是将lambda表达式中a>=3的数据往前移动了,有几个大于等于3的就移动几个
//然后返回最后的迭代器位置,可以使得erase函数删除从返回的迭代器开始到最后结束的数字。
③ delete[] 于delete的区别?
我当时回答的是前者是释放数组中存放由new的分配的动态内存,后者是直接释放普通的new出来的内存。
delete只会调用一次析构函数,而delete[]会调用每一个成员的析构函数。在More Effective C++中有更为详细的解释:“当delete操作符用于数组时,它为每个数组元素调用析构函数,然后调用operator delete来释放内存。”delete与new配套,delete []与new []配套,详细的可以看这里。
7 海康面试 9.27
①首先问了线程和进程的区别,然后直接问了windows下开启一个新的线程的API?
当时懵逼了,没有回答出来是调用哪个API。。哎
windows下面C++ 创建新的线程有两种方式
第一种:因为C++11之前,C++自身没有可用的库,因此调用的是windows.h(include"windows.h")中的API,函数名字是
CreateThread()。
HANDLE CreateThread(
LPSECURITY_ATTRIBUTES lpThreadAttributes,
SIZE_T dwStackSize, //线程的堆栈大小
LPTHREAD_START_ROUTINE lpStartAddress, //线程函数地址
__drv_aliasesMem LPVOID lpParameter, //线程函数的参数
DWORD dwCreationFlags,
LPDWORD lpThreadId
);
关于参数的详细介绍可以看这里。线程同步可以看这里
返回值,如果线程创建成功,则返回值是新线程的句柄。如果创建失败,则返回值为NULL。
第二种:C++11后,C++自身也有了创建新线程的库了,调用thread 类模板库(#include)
#include 这里还有一个知识点: join()和detach()的区别?
join()的作用前面已经提到,主线程等待子线程结束方可执行下一步(串行),detach()是的子线程放飞自我,独立于主线程并发执行,主线程后续代码段无需等待。详细的介绍可以看这里
② i++是不是原子操作?
我当时回答的不是,因为原子操作是不可再分的,原子操作(atomic operation)是不需要synchronized",这是多线程编程的老生常谈了。所谓原子操作是指不会被线程调度机制打断的操作;这种操作一旦开始,就一直运行到结束,中间不会有任何 context switch(切换到另一个线程)。当时个人认为i++这个过程是i=i+1的,当线程运行完i+1时,它是可能被其他线程打断的。
③ extern C的作用?
extern C 的作用是告诉编译器extern c后面的这部分代码按照C的风格编译和链接,这是C++中为了实现对C代码的兼容性,因为C++和C在编译的时候,全局变量和函数名编译后的命名方式有很大区别。
额外的 extern 的作用?
extern的原理很简单,就是告诉编译器:“你现在编译的文件中,有一个标识符虽然没有在本文件中定义,但是它是在别的文件中定义的全局变量,你要放行!”(意思就是我要用别人定义的变量,你赶紧给我放行)
有一篇总结得非常好的,请看这里。
④ ifndef 的作用?
在代码中见过,从来没有仔细想过这是什么作用。
第一个作用 防止头文件的重复包含以及头文件中变量的重复定义。
第二种方便调试时的宏开关。
⑤md5可以反向吗?
忘了自己回答是可以还是不可以了,感觉工程师一直给我挖坑。。。实际上,md5是不能反向的,不然还加个什么密!!!。
⑥ 函数的定义与声明的区别?
我当时回答的是,函数的声明就是说明有这个函数名了,以及函数入口的参数个数和类型以及函数的返回值是什么类型的,函数的定义就是将函数的内部功能具体的实现一次。
另:变量的定义与声明的区别?
变量在使用前就要被定义或者声明。 在一个程序中,变量只能定义一次,却可以声明多次。
定义分配存储空间,而声明不会。
extern int i; //声明,不是定义
int i; //定义,但是未初始化
int i=1; //定义,即使有extern 关键字但是赋值了就是定义
所以现在应该可以弄清了,声明就是用extern修饰的变量(类型,变量名,但是不能赋值),详细的可以看这里。
⑦ 快慢指针可以走三步吗?
前面是链表有环怎么判断有环和链表相交问题,我都用了快慢指针,然后就问了这个问题,,,我当时回答的是不可以(真的是到处给我挖坑,艰难),后来回来和室友讨论了一下,应该是可以走三步的,只要能够相遇就行了。
⑧ 大字节序和小字节序?
啥玩意都不知道。。。看前辈们总结的吧,还有一个可以看看。
小字节序:(比如x86体系) 数据的低字节放在低地址处,比如一个整型数0x12345678,在内存中的分布为:
-----------
| 78 | xxxx_0000
-----------
| 56 | xxxx_0001
-----------
| 34 | xxxx_0002
-----------
| 12 | xxxx_0003
-----------
大字节序:(比如PowerPC体系) 数据的低字节放在高地址处,比如一个整型数0x12345678,在内存中的分布为:
-----------
| 12 | xxxx_0000
-----------
| 34 | xxxx_0001
-----------
| 56 | xxxx_0002
-----------
| 78 | xxxx_0003
-----------
网络字节序: TCP/IP协议传输数据时,字节序默认大端。
8 美光笔试加面试 9.27
① 信号量的物理意义?
Dijkstra把整型信号量定义为一个整形量,除初始化外,通过两个标准的原子操作(Atomic Operation)wait(s)和signal(s)来访问。这两个操作很长时间以来,一直被分别称为P、v操作。wait和signal操作可描述为:
wait(s):while s≤0 do no_op:
s:=s-1;
signal(s) : s :=s+1;
wait(s)和signal(s)是两个原子操作,因此,它们在执行时是不可中断的。亦即产生一个进程在修改某信号量时,没有其他进程可同时对该信号量进行修改。此外,在wait操作中,对s值的测试和做s:=s-1操作时,都不可中断。
信号量的物理意义如下:
(1) 若信号量s为正值,则该值等于在封锁进程之前对信号量s可施行的P操作数,亦即等于s所代表的实际使用的物理资源个数。
(2) 若信号量s为负值,则其绝对值等于登记排列在该信号量s队列之中等待进程的个数,亦即恰好等于对信号量s实施P操作而被封锁起来并进入信号量s队列的进程数。
(3) 通常P操作意味着请求一个资源,V操作意味着释放一个资源。在一定条件下,P操作代表挂起进程操作,而V操作代表唤醒被挂起进程的操作。
②多线程下并发执行的效率和串行的谁的效率高?
下次再更。。。
③ 32位系统下,整形和浮点型数据的精度?
这个问题也是一直都没有注意,现在注意下!!!
单精度浮点数(float)总共用32位来表示浮点数,其中尾数用23位存储,加上小数点前有一位隐藏的1
(IEEE754规约数表示法),`2^(23+1) = 16777216。因为 10^7 < 16777216 < 10^8,所以单精度
浮点数的有效位数是7位。考虑到第7位可能的四舍五入问题,所以单精度最少有6位有效数字。
同样地:双精度浮点数(double)总共用64位来表示浮点数,其中尾数用52位存储,
`2^(52+1) = 9007199254740992,10^16 < 9007199254740992 < 10^17,
所以双精度的有效位数是16位。同样四舍五入,最少15位。
④ 栈内存中存放的是哪些数据?
我当时回答的是栈内存中存放的是临时变量个局部变量,然后工程师又问了函数的形参和返回值存放在哪,我回答的也是存放在栈区,因为形参和返回值都是由系统分配资源然后进行回收的,因此应该和临时变量一样都存放在栈区。