人脸识别 tracking.js学习
目录
一.定义
1.先定义window的属性,要用的全局对象
2.继承属性
2.初始化用户媒体
3.测试对象是否为DOM节点
4.测试对象是否为“window”对象
5.使用'document.queryselector'从css3选择器中选择一个dom节点
6.追踪器
7.追踪画布
8.追踪画布内部
9.追踪图像
10.追踪视频
二.各自方法
1.事件发射器实用程序
5.维奥拉·琼斯实用程序
12.TrackerTask实用程序
14.对象跟踪器实用程序
三.使用
四.问题
一.定义
1.先定义window的属性,要用的全局对象
![]()
2.继承属性
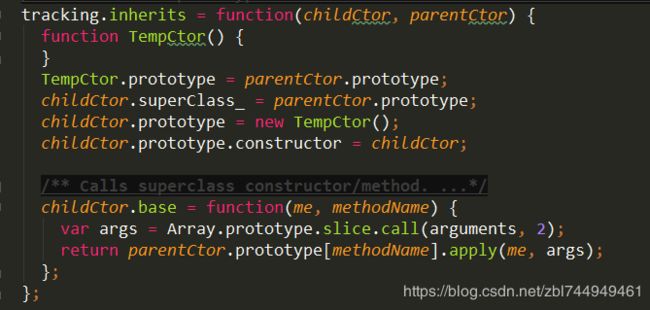
将原型方法从一个构造函数继承到另一个构造函数。
参数是子项、父项
定义过渡函数TempCtor()
TempCtor的原型=父项的原型
子项的superClass_=父项的原型
子项原型的构造器=子项
/调用超类构造函数/方法,此函数仅在使用tracking.inherits表示类之间的继承关系。/
子项的base属性=函数
函数传了2个参数,
如果调用时传入了超过2个函数,var args= 当参数超过两个之外的参数之外的参数组成的数组。
因为传入的参数本身不能组成一个数组,不能用数组的截取方式slice,所以用call把所有参数转化成数组,再从第三个参数开始截取,剩余的参数变成数组。https://www.cnblogs.com/dingxiaoyue/p/4948166.html
将父项的原型[方法]应用到me上,传递参数args。如果me上有这个方法,回被替换,没有就会被添加。
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/Function/apply
https://www.w3cschool.cn/wqf_web/wqf_web-x54328d9.html
返回这个方法的执行结果。
2.初始化用户媒体
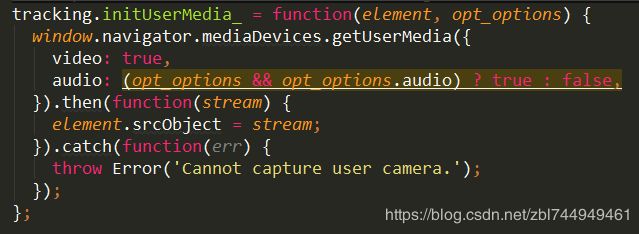
① 使用MediaDevices.getUserMedia()方法获取视频轨道和音频轨道(如果需要)
getusermedia()不再工作在不安全的根源。要使用此功能,您应该考虑将应用程序切换到安全源,如HTTPS。
https://developer.mozilla.org/zh-CN/docs/Web/API/MediaDevices/getUserMedia
这里如果设置了video的width和height,会怎样?
② 如果成功,将返回的视频流赋给用户绑定的element的srcObiect上。
这个对象提供了一个与HTMLMediaElement关联的媒体源,有兼容问题。
https://developer.mozilla.org/zh-CN/docs/Web/API/HTMLMediaElement/srcObject
③ 如果失败,会定义一个错误信息,Cannot capture user camera.(无法捕获用户摄像机)
http://www.w3school.com.cn/js/js_errors.asp
3.测试对象是否为DOM节点

如果是node节点,返回节点类型 http://www.w3school.com.cn/jsref/prop_node_nodetype.asp
如果节点是元素节点,则 nodeType 属性将返回 1。
如果节点是属性节点,则 nodeType 属性将返回 2。
否则,如果不是DOM节点,测试对象是否为“window”对象。
如果传入的是div怎么办,之后怎么追踪?
