ECCV 2020 | 腾讯 AI Lab 16篇入选论文解读

本文转载自腾讯AI实验室(tencent_ailab),介绍 ECCV 2020 中腾讯 AI Lab 16篇入选论文。
计算机视觉领域三大顶会之一的 ECCV(欧洲计算机视觉会议)今年将于 8 月 23-28 日举办。受新冠肺炎疫情影响,今年的 ECCV 与 CVPR 一样是完全的线上会议。近日,ECCV 2020 公布了论文收录情况:https://eccv2020.eu/accepted-papers。
据统计,本届 ECCV 共收到 有效投稿 5025 篇,是 ECCV 2018 论文投稿量的两倍。最终,会议接收了其中 1361 篇论文,接收率为 27%,其中包括 104 篇 Oral 展示论文(占总量 2%)及 161 篇 Spotlight 展示论文(占总量 5%)。
腾讯 AI Lab 共有 16 篇论文被 ECCV 2020 收录,其中包括 1 篇 Oral 展示论文和 2 篇 Spotlight 展示论文,涵盖腾讯AI Lab 近年来重点研究的多模态学习、视频内容理解、对抗攻击与对抗防御、基于生成模型的图像编辑等课题。下面将分主题简要解读腾讯 AI Lab 的入选论文,我们也希望能在 ECCV 2020 线上会议上与全世界的研究者共同分享和探讨计算机视觉领域的最新进展。
Oral 展示论文
利用共生编码器-解码器与特征均衡化进行图像空洞修复
Rethinking Image Inpainting via a Mutual Encoder-Decoder with Feature Equalizations
https://arxiv.org/abs/2007.06929
本文为 ECCV 2020 Oral 展示论文,由腾讯 AI Lab 主导,与湖南大学合作完成,提出了使用带特征均衡化的共生编码解码器的图像修复方法。
深度卷积神经网络中的编码器-解码器网络能够提升图像空洞修复的效果。已有方法虽然可以在空洞区域逐步修复图像结构和纹理,其主要是利用两个编码解码器进行分别处理。每一个编码器的深度卷积特征在训练中会捕获丢失的结构或者纹理而非将它们作为整体考虑。如此未充分利用的编码器特征限制了同时恢复结构和纹理的潜能。
本文提出了一个用以实现结构和纹理联合修复的共生编码器-解码器网络。这个新设计使用编码器的浅层和深层特征来分别代表结构和纹理信息。深层特征传送至结构分支,同时浅层特征传送至纹理分支。在每个分支中,分别在其卷积特征的各个尺度下进行补洞操作。两个分支填充好的卷积特征并联在一起然后被均衡化。在特征均衡过程中,本文首先调整通道的关注度然后提出一个双边传播激活的函数来实现空间域均衡化。由此,在特征层面填充空洞区域的结构和纹理特征可以进行多尺度的相互补充。然后使用均衡后的特征对解码器以跳跃层的形式进行补充。
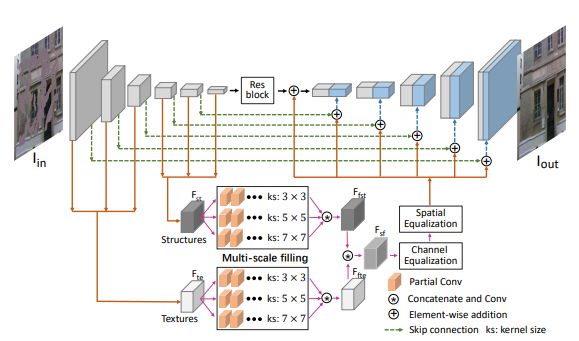
新提出的编码器-解码器网络结构示意图,其基于单个编码器-解码器。在编码器特征中归为结构和纹理特征两类,将这两类特征分别在特征空间做多尺度内容填充后进行特征均衡。使其结构与纹理对应充分并通过跳跃层指导最终的图像内容填充。
在标准数据库中的实验表明,新提出的方法对恢复结构和纹理十分有效,跟现有方法相比性能优异。
多模态学习
多模态学习研究的是如何同时基于视频、图像、文本、语音等不同模态的数据进行学习,这类技术能让 AI 更全面地学习有关这个世界的知识,也因此被认为是 AI 发展的未来方向,在自动驾驶、机器人、医疗和数字助理等领域都有重要的应用前景。多模态学习是腾讯 AI Lab 的重点研究领域之一,也是腾讯 AI Lab 近来重点研发的数字人的核心技术,今年有 4 篇相关论文被 ECCV 2020 接收,其涵盖的主题主要是视频/图像与文本的多模态学习。
