部分北邮往年机试题汇总
文章目录
- 字符串
- IP 地址
- 题目描述
- 输入格式
- 输入样例
- 输出样例
- 方法一. split
- 反转单词
- IP数据包解析
- 题目描述
- 输入格式
- 输出格式
- 输出样例
- 参考
- 数据解析
- AC代码
- 树状结构
- 中序遍历树
- 题目描述
- 输入格式
- 输出格式
- 输入样例
- 输出样例
- AC代码
- 文件系统
- 题目描述
- 输入格式
- 输出格式
- 输入样例
- 输出样例
- AC代码
- 贪心
- 最远距离
- 题目描述
- 输出格式
- 输入样例
- 输出样例
- 动态规划
- 最小距离查询
- 题目描述
- 输入格式
- 输出格式
- 输入样例
- 输出样例
- 堪比DP的set大法
- 动态规划
- 其他
- 非平方不等式
- 输入格式
- 输入样例
- 输出样例
- 缩小搜索范围,AC代码
- 虚数
- 题目描述
- 输入格式
- 输出格式
- 输入样例
- 输出样例
- 代码
- single numble
- 题目描述
- 输入格式
- 输入样例
- 输出样例
- map大法
- 位运算巨法
字符串
IP 地址
https://.bupt.edu.cn/http/10.105.242.80/problem/p/101/
题目描述
我们都学过计算机网络,了解IPV4地址的点分十进制表示法。
你的任务很简单:判断一个字符串是否是一个合法的点分十进制表示的IPV4地址。
最低的IP地址是0.0.0.0,最高的IP地址是255.255.255.255。
PS :方便起见,认为形似00.00.00.00的IP地址也是合法的。
输入格式
第一行是一个整数T,代表输入还剩下T行
以下的T行,每行都是一个字符串(不含空白字符)。字符串的长度保证不超过15,不小于1.
输出格式
对于每个字符串,输出一行。
如果它是一个合法的IPV4地址,输出Yes。
否则,输出No。
输入样例
3
59.64.130.18
f.a.t.e
1.23.45.678
输出样例
Yes
No
No
方法一. split


我编写了一个专用的split函数。但是要特判123.123.123.123.这样的情况
#include
#define F(a,b) for(int a=1;a<=b;a++)
#define LEN 100
#define INF 1000000
#define bug(x) cout<<#x<<"="<
using namespace std;
typedef long long ll;
void split(string s,char splitchar,vector<string>& vec)
{
int L = s.length();
int start=0;
string topush;
for(int i=0; i<L; i++)
{
if(s[i] == splitchar && i == 0)//第一个就遇到分割符
{
start += 1;
}
else if(s[i] == splitchar)
{
topush=s.substr(start,i - start);
if(topush.length()>0)
vec.push_back(topush);
start = i+1;
}
else if(i == L-1)//到达尾部
{
topush=s.substr(start,i+1 - start);
if(topush.length()>0)
vec.push_back(topush);
}
}
}
bool isDigit(string str){
if(str.length()==0) return 0;
FF(i,str.length()){
if(str[i]>'9' || str[i]<'0')
return 0;
}
return 1;
}
bool valid(string str){
int num;
sscanf(str.c_str(),"%d",&num);
if(num<0 || num>255)
return 0;
return 1;
}
int main()
{
// freopen("./in","r",stdin);
int T;
scanf("%d",&T);
char buf[1000];
getchar();
while(T--){
gets(buf);
vector<string> v;
split(string(buf),'.',v);
bool Yes=0;
if(v.size()==4 && buf[strlen(buf)-1]!='.'){
Yes=1;
FF(i,4){