4.测试对象是否为“window”对象

例:b= !!(a)
a默认是undefined,!a是true,!!a则是false,
所以b的值是false,而不再是undefined。这样写可以方便后续判断使用。
所以,!!(a)的作用是将a强制转换为布尔型(boolean)。可用在判断a是否非空上。
当参数o存在,并且有alert属性 和 document属性 时返回 true,否则返回false。
5.使用'document.queryselector'从css3选择器中选择一个dom节点
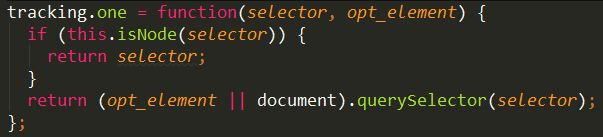
如果selector是dom节点或者window对象,返回selector。
否则返回匹配到的第一个元素。
querySelector() 方法返回文档中匹配指定 CSS 选择器的一个元素。如果没匹配到,返回null
https://developer.mozilla.org/zh-CN/docs/Web/API/Document/querySelector
querySelector() 方法是document独有的吗?
opt_element如果不传就是document,如果传别的会有问题?
6.追踪器
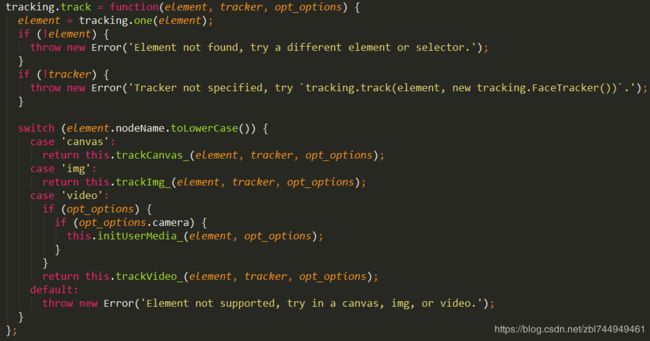
① 传入参数,找到追踪的元素,绑定定义的追踪器,参数。
例:
![]()
![]()
② element=找到的第一个dom对象
③ 判断 如果element和tracker不存在,定义错误。
④ 判断元素的节点名小写 选择一种追踪方式。
如果是画布,返回追踪画布 ![]()
如果是图像,返回追踪图像![]()
如果是视频,如果参数里有camera:true,请求打开摄像头 ![]()
返回![]()
如果都不是,定义错误。
7.追踪画布
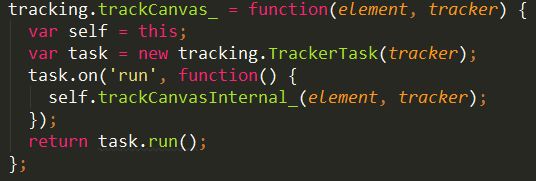
基于指定的“tracker”实例跟踪画布元素,并返回此tracker的“trackertask”。
传入2个参数element, tracker
声明一个变量 self,将其初始化为this
声明变量task = 初始化实例 tracking.TrackerTask(tracker);
8.追踪画布内部
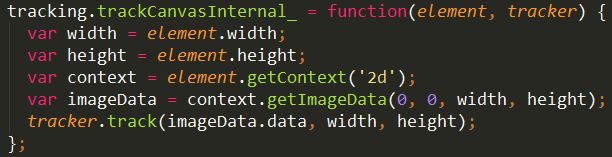