1. 针对视频中时序句子定位和事件描述任务的学习模态间交互
Learning Modality Interaction for Temporal Sentence Localization and Event Captioning in Videos
本文为 ECCV 2020 Spotlight 论文,由腾讯 AI Lab 与复旦大学合作完成,提出了一种用于描述并定位视频事件的视频-文本多模态学习新方法。
自动生成描述事件的句子并在视频中定位句子的位置这两个重要任务连接了语言和视频两大领域。近期的技术多通过使用现成的视频特征来利用视频的多模态本质,但却很少探讨模态之间的交互。
受人脑中存在跨模态交互这一事实的启发,本文提出了一种学习成对模态交互的新方法,以便更好地利用视频中每对模态的互补信息,从而改善两项任务的性能。研究者以成对方式在序列和通道级别上对模态交互进行建模,并且成对交互还为目标任务的预测提供了一些可解释性。研究者还进行了广泛的控制变量实验,结果表明新提出的方法是有效的,特定的设计选择也在其中得到了验证。
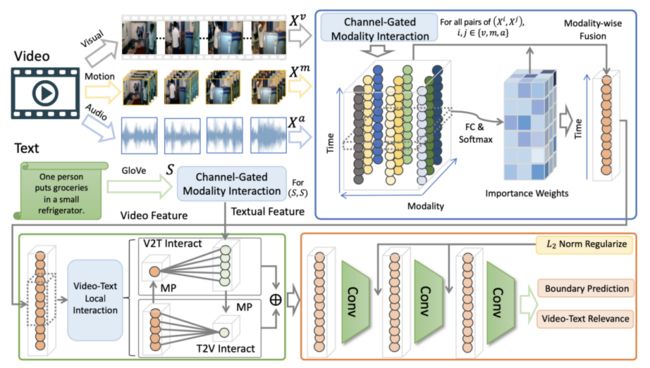
新提出的方法的工作流程,包含视觉、动作、声音的多模态数据与文本进行交互
如上图所示,首先为每个视频提取3个典型的模态(静态视觉模态、运动模态、音频模态),每个模态的特征表示为包含若干特征向量的序列,随后对每一对的(两个)模态进行序列层面的交互计算,使得两模态间的信息被互相充分利用,在此之上,通道层面的模态交互则被用于计算一个门控(gating)来强调二者交互之后重要的特征通道。最后这些交互结果会基于它们的重要程度被聚合成为一个序列用于下游任务,这里的重要程度可视化之后可以提供一些解释性。
在 MSVD、MSR-VTT(时间描述生成)、 Charades-STA 和 ActivityNet (时序句子定位)四个标准基准数据集上,新提出的方法在实验中都取得了当前最佳的表现。
2. 基于场景图分解的自然语言描述生成
Comprehensive Image Captioning via Scene Graph Decomposition
https://arxiv.org/abs/2007.11731
本文由腾讯 AI Lab 主导,与威斯康星大学麦迪逊分校合作完成,提出了一种基于场景图分解的自然语言描述生成方法。
使用自然语言来描述图像是一项颇具挑战性的任务,本文通过重新回顾图像场景图表达,提出了一种基于场景图分解的图像自然语言描述生成方法。该方法的核心是把一张图片对应的场景图分解成多个子图,其中每个子图对应描述图像的一部分内容或一部分区域。通过神经网络选择重要的子图来生成一个描述图像的完整句子,该方法可以生成准确、多样化、可控的自然语言描述。研究者也进行了广泛的实验,实验结果展现了这一新模型的优势。
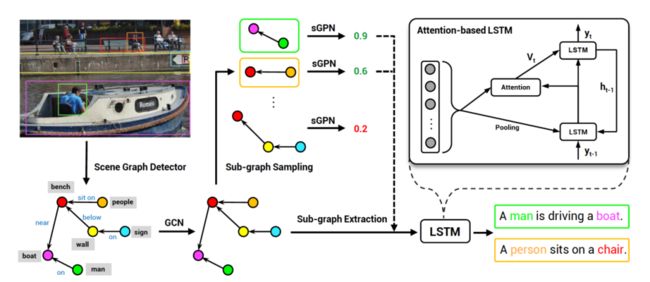
新提出的方法的工作流程
如图所示,新方法从输入图像生成场景图,并且分解为一系列子图。本文设计了一个子图生成网络(sGPN),用于学习识别有意义的子图,这些子图基于注意力的 LSTM 可以进一步解码生成句子,并且将短语匹配到图节点对应的图像区域。通过利用子图,模型可实现准确、多样化且可控制的图像描述生成。
3. 通过递归子查询构造改善视觉和自然语言匹配
Improving One-stage Visual Grounding by Recursive Sub-query Construction
本文由腾讯 AI Lab 与罗切斯特大学合作完成,提出了一种新的视觉和自然语言匹配方法。