if((!isDigit(v[i])) || (!valid(v[i]) )){
Yes=0;
break;
}
}
}
puts(Yes?"Yes":"No");
}
return 0;
}
反转单词
https://.bupt.edu.cn/http/10.105.242.80/problem/p/103/
对于这种题要引起重视了
#include
#define F(a,b) for(int a=1;a<=b;a++)
#define LEN 100
#define INF 1000000
#define bug(x) cout<<#x<<"="<
using namespace std;
typedef long long ll;
const double pi=acos(-1);
char buf[1010];
int main()
{
// freopen("./in","r",stdin);
ios::sync_with_stdio(false);//这东西开了,stdio的东西都别想用了
string s;
vector<string> v;
while(cin>>s){
v.clear();
v.push_back(s);
while(1){
// char c=getchar();
char c=cin.get();//老老实实用这个,上一行读出来的都是EOF
if(c=='\n' || c==EOF)
break;
cin>>s;
v.push_back(s);
}
reverse(v.begin(),v.end());
FF(i,v.size()){
cout<<v[i];
if(i!=v.size()-1)
cout<<' ';
}
cout<<endl;
}
return 0;
}
IP数据包解析
https://.bupt.edu.cn/http/10.105.242.80/problem/p/98/
题目描述
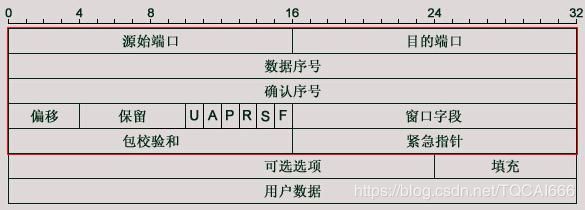
我们都学习过计算机网络,知道网络层IP协议数据包的头部格式如下:
其中IHL表示IP头的长度,单位是4字节;总长表示整个数据包的长度,单位是1字节。
传输层的TCP协议数据段的头部格式如下:
头部长度单位为4字节。
你的任务是,简要分析输入数据中的若干个TCP数据段的头部。 详细要求请见输入输出部分的说明。
输入格式
第一行为一个整数T,代表测试数据的组数。
以下有T行,每行都是一个TCP数据包的头部分,字节用16进制表示,以空格隔开。数据保证字节之间仅有一个空格,且行首行尾没有多余的空白字符。
保证输入数据都是合法的。
输出格式
对于每个TCP数据包,输出如下信息:
Case #x,x是当前测试数据的序号,从1开始。
Total length = L bytes,L是整个IP数据包的长度,单位是1字节。
Source = xxx.xxx.xxx.xxx,用点分十进制输出源IP地址。输入数据中不存在IPV6数据分组。
Destination = xxx.xxx.xxx.xxx,用点分十进制输出源IP地址。输入数据中不存在IPV6数据分组。
Source Port = sp,sp是源端口号。
Destination Port = dp,dp是目标端口号。
对于每个TCP数据包,最后输出一个多余的空白行。
具体格式参见样例。
请注意,输出的信息中,所有的空格、大小写、点符号、换行均要与样例格式保持一致,并且不要在任何数字前输出多余的前导0,也不要输出任何不必要的空白字符。
输入样例
2
45 00 00 34 7a 67 40 00 40 06 63 5a 0a cd 0a f4 7d 38 ca 09 cd f6 00 50 b4 d7 ae 1c 9b cf f2 40 80 10 ff 3d fd d0 00 00 01 01 08 0a 32 53 7d fb 5e 49 4e c8
45 00 00 c6 56 5a 40 00 34 06 e0 45 cb d0 2e 01 0a cd 0a f4 00 50 ce 61 e1 e9 b9 ee 47 c7 37 34 80 18 00 b5 81 8f 00 00 01 01 08 0a 88 24 fa c6 32 63 cd 8d
输出样例
Case #1
Total length = 52 bytes
Source = 10.205.10.244
Destination = 125.56.202.9
Source Port = 52726
Destination Port = 80
Case #2
Total length = 198 bytes
Source = 203.208.46.1
Destination = 10.205.10.244