基于指定的“tracker”实例跟踪画布元素。这个方法提取输入元素的像素信息传递给` tracker`实例。
这里的参数tracker是 tracking.ObjectTracker
getImageData方法是 复制画布上指定矩形的像素数据。http://www.w3school.com.cn/tags/canvas_getimagedata.asp
打印完如图
追踪图像信息。这里就一直追踪,直到找到人脸。
9.追踪图像
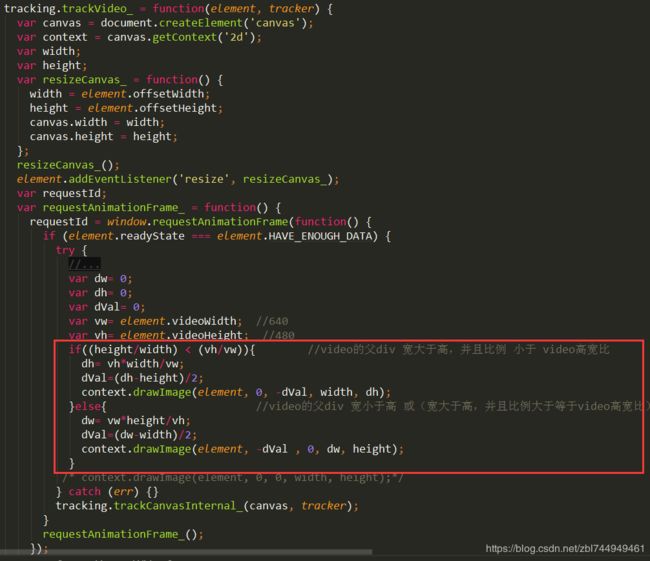
10.追踪视频
① 创建画布
② 定义画布的宽高,加监听事件,当屏幕变化时,会重新定义。
offsetWidth实际获取的是盒模型(width+border + padding)
③ 声明变量 requestId
声明变量 requestAnimationFrame_ 这是一个递归函数
如果当前video加载就绪,在画布上画图。调用tracking的trackCanvasInternal_属性。
再执行一遍这个方法requestAnimationFrame_() 。
递归了,如果没有停止,会一直执行下去。
readyState属性获得视频的就绪状态 http://www.w3school.com.cn/tags/av_prop_readystate.asp

声明变量task= 初始化实例 tracking.TrackerTask(tracker);
二.各自方法
1.事件发射器实用程序
![]()
① 定义属性EventEmitter=函数
![]()
② 保留按事件类型划分范围的事件侦听器。
初始为空
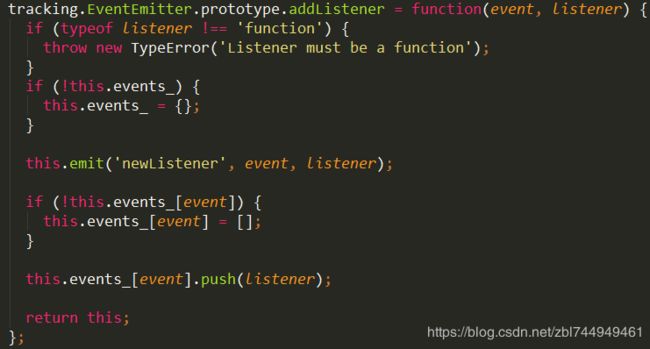
③ 将侦听器添加到指定事件的侦听器数组的末尾。
如果listener不是函数,定义错误 侦听器必须是函数
如果events_是空,events_=空对象
提交
5.维奥拉·琼斯实用程序
![]()
① 定义属性
![]()
② 保留定义矩形何时为来自同一组。通常,当一个面匹配时,多个矩形分类为可能的矩形以表示面,当它们相交,它们被分组为一个面。
区域重叠=0.5
![]()
③ 持有从OpenCV训练转换的HAAR级联分类器。
④ 通过haar cascade数据矩形匹配进行检测。
⑤ 快速检查试块内边缘密度是否较大,如果为真,则测试阶段。这可以显著提高性能。
⑥ 计算i,j位置上的块大小是否是有效的haar cascade阶段。检测到人脸,这块就用到了。
⑦⑧⑨