当前的一站式视觉和自然语言匹配方法对于复杂长序列的语言建模需要提高。为了解决这个问题,本文提出了一种基于循环构造子序列的方法来帮助提高视觉-自然语言匹配。通过循环地在图像和构造的语言序列之间进行推理和建模,新方法能极大提升视觉和自然语言匹配的系统性能。在主要的数据集上,新方法都取得了更好的效果。尤其是在更长更复杂的查询上,新方法的表现更为优异,这也验证了新提出的查询建模方法的有效性。
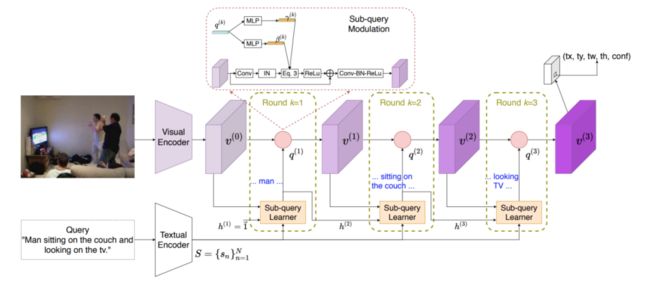
新提出的递归子查询结构框架,在每个循环中,都会构造一个新的子查询结构以细化文本依存的视觉特征v(以紫色显示), 其中q(k)是第k次所更新的子查询的特征。
4. 通过最小化逆动力学分歧来实现从观察中模仿学习
Consensus-Aware Visual-Semantic Embedding for Image-Text Matching
https://arxiv.org/abs/2007.08883
本文由腾讯 AI Lab 主导,与天津大学合作完成,提出了一种新的视觉-文本匹配模型。
当今互联网中存在海量的多媒体数据,其中最广泛存在的分别是图像和语言数据。图像-文本匹配任务的核心目的是跨越视觉和语言间的语义鸿沟,进而实现更精准的语义理解。现有的方法只依赖于成对的图像-文本示例来学习跨模态表征,进而利用它们的匹配关系并进行语义对齐。这些方法只利用示例级别的数据中存在的表层关联,而忽略了常识知识的价值,这会限制其对于图像与文本间更高层次语义关系的推理能力。
本论文提出将两种模态间共享的常识知识注入到视觉语义嵌入模型中,进而用于图像文本匹配。具体来说,首先基于图像描述语料库中概念间的统计共生关系构造了语义关系图,并在此基础上利用图卷积得到共识知识驱动的概念表征。通过共识知识和示例级表征的联合利用,能够学习到图像和文本间的高层次语义关联并进行语义对齐。
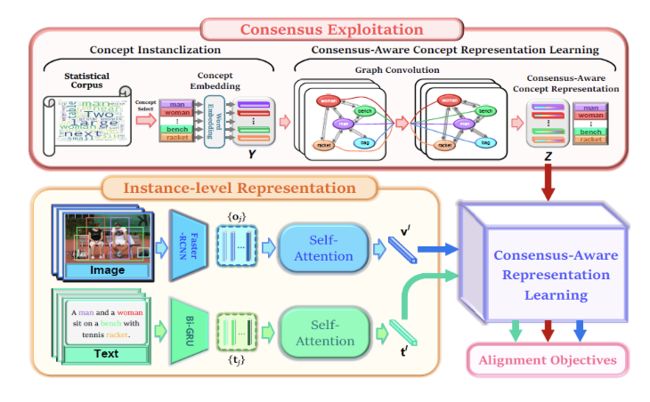
模型的不同模块的结构
给定输入的图像区域特征和文本单词特征,本文提出的 CVSE 模型不仅可以学习示例级别特征,还挖掘共识知识来学习更高层次的语义关联,从而实现更加准确的文本图像匹配。
在两个公共数据集上的大量实验表明,使用共识知识可以大幅增强视觉语义嵌入模型的表征能力,使其在图像-文本双向检索任务上的表现显著优于现有方法。
去雨网络
当前基于视觉的自动驾驶技术在标准场景中已有相当好的表现,但下雨天了怎么办?雨水可能会遮挡视线,造成系统误判。这时候,消除雨水对视野场景中信息的影响就非常重要了。腾讯 AI Lab 的 ECCV 2020 入选论文中有 2 篇研究了基于神经网络的去雨技术。
1. 超越单目去雨:基于语义理解的双目去雨网络
Beyond Monocular Deraining: Stereo Image Deraining via Semantic Understanding
本文由腾讯 AI Lab、澳大利亚国立大学、中科院信工所与阿布扎比人工智能研究院合作完成,提出了一种可基于双目图像消除场景中雨滴对信息的影响的方法。
雨滴能影响图片的背景信息,降低图片的质量,进而影响现有的基于视觉的智能系统的性能。现在,很多在自动驾驶领域使用的方法都是基于双目图片的,然而却很少有基于双目图片的去雨方法。同时,现有的单目去雨方法也没有很好地考虑语义信息。
这篇论文提出了一种基于语义理解的双目去雨方法。该方法首先使用一种模型理解语义信息并且得到一种初始的去雨效果图,之后将语义信息与初始的去雨效果图融合,接着与多角度的图片信息融合,得到最终的去雨图。为了测试不同方法的去雨效果,研究者还合成了两个双目去雨的数据库。实验结果表明新提出的方法在单目去雨和双目去雨上都能得到很好的效果。