Source Port = 80
Destination Port = 52833
参考
-
IP头部

-
TCP头部
数据解析
45 00 00 34 //0034表示总长度, 即52B, 5表示首部长度, 5*4B
7a 67 40 00
40 06 63 5a
0a cd 0a f4 //源地址 10.205.10.244
7d 38 ca 09 //目的地址 125.56.202.9
cd f6 00 50 //源端口, 目的端口
b4 d7 ae 1c
9b cf f2 40
80 10 ff 3d
fd d0 00 00
Case #1
Total length = 52 bytes
Source = 10.205.10.244
Destination = 125.56.202.9
Source Port = 52726
Destination Port = 80
AC代码
有点意思, 码量较大
需要训练做模拟题的速度
#include
#define F(a,b) for(int a=1;a<=b;a++)
#define LEN 100
#define INF 1000000
#define bug(x) cout<<#x<<"="<
using namespace std;
typedef long long ll;
char buf[1000];
char str[100][10];
int hex2int(char ch){
if(ch>='a'){
return ch-'a'+10;
}else{
return ch-'0';
}
}
int hex2int(char *ch){
int n=strlen(ch);
int ans=0;
int base=1;
for(int i=n-1,j=0
;i>=0;
i--,j++) //脑子秀逗了, 其实写个单循环就好了
{
ans+=hex2int(ch[i])*base;
base*=16;
}
return ans;
}
int main()
{
// freopen("./in","r",stdin);
int N;
scanf("%d",&N);
FF(i,N){
//gets(buf); 可以用gets读入带空格的一行
int n=0;
while(1){
scanf("%s",str[n++]);
char pd=getchar();
if(pd=='\n' || pd==EOF)
break;
}
int IPlen=hex2int(str[0][1]);
strcat(str[2],str[3]);
int TOTlen=hex2int(str[2]);
printf("Case #%d\n",i+1);
printf("Total length = %d bytes\n",TOTlen);
printf("Source = %d.%d.%d.%d\n",hex2int(str[12]),hex2int(str[13]),hex2int(str[14]),hex2int(str[15]));
printf("Destination = %d.%d.%d.%d\n",hex2int(str[16]),hex2int(str[17]),hex2int(str[18]),hex2int(str[19]));
strcat(str[IPlen*4],str[IPlen*4+1]);
strcat(str[IPlen*4+2],str[IPlen*4+3]);
printf("Source Port = %d\n",hex2int(str[IPlen*4]));
printf("Destination Port = %d\n",hex2int(str[IPlen*4+2]));
puts("");
}
return 0;
}
//Case #1
//Total length = 52 bytes
//Source = 10.205.10.244
//Destination = 125.56.202.9
//Source Port = 52726
//Destination Port = 80
树状结构
中序遍历树
题目描述
给一棵树,你可以把其中任意一个节点作为根节点。每个节点都有一个小写字母,中序遍历,得到一个字符串,求所有能得到的字符串的字典序最小串。因为这棵树不一定是二叉树,所以中序遍历时,先中序遍历以节点序号最小的节点为根的子树,然后再遍历根节点,最后根据节点序号从小到大依次中序遍历剩下的子树。
- HINT
意思就是请枚举所有的点为根,然后中序遍历
最后输出所有结果中字典序最小的
比如说第二组数据
以0为根时结果为 bacd
以1为根时结果为 cadb