12.TrackerTask实用程序
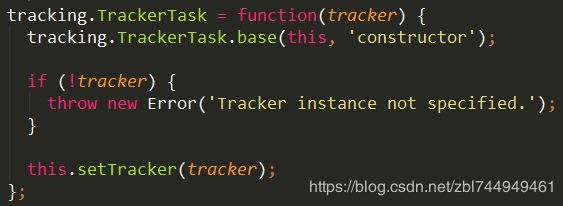
① tracking的TrackerTask属性= 函数,传入参数 tracker
这里的base是在执行完继承后执行的。
如果没获取到参数,就定义新错误,未指定跟踪程序实例。
执行setTracker函数
![]()
② 将 tracking.EventEmitter的属性都继承
![]()
③ 原型链上得到tracker_默认为空
![]()
④ 初始状态默认不执行

⑤ 获取此任务管理的跟踪程序实例

⑥ 如果跟踪任务正在运行,则返回true,否则返回false

⑦ 设置跟踪程序任务是否正在运行。

⑧ 设置此任务管理的跟踪程序实例。
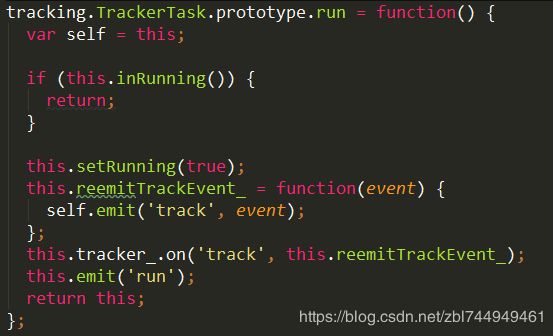
⑨ 在跟踪器任务上发出“run”事件,以便实现人员运行子操作,例如“requestAnimationFrame”。
如果正在跟踪,返回。
否则设置跟踪状态为真
设置属性reemitTrackEvent_=函数
设定追踪event
在tracker_上绑定事件track,实时追踪
提交run事件
返回this
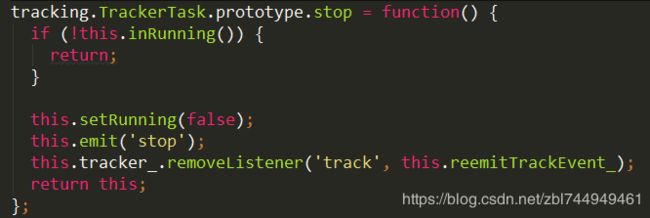
⑩ 在跟踪器任务上发出“stop”事件,以便实现人员停止任何正在执行的子操作,例如“requestAnimationFrame”。
移除追踪事件。
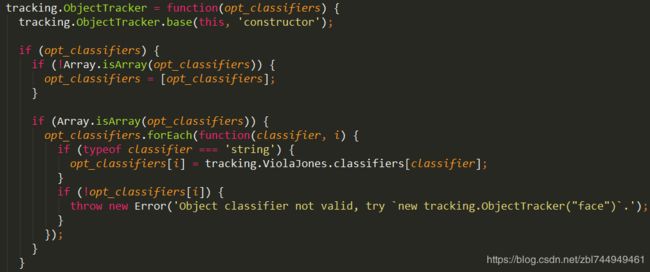
14.对象跟踪器实用程序
三.使用
1.先说说优缺点
(1). 之前用过神目opencv的人脸识别,但是代码文件太大,网络不好加载慢,影响使用。
而且,虽然视频可以适应父项大小,但效果是object-fit: fill;
完全填充,造成随父项长宽不定,显示的人脸被拉伸或压缩,不是百分百保真。
(2). tracking的video不会适应父项拉伸,一直保持比例4:3 ,空的地方会被填充。
tracking最好识别效果:
video的宽高比例是320*240
参数:EdgesDensity(0.1)设置边缘密度 InitialScale(4) 设定初始比例 StepSize(1.1) 设置步长
为了适应父项大小,我开始在源码里做了处理,并给video加上 object-fit: cover,这是为了展示效果,用了替换内容。