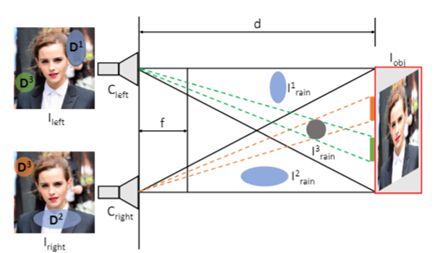
对于一组上双目相机拍摄的照片来说,同样的雨滴在两张照片产生的效果是不一样的。本文新提出的双目去雨方法可利用双目图片的视觉差完成雨滴移除操作,恢复清晰图片。
2. 利用雨痕和雨雾分析进行图像去雨
Rethinking Image Deraining via Rain Streaks and Vapors
本文由腾讯 AI Lab 与电子科技大学和上海交通大学合作完成,文中提出通过将雨痕建模为传输介质而非场景物体来实现图像去雨。
图像去雨模型是将含雨图像建模为场景图像、传输介质、雨痕和大气光的融合。尽管前沿的去雨模型不断涌现,但它们认为雨痕和场景内容物体具有相似的属性,而不是一种传输介质。由于雨雾往往蕴含在传输介质中从而产生朦胧效果,因此雨痕和雨雾的融合无法很好地反映含雨图像的生成过程。本文提出重新将雨痕归为传输介质而与雨雾一起对含雨图像进行建模。
本文提出了一个叫 SNet 的编码器-解码器来捕获雨痕的传输介质特性。由于雨痕形状和方向各不相同,研究者在 SNet 中采用了 ShuffleNet 单元来捕获其各向相异的表征。由于雨雾伴随雨痕,研究者又提出了用于多尺度雨雾介质预测的 VNet。另外,研究者还使用了一个名为 ANet 的编码器来估计大气光。为了预测传输介质和大气光从而进行含雨图像复原。,研究者对SNet、VNet 和 ANet 进行了联合训练。
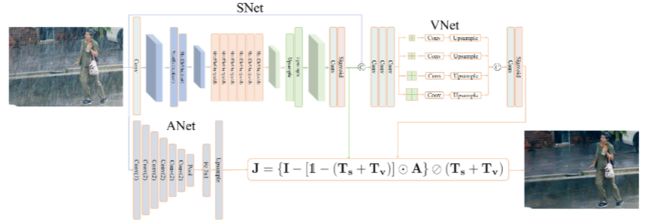
去雨模型整体架构示意图。这个新的去雨模型将雨痕与雨雾作为不同的传输介质来建模。该模型会通过上图中的公式计算去雨后的图像。公式中各项均有相对应的网络估计结果,从而实现最终的去雨图像生成。
研究者进行了大量实验,结果表明新提出的去雨模型确实有效,而且也优于之前的其它方法。
对抗攻击
深度神经网络在对抗攻击面前的脆弱性已经成为其在关键领域应用的最大绊脚石之一,探索不同形式的对抗攻击以及对应的防御技术一直以来都是 AI 领域重要的研究课题。腾讯 AI Lab 今年共有3篇相关论文入选,包括实现对抗攻击的方法以及新的防御思路。
1. 针对对抗攻击的鲁棒目标跟踪方法
Robust Tracking against Adversarial Attacks
https://arxiv.org/abs/2007.09919
本文由腾讯 AI Lab 与上海交通大学合作完成,提出了一种针对对抗攻击的新思路。
深度神经网络易受到对抗攻击的伤害,目前仅有少量的工作以提升深度目标跟踪算法的鲁棒性从而克服对抗攻击为目标。目前在对抗攻防的研究集中在图像方面。本文不同于先前的关注方向,优先提出在视频序列中产生对抗样本来提升跟踪的鲁棒性。为此,研究者提出在产生轻量对抗扰动时候将时序信息纳入考虑。一方面,在原始的视频序列中加入时序扰动作为对抗样本使得跟踪性能大幅下降。另外一方面,串行地从输入视频中估计扰动并有效地剔除从而实现跟踪性能的修复。这种新提出的对抗攻防方法被用在了前沿的深度跟踪算法中。在数据库中大量实验证明,这种防御方法不仅能有效避免由对抗攻击带来的性能下降,而且能够在原始视频中提升现有的跟踪性能。
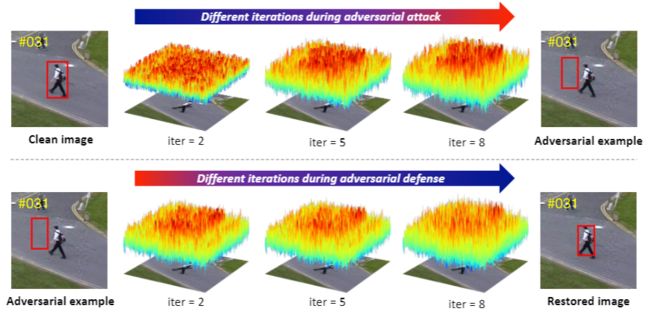
视频对抗攻防的可视化
上图展示了一个视频对抗攻防的示例,在第一行攻击过程中,随着迭代次数增多,扰动逐渐集中于物体周围从而使得现有算法丢失目标物体的定位。在第二行防御过程中,扰动逐渐被估计并削弱,使得现有算法得以重新找回目标物体。
2. 判别性局部域对抗网络
Discriminative Partial Domain Adversarial Network