以2为根时结果为 badc
以3为根时结果为 bacd
所以字典序最小的是bacd
输入格式
多组数据,以EOF结束。
第一行一个数n(0 然后一个长度为n的串,第i(0<=i 题中要求的最小的字符串 3 bac https://.bupt.edu.cn/http/10.105.242.80/problem/p/109/ 看起来很简单,但是遇到了以下坑。 写了半天连样例都过不了… …要引起重视了 https://.bupt.edu.cn/http/10.105.242.80/problem/p/91/ 现在很多操作系统的文件系统都是基于树形结构设计的。即一个目录下可以有若干个目录和文件,而每个目录和文件都可以通过一条从根目录出发的唯一路径来唯一确定。我们希望你实现对这样的一个文件系统的简单管理。 第一行有一个整数T,表示一共有T(T≤20)组数据需要你处理。请注意各组数据之间是相互独立的。每当处理新的一组数据时,你都应当假设此时只有一个名字为root的根目录存在。 对于每个LISTFILE操作和LISTDIR操作,如果找到了X个文件(或目录),你需要输出X行,按照创建时间从早到晚的顺序,每一行打印一个文件(或目录)的名字。如果找到了0个文件(或目录),就不要输出任何东西。请注意不要输出多余的空格和换行符。 2 desktop 参考:https://blog.csdn.net/u012662688/article/details/50898476 正义的伙伴褋祈和葬仪社的机器人Fuyuneru正在被邪恶的GHQ部队追杀。眼看着快要逃不掉了,祈就把重要的东西塞到了机器人体内,让它先跑,自己吸引火力。 假设Fuyuneru带上东西开始逃跑时所处的点为原点,朝向为正北。操纵FuyuNeru的指令有如下四种: right X: X是1-359之间的整数,Fuyuneru的前进方向顺时针转X度。 left X: X是1-359之间的整数,Fuyuneru的前进方向逆时针转X度。 forward X: X是整数(0<=X<=1000),Fuyuneru向当前朝向前进X米。 backward X: X是整数(0<=X<=1000),Fuyuneru向当前朝向后退X米。 现在祈向Fuyuneru体内输入了N(1<=N<=50)个这样的指令。可是由于此前Fuyuneru被GHQ部队击中,它出了一点小问题:这N个指令执行的顺序是不确定的。 问:Fuyuneru最远可能逃出多远? 即,Fuyuneru在执行完N条指令之后,距离原点最远的可能距离是多少? 第一行是一个整数T,代表测试数据有T组。 每组测试数据中,第一行是一个整数N,代表指令有N条; 随后紧跟N行,每一行代表一个指令(格式保证是上述四种中的一种,数据保证合法) 对于每组数据,输出一行:最远的可能逃亡距离,精确到小数点后3位。 3 141.421 给定一个由小写字母a到z组成的字符串S,其中第i个字符为S[i](下标从0开始)。你需要完成下面两个操作: HINT 由于输入数据较大,C/C++中推荐使用scanf进行读入以获得更快的读入速度。同时请注意算法复杂度。 输入的第一行是一个正整数T(T≤20),表示测试数据的组数。 对于每个QUERY,输出所求的最小距离。如果S中其它位置都不存在和它相同的字符,输出-1。 2 3 https://.bupt.edu.cn/http/10.105.242.80/problem/p/94/ 其实DP也简单. 欧阳巨佬代码: 考虑等式: 其中x,n是正整数,s(x)是个函数,其值等于x在十进制下所有数字的和。 现给出整数n的大小,请你求出最小的满足条件的正整数x。 输入仅包含一个整数n (1 ≤ n ≤ 1018) . 如果不存在这样的x,请输出-1;否则请输出满足条件的最小的整数x (x > 0) 2 1 https://.bupt.edu.cn/http/10.105.242.80/problem/p/108/ 给你一个复数集合{Aj+i*Bj},保证Aj和Bj都是整数,初始为空集。 每次会给你如下两种操作中的一种: “Insert x+iy”,其中x,y都是整数。表示在集合中加入一个复数 x+iy,同时输出此时集合的大小; “Pop”。如果集合为空集直接返回“Empty!”,如果有元素则以"x+iy"的形式显示集合中模值最大的复数,然后将该元素从集合中删除,之后在第二行显示操作之后的集合大小,如果为空集则显示“Empty!”。 第一行只有一个数T,代表case数。0<=T<=10 每一组case: 第一行有一个整数n,表示这组case中一共有n条命令 0 接下来n行每行有一个命令,命令如上所述 保证不会输入两个模值同样的元素,并保证实部虚部都大于0,小于1000。 