但tracking对大的像素分辨率识别并不好,很难识别到一次。所以,这种方法舍弃了。
(3). 用了另一种思路,在识别率最高的比例,先识别出人脸,再将效果放大展示。这样解决了识别率低的问题,也可以百分百保真,不会有opencv的将人脸拉长压缩等问题。但也有缺陷,因为是先识别,再放大展现,清晰度会有点降低,如果不要求超清的,也可以接受。
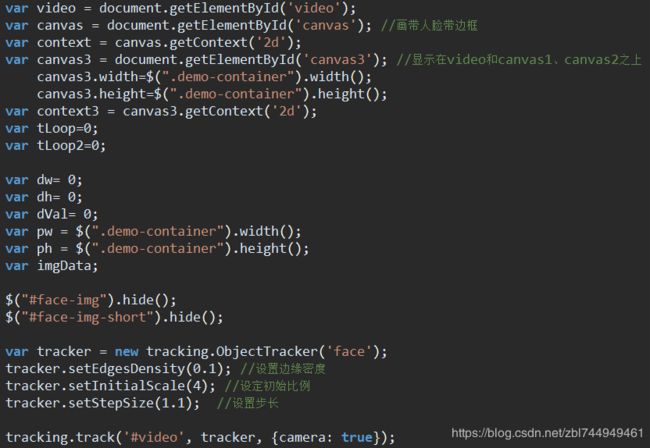
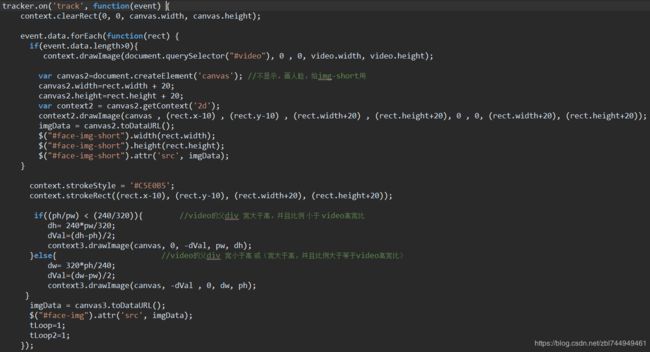
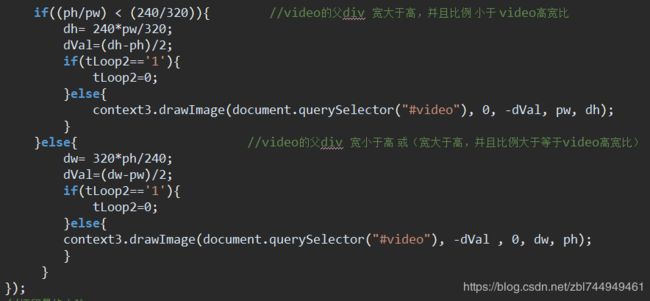
(4). 实现方法:
流程图
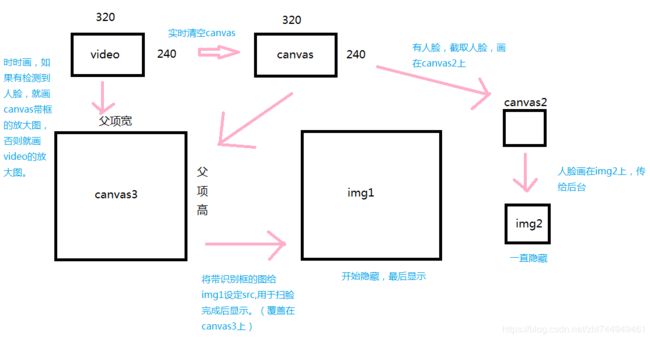
有个320*240的video,
有个320*240的canvas,时时清空canvas的内容,
有个canvas3时时展示放大后的扫描完的video,也把带框的图给img1,
有个最后展示的img1,大小等于父项的大小,
有个传给后台识别的img2,
在识别出人脸时,canvas上画出video此时的图像,
新建个canvas2,width=识别出人脸的宽,height=识别出人脸的高
canvas2从canvas上截取出人脸 context2.drawImage
canvas2.toDataURL()
设置img2的宽高=人脸的宽高
设置img2的src 为 canvas2.toDataURL()
然后,在canvas上画出识别框,
在canvas3上画出放大的canvas,给最后展示的img1用。
设置img1的src等于canvas3上的带识别框图。
判断,如果识别出人脸,把参数归0方便下次识别。否则,canvas3画video的放大图
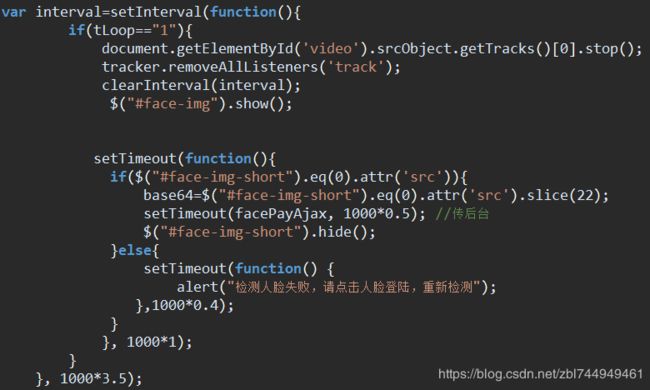
设置定时器,在限定时间内如果扫到人脸,就停止设别video,移除人脸跟踪监听 ,停止定时器。
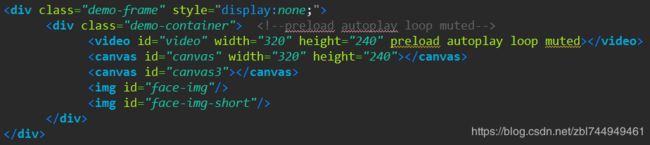
html:
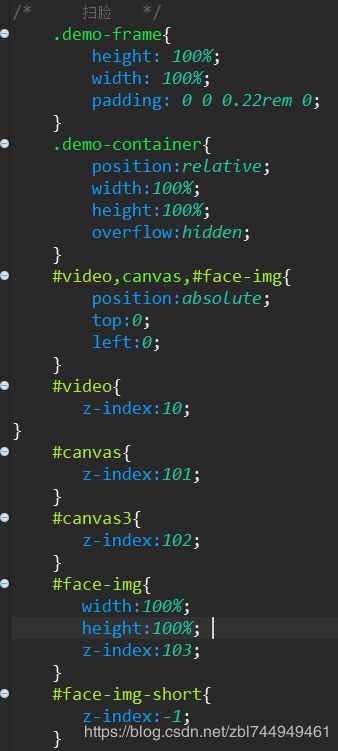
css:
js:
四.问题
这里的.on()和.emit()是哪里定义的,
是node 中的 EventEmitter 类提供了监听事件的方法 on(event, listener) 和 触发事件的方法 emit(event, [arg1], [arg2], […])吗?