https://arxiv.org/abs/1911.12036
本文由腾讯AI Lab与上海交通大学和卡尔加里大学合作完成,提出了一种新的判别性局部域对抗网络。
标准域适应假设源域和目标域共享相同的标签空间,是迁移学习的基础构件。一个更普遍和现实的设置是目标域的标签空间是源域的子集,称为部分域适应(Partial domain adaptation, PDA)。以前的方法通常将整个源域匹配到目标域,由于源域中的源-负类在目标域中不存在,就可能导致负迁移。
本文提出了一种新的判别性局部域对抗网络。研究者首先提出用硬二进制权重来区分源域的正样例和负样例。源阳性样例是指两个域共享标签空间的样例,其余源域样例为源阴性样例。基于上述二值重标策略,新提出的算法最大限度地提高了源阴性样例与所有其它样本(源阳性样例和目标样例)之间的分布发散性,同时最小化源阳性样本与目标样本之间的域差异,从而获得可判别的域不变特征。
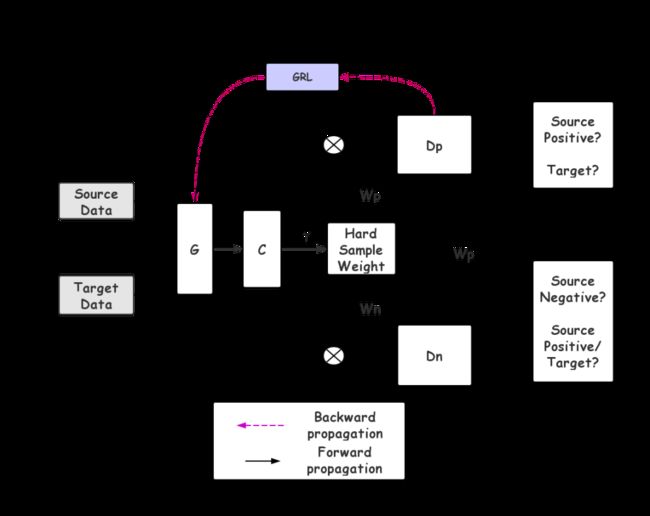
新提出的局部域对抗网络示意图
不同于往常的局部域适应网络,在硬二值权重的基础上,DPDAN不仅能辨别源域中的正类与负类,还能在拉近源域正类与负类之间的域差异的同时,拉远源域负类和其它样例之间的距离。
实验证明,DPDAN能够有效地减少源-负类引起的负迁移,论文还从理论上证明了它能够减少标签空间不匹配引起的负迁移。在4个基准领域自适应数据集上的实验表明,DPDAN优于最新的方法。
3. 利用扰动分解的稀疏对抗攻击
Sparse Adversarial Attack via Perturbation Factorization
本文由腾讯 AI Lab 主导,与清华深圳国际研究生院合作完成,提出了利用扰动分解实现稀疏对抗攻击的新思路。
本文的研究课题为稀疏对抗攻击,其目的是在正常图像的部分像素上加入对抗扰动,达到欺骗深度神经网络模型的目的。稀疏对抗攻击面临着两个挑战,包括扰动的位置和扰动大小如何确定。很多现有工作通过人为设定或者启发式策略来确定扰动的位置,然后再利用现成的密集攻击算法来确定扰动的大小。
本文提出将单个像素上的扰动分解为两个变量的乘积,包括扰动大小和一个二元选择变量(状态为0 或者1)。如果状态选择变量为1,则该像素被扰动,反之不扰动。基于这个分解,本文将稀疏对抗攻击建模为一个混合整数规划问题,可以同时优化所有像素对应的二元选择变量和连续的扰动大小,并带有一个基数限制用于控制被扰动像素的个数。新提出的扰动分解形式还可以为模型带来额外的灵活性,可以针对二元选择变量或者扰动大小变量添加一些想要达到的约束限制,比如群稀疏和增强视觉上的不可察觉性。

稀疏对坑攻击示例
在上述示例中,本文提出的稀疏攻击算法不仅可以优化出稀疏且微小的对抗噪声,而且噪声位置与图像前景物体有较大的重叠,尤其是嵌入群稀疏约束后,更能凸显关键区域。这说明,本文提出的稀疏攻击算法还可以为模型可解释性提供新的分析工具。
本文还提出了一个高效的优化算法,可以将混合整数规划问题等价转化为一个连续优化问题。充分的实验表明所提出的稀疏对抗攻击算法超越了现有最好的稀疏对抗攻击算法。方法的实现代码将在如下网址开源:
https://github.com/wubaoyuan/Sparse-Adversarial-Attack
时序动作分割与检测
时序动作的分割与检测是视频计算机视觉技术的一大常规任务,对自动驾驶和机器人等应用至关重要,下面 3 篇论文是腾讯 AI Lab 在这一方向的探索成果。
1. 动作识别中的时序帧间差异表征学习
Temporal Distinct Representation Learning for Action Recognition
https://arxiv.org/abs/2007.07626