依照上述原则输出每一个命令对应的输出 如果输入命令是Insert命令,则对应的输出占一行为集合大小; 如果输入命令是Pop命令,则对应的输出占一行或者两行,为模值最大的复数和集合大小。 请注意,输出集合大小的格式为"Size:空格x回车",x为集合大小 1 Empty! 看到本题要立刻想到用优先队列 Given an array with N integers where all elements appear three times except for one. Find out the one which appears only once. Several test cases are given, terminated by EOF. Each test case consists of two lines. The first line gives the length of array N(1≤N≤105), and the other line describes the N elements. All elements are ranged in [0,263−1]. Output the answer for each test case, one per line. 4 3 https://.bupt.edu.cn/http/10.105.242.80/problem/p/84/ https://blog.csdn.net/birdstorm_s/article/details/19967311 两方法比较输出格式
输入样例
bac
0 1
1 2
4
abcd
0 1
0 2
0 3输出样例
bacd
不难的一题,但写了贼久。。。
题设中序遍历步骤:
1个子节点)2...N子节点)
(A)(B)进行循环,而不能简单的访问g[r][0](C)AC代码
#include 文件系统
题目描述
为了简化问题,我们做出如下假设:
假设文件系统初始时只有一个根目录root。
假设所有出现的文件和目录的名字都是唯一的。即,不会有两个相同名字的文件出现,不会有两个相同名字的目录出现,也不会有一个文件和一个目录名字相同。
文件名字和目录名字都是长度在1到20之间的字符串(包括1和20),且只由英文大写字母、英文小写字母、数字组成。大小写字母之间不等效。
你需要实现如下操作:
CREATEFILE FILENAME DIRNAME
这个操作的含义是:在DIRNAME的目录下创建一个名字为FILENAME的文件。我们保证当出现这个操作时,DIRNAME是一个已经存在的目录,而FILENAME这个名字是首次出现。
CREATEDIR DIRNAME1 DIRNAME2 这个操作的含义是:在DIRNAME2的目录下创建一个名字为DIRNAME1的目录。我们保证当出现这个操作时,DIRNAME2是一个已经存在的目录,而DIRNAME1这个名字是首次出现。
LISTFILE DIRNAME 这个操作的含义是:按照创建的先后顺序打印出DIRNAME目录下的所有文件名字。我们保证当出现这个操作时,DIRNAME是一个已经存在的目录.
LISTDIR DIRNAME 这个操作的含义是:按照创建的先后顺序打印出DIRNAME目录下的所有目录名字。我们保证当出现这个操作时,DIRNAME是一个已经存在的目录输入格式
对于每组数据,第一行有一个整数N(0< N≤100),表示有N个操作需要你处理,接下来的N行,每一个行描述了一个操作。输出格式
输入样例
8
CREATEFILE desktop root
CREATEDIR DESKTOP root
LISTFILE root
LISTDIR DESKTOP
CREATEFILE scr20130412 DESKTOP
CREATEFILE scr20130411 DESKTOP
CREATEFILE scr20130413 DESKTOP
LISTFILE DESKTOP
5
LISTFILE root
CREATEDIR webapp root
CREATEDIR myweb webapp
CREATEDIR MyWeb webapp
LISTDIR webapp输出样例
scr20130412
scr20130411
scr20130413
myweb
MyWebAC代码
/*
USER_ID: test#shizhuxiniubi
PROBLEM: 91
SUBMISSION_TIME: 2019-01-26 09:15:04
*/
#include 贪心
最远距离
题目描述
输入格式输出格式
输入样例
3
forward 100
backward 100
left 90
4
left 45
forward 100
right 45
forward 100
6