本文由腾讯 AI Lab、腾讯优图实验室、新加坡南洋理工大学、美国纽约州立大学布法罗分校合作完成,提出了一种用于动作识别的时序帧间差异表征学习方法。
二维卷积神经网络(2D CNN)已成功运用到了图像识别中,研究人员开始尝试使用2D CNN提取视频数据的表征。然而在使用2D CNN对视频数据进行特征提取的过程,视频的不同帧需要共享2D CNN的卷积核,这将导致不同帧间重复冗余信息的提取,特别是不同帧共有的场景信息,因此忽略了帧间变化信息的提取。
本文针对此问题提出了两种方法,1)设计了一种序列式的通道筛选机制,即渐进式增强模块(Progressive Enhancement Module, PEM),对具有判别力的通道进行激励,并避免重复信息的提取;2)设计了时序多样性损失函数(Temporal Diversity Loss, TD Loss),对网络的卷积核进行矫正,从而使网络关注帧间变化信息而不是帧间相似的场景信息。常规数据库上的实验验证了本文方法的有效性。
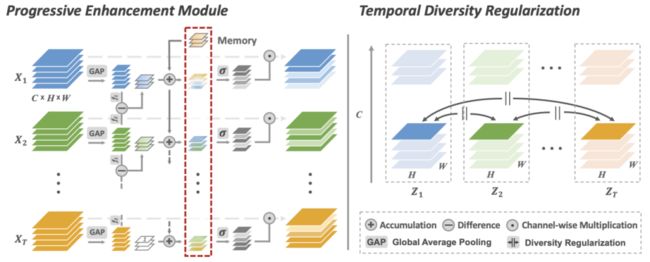
新提出的渐进式通道增强模型(PEM)和时序多样性损失函数(TD Loss)
如图所示,在 PEM 中,首先来自每一帧的特征图会先进行均值池化,然后降维成一维向量;接着连续两帧的一维向量会进行差值操作;红色虚线框中的记忆向量会渐进式地积累帧间差值信息;然后在Sigmoid函数的激励下,记忆向量将被映射为通道增强向量对原有每帧特征图进行通道增强。在 TD Loss 中,不同帧特征图的相同通道会被约束使彼此间不同,以此提升不同帧间表达的差异。
2. 用于时序动作分割的边界感知级联网络
Boundary-Aware Cascade Networks for Temporal Action Segmentation
本文由腾讯 AI Lab 和南京大学合作完成,提出了一种可用于时序动作分割的边界感知级联网络。
在含有很多动作实例的未修剪原始视频中识别出人类动作的片段目前为止依然很有挑战性,主要原因是动作边界的语义模糊以及分割结果过于细碎这两个问题。为了解决这些问题,本文提出了一个全新的动作边界感知的级联神经网络,它包含了两个新颖的模块。一是阶段级联(Stage Cascade),这种新的级联模式赋能模型以自适应的感受野和对语义模糊的视频帧更加有信心的预测的能力。二是局部屏障池化(local barrier pooling),这种通用的平滑操作是通过利用语义边界信息来更好的收集局部领域内的预测结果,从而实现预测的平滑。此外,模型的两个部分可以端到端地联合调优。
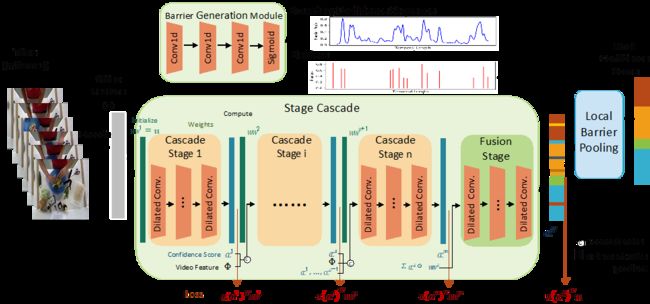
BCN动作分割流程图
BCN 是一种边界感知的级联时序分割网络,其首先采用 3DCNN 作为基准网络逐帧进行特征提取,然后再使用两个并行处理模块:级联分割模块和边缘检测模块。级联分割模块使用自适应的多阶段识别网络,对单帧图像进行识别,边缘检测模块对动作时序开始和结束节点进行检测。最后提出了一个边界感知的池化模块(LBP),将前面两个模块的结果进行有机融合,提升整体的动作分割效果。
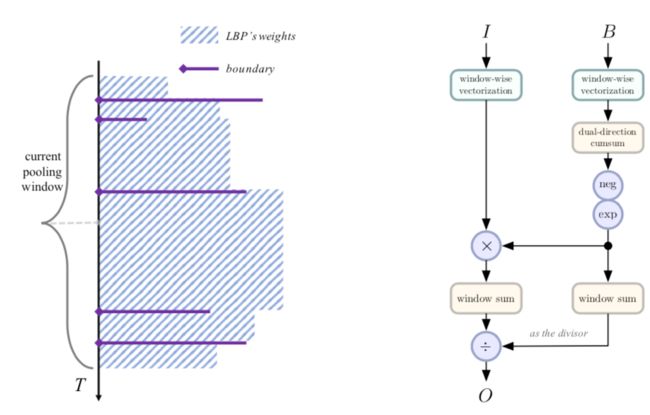
局部屏障池化模块(LBP)细节
研究者在 50Salads、GTEA 和 Breakfast这三个有挑战性的数据集上进行了实验,结果表明新提出的模型框架极大地超越了此前最好方法的效果。相关代码将会公布在https://github.com/MCG-NJU/BCN。
3. 将动作视为运动点
Actions as Moving Points
https://arxiv.org/abs/2001.04608
本文由南京大学与腾讯 AI Lab 合作完成,提出了一种新的短时序动作检测框架。
现有的短时时空动作检测框架通常基于锚点位置大小的启发式设计,对于人的定位来说,这种方式计算开销大并且精度只能达到次优。这篇论文提出了一个简单、高效且更加精确的短时序动作检测框架。该框架的设计核心是将动作实例视为运动点的轨迹,因此这个框架被称为移动中心点检测器(MOC-Detector)。
研究者认为位移信息可以简化和辅助短时序的动作检测,基于此观察,研究者设计了三个分支:(1)中心点分支:检测中心点位置并进行动作识别;(2)位移分支:估计运动者到周围帧的运动位移,形成运动者中心点的运动轨迹;(3)人物框分支:估计运动者在当前帧对应位置的框大小。这三个分支协作来生成短时序的动作检测结果,然后进一步根据匹配策略将这些短时序的检测结果在时间维度上连接起来生成视频级别的长时动作检测结果。
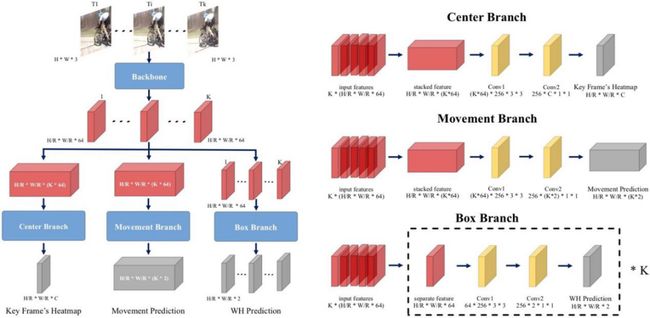
移动中心点(MOC)检测器整体架构与三个分支的结构
MOC 检测器采用全卷积检测流程,首先采用一个共享基准网络进行逐帧特征提取,然后设计三个检测头结构,分别进行中心点位置预测、空间偏移预测、空间框回归。
新提出的方法在 UCF101-24 和 JHMDB 上 frame-mAP和video-mAP都超过了现有最好的方法,在视频级别的高 IoU 的指标上更加明显,由此可以看出新提出的 MOC 对于高精度检测的尤其有效。
代码将在以下链接发布:
https://github.com/MCG-NJU/MOC-Detector
一种新卷积
卷积神经网络的发展可以说引领了当前人工智能技术的研发热潮并为计算机视觉带来了突破性的发展,但常规卷积存在一些固有缺陷,也因此研究者们在不断探索更有效且更高效的卷积设计。腾讯 AI Lab 的一篇 ECCV 2020 论文也提出了一种基于神经科学研究的新式卷积:语境门限卷积。
语境门限卷积
Context-Gated Convolution
https://arxiv.org/abs/1910.05577
本文由腾讯 AI Lab 主导,与哥伦比亚大学合作完成,提出了一种可考虑全局信息的新型卷积。
作为卷积神经网络的基础,卷积层从设计上便是为了提取局部特征,从而在设计上缺乏对于全剧语境信息的建模能力。近期,在赋予卷积层全局建模的能力的方向上涌现出了很多工作,特别有一大类是基于全局特征交互的方法。在这些全局特征交互的方法中,特征图在被送入下一个卷积层前会通过全局信息与局部特征进行交互的方式将全局语境信息融入到局部特征中。
根据神经科学方面的研究,神经元能够根据动态改变自己的功能,这个能力对于人类感知这个世界至关重要,然而这样的能力在目前的卷积层中是缺失的。基于此,本文创新地提出了语境门限卷积,从而直接依照全局信息的指引动态的调整卷积层的权重。经过动态调整的卷积层能够更好地捕捉到有代表性的局部模式,以及更好地提取具有分辨力的特征。
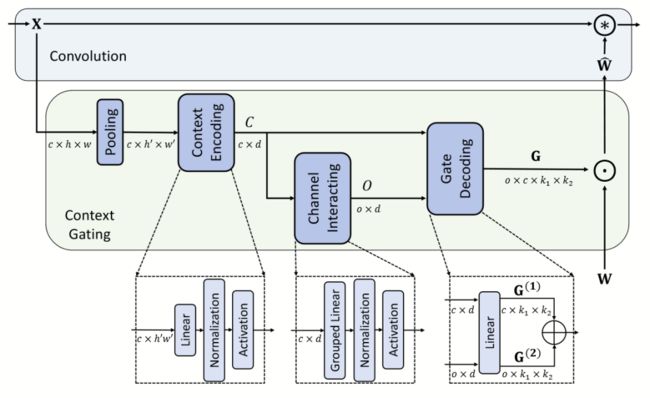
语境门限卷积示意图
如上图所示,语境门限卷积包含三个轻量化的模块,可利用全局信息对卷积核进行调控:语境编码模块将全局空间信息高效地编码进一个隐变量中;通道交互层负责不同通道之间地传递,并将输入维度投影至输出维度;门解码层将前面两个层输出的隐变量作为输入,从而解码出一个与卷积权重维度相同的张量,用于调整卷积核,使其能够更好地捕捉到重要的信息。
另外值得一提的是,新提出的语境门限卷积是一个轻量级的组件,可以很好地应用在现有的卷积神经网络中,在图像识别、视频理解、机器翻译上都可以显著提升现有模型性能。
其他两篇:人脸超分辨率与图像混合