left 10
forward 40
right 30
left 10
backward 4
forward 4输出样例
200.000
40.585#include 动态规划
最小距离查询
题目描述
INSERT c
其中c是一个待输入的字符。你需要在字符串的末尾添加这个字符。保证输入的字符同样是a到z之间的一个小写字母。
QUERY x
其中x是一个输入的整数下标。对于这个询问,你需要回答在S当中和S[x]相等且与x最近的距离。输入保证x在当前字符串中合法。
例如S = “abcaba”,如果我们操作:
INSERT a
则在S的末端加一个字符a,S变成"abcabaa"。
接下来操作
QUERY 0
由于S[0] = a,在S中出现的离他最近的a在下标为3的位置上,距离为3 - 0 = 3。因此应当输出3。
接下来,如果
QUERY 4
S[4] = b,S中离它最近的b出现在下标为1处,距离为4 - 1 = 3。同样应当输出3。
给定初始字符串S和若干操作,对于每个QUERY,你需要求出相应的距离。输入格式
每组输入数据的第一行是一个初始串S。第二行是一个正整数m(1≤m≤100000),表示总共操作的数量。接下来m行,每行表示一个操作。操作的格式如上所述。
数据保证在任何情况下,S的长度不会超过100000。输出格式
输入样例
axb
3
INSERT a
QUERY 0
QUERY 1
explore
3
INSERT r
QUERY 7
QUERY 1输出样例
-1
2
-1
用set大法写了一堆自己都看不懂的代码, 一提交居然AC了, 一发入魂堪比DP的set大法
#include 动态规划
对于录入的数据, 从左到有做如下状态转移:
pre[k] = i; //仅仅做更新
j=pre[k] //记录上次位置
pre[k] = i; //做更新
f[i]=i-j; //因为i是最近(右)出现的, 必然距离左边的那个字母最近
f[j]=min(f[j],f[i]) //而左边的, 需要状态转移
/*省略了头文件和预定义,不能运行,看看逻辑就行*/
int T;
char s[N], ss[N];
int q;
char c;
int n;
int f[N];
int pre[N];
void wk(int i) {
f[i] = inf;
int k=s[i] - 'a';
int j = pre[k];
if (!pre[k])
pre[k] = i;
else {
f[i] = i - j;
pre[k] = i;
f[j]=min(f[j],i-j);
}
}
void wk2(int i) { //这个是我阅读巨佬代码后做的优化, 减少代码量, 逻辑与wk等效
f[i] = inf;
int k=s[i] - 'a';
int j = pre[k];
if(pre[k]) {
f[i] = i - j;
f[j]=min(f[j],i-j);
}
pre[k] = i;
}
signed main()
{
freopen("in","r",stdin);
sdf(T);
while (T--) {
scanf("%s", s + 1);
n = strlen(s + 1);
sdf(q);
For(i, 0, 25)pre[i] = 0;
For(i, 1, n) {
wk(i);
}
while (q--) {
scanf("%s", ss + 1);
if (ss[1] == 'I') {
scanf(" %c", &c);
s[++n] = c;
wk(n);
} else {
int x;
sdf(x);
x++;
if (f[x] == inf)printf("-1\n");
else printf("%lld\n", f[x]);
}
}
}
}
其他
非平方不等式
x^2 + s(x)·x - n = 0,输入格式
输出格式输入样例
输出样例
缩小搜索范围,AC代码
#include 虚数
题目描述
输入格式
输出格式
输入样例
5
Pop
Insert 1+i2
Insert 2+i3
Pop
Pop输出样例
Size: 1
Size: 2
2+i3
Size: 1
1+i2
Empty!代码
牢记优先队列的运算符重载/*
USER_ID: test#shizhuxiniubi
PROBLEM: 108
SUBMISSION_TIME: 2019-02-03 11:34:38
*/
#include single numble
题目描述
输入格式
输出格式输入样例
1 1 1 3
10
1 2 3 1 2 3 1 2 3 4输出样例
4
wa到怀疑人生, 原来是要64位整数

map大法
#include 位运算巨法
#include