腾讯 AI Lab 入选 ECCV 2020 的另外两篇论文分别探索了人脸超分辨率技术与用于样本插值的图像混合网络,其中人脸超分辨率技术论文将在 ECCV 2020 进行 Spotlight 展示。
1. 结合3D脸部结构先验的人脸超分辨算法
Face Super-Resolution Guided by 3D Facial Priors
https://arxiv.org/abs/2007.09454
本文为 ECCV 2020 Spotlight 论文,由腾讯 AI Lab 主导,与德国慕尼黑工业大学、中科院信息工程研究所与南京理工大学合作完成,提出了一种新的人脸超分辨算法。
现在最先进的人脸超分辨算法利用深度卷积网络去学习从低分辨到高分辨的人脸模式映射关系。但是大多数方法没有充分利用脸部结构及身份信息且很难处理脸部姿态变化。
本文提出了一种新的人脸超分辨算法,它能够显式地结合 3D 脸部先验,这种先验能够抓取到高清的脸部结构信息。研究者尝试去探究 3D 拓扑信息,这种信息是基于脸部属性多参数特征的融合(例如身份、表情、纹理、亮度和脸部姿态)。此外,这种先验能够嵌入任何网络,而且能十分有效地提高性能,加速收敛。实验结果表明,新提出的 3D 先验能够取得当前最佳的表现。
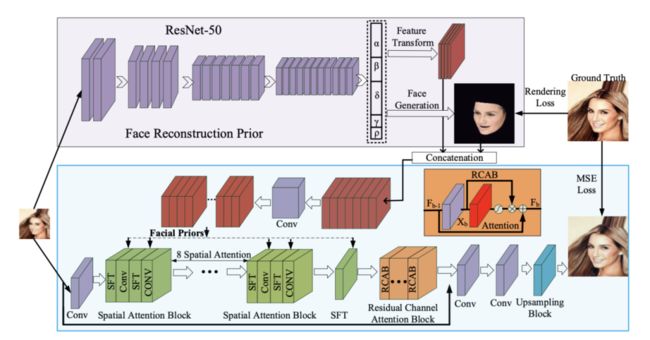
算法结构
如上图所示,新提出的人脸超分辨网络主要有两个分支,首先3D 渲染的分支来获取3D的高清晰度面部结构和身份信息。具体来说,通过训练一个ResNet-50 来回归 3D的脸部结构参数,再根据参数重建清晰脸部结构。其次,建立超分辨的空间注意力分支来更好地利用和结合层级信息(例如,密度相似性、3D脸部结构、身份信息)。超分辨的空间注意力机制主要是由三部分组成:空间注意力模块、残差注意力模块和上采样模块。
2. AutoMix:通过联合重心学习进行样本插值的图像混合网络
AutoMix: Mixup Networks for Sample Interpolation via Cooperative Barycenter Learning
本文由腾讯 AI Lab、华东师范大学、上海交通大学、香港中文大学以及深圳大数据研究院合作完成,提出了两种新型的图像重心生成方法。
深度神经网络的训练过程经常会遇到过拟合问题,针对此,除了对网络本身进行一些正则化操作以外,另一大有效解决方案是数据增强技术。本文从 Wasserstein 重心出发,基于重心学习理论,提出了两种新型的图像重心生成方法 OptTransMix 和 AutoMix,以此来进行数据增强,解决模型的过拟合问题,增强模型泛化能力。
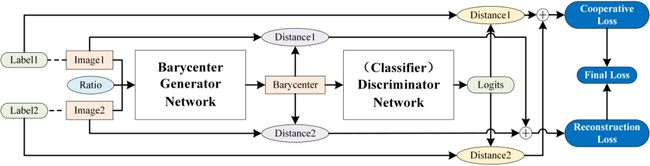
AutoMix 结构示意图,其由两个网络组成,即图像重心生成网络(Barycenter Generator Network)和分类器网络(Discriminatior Network),二者经过联合训练得到最优图像重心生成网络,用以将两张输入图片按照一定比例生成对应图像重心。
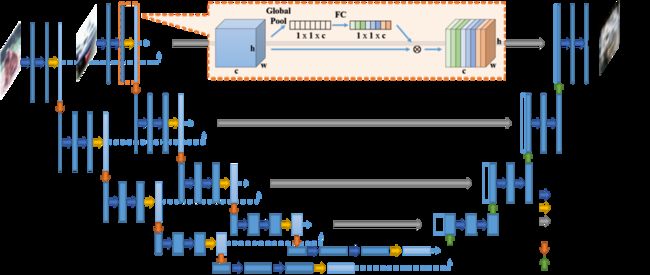
图像重心生成网络的网络结构参照了U-Net,但其输入被修改为两张图片,并引入了注意力机制,以更好地生成图像重心。
本文是首个将图像重心理论应用于图像插值,并通过增强数据以解决模型过拟合问题的研究,对该领域今后的研究具有开创性的指导意义。实验结果表明,该算法在单标签分类、多标签分类、对抗噪声的鲁棒性以及开集问题上都取得了 SOTA 的效果。

备注:paper

论文撰写与投稿交流群
扫码备注拉你入群。
我爱计算机视觉
微信号:aicvml
QQ群:805388940
微博知乎:@我爱计算机视觉
网站:www.52cv.net

在看,让更多人看到 