SparkCore快速入门系列(5)

铁铁们,博主前段时间在做一些项目加上找工作所以到现在才更新,(__) 嘻嘻……
博主现在已经工作啦,后期会给你们更新一些关于数据库以及报表开发的文章哦!
接下来言归正传!!!!!!

文章目录
- 第一章 RDD详解
- 1.1 什么是RDD
- 1.1.1 为什么要有RDD?
- 1.1.2 RDD是什么?
- 1.2. RDD的主要属性
- 第二章 RDD-API
- 2.1. 创建RDD
- 2.2. RDD的方法/算子分类
- 2.2.1分类
- 2.2.2 Transformation转换算子
- 2.2.3 Action动作算子
- 2.3. 基础练习[快速演示]
- 2.3.1. 准备工作
- 2.3.2. WordCount
- 2.3.3. 创建RDD
- 2.3.4. 查看该RDD的分区数量
- 2.3.5. 不同转换算子的意义以及应用
- 第三章 RDD的持久化/缓存
- 3.1 引入
- 3.2 持久化/缓存API详解
- 3.3 代码演示
- 3.4 总结
- 第四章 RDD容错机制Checkpoint
- 4.1 引入
- 4.2 代码演示
- 4.3. 总结
- 第五章 RDD依赖关系
- 5.1. 宽窄依赖
- 5.2. 为什么要设计宽窄依赖
- 第六章 DAG的生成和划分Stage
- 6.1. DAG介绍
- 6.2. DAG划分Stage
- 第七章 Spark原理初探
- 7.1. 基本概念
- 7.2. 基本流程
- 7.3. 流程图解
- 7.4. 总结
- 第八章 RDD累加器和广播变量
- 8.1. 累加器
- 8.1.1. 不使用累加器
- 8.1.2. 使用累加器
- 8.1.3. 代码演示
- 8.2. 广播变量
- 8.2.1. 不使用广播变量
- 8.2.2. 使用广播变量
- 8.2.3. 代码演示
- 第九章 RDD数据源
- 9.1. 普通文本文件
- 9.2. JDBC[掌握]
- 9.3. HadoopAPI[了解]
- 9.4. SequenceFile文件[了解]
- 9.5. 对象文件[了解]
- 9.6. HBase[了解]
- 9.7. 扩展阅读
第一章 RDD详解
1.1 什么是RDD
1.1.1 为什么要有RDD?
在许多迭代式算法(比如机器学习、图算法等)和交互式数据挖掘中,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。但是,之前的MapReduce框架采用非循环式的数据流模型,把中间结果写入到HDFS中,带来了大量的数据复制、磁盘IO和序列化开销。且这些框架只能支持一些特定的计算模式(map/reduce),并没有提供一种通用的数据抽象。
AMP实验室发表的一篇关于RDD的论文:《Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing》就是为了解决这些问题的
RDD提供了一个抽象的数据模型,让我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换操作(函数),不同RDD之间的转换操作之间还可以形成依赖关系,进而实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘IO和序列化开销,并且还提供了更多的API(map/reduec/filter/groupBy…)
1.1.2 RDD是什么?
RDD(Resilient Distributed Dataset)叫做 弹性分布式数据集 ,是Spark中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算的集合 。
单词拆解
- Resilient :它是弹性的,RDD中的数据可以保存在内存中或者磁盘里面
- Distributed :它里面的元素是分布式存储的,可以用于分布式计算
- Dataset: 它是一个集合,可以存放很多元素
1.2. RDD的主要属性
1.A list of partitions :
一组分片(Partition)/一个分区(Partition)列表,即数据集的基本组成单位。
对于RDD来说,每个分片都会被一个计算任务处理,分片数决定并行度。
用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。
2.A function for computing each split :
一个函数会被作用在每一个分区。
Spark中RDD的计算是以分区为单位的,compute函数会被作用到每个分区上
3.A list of dependencies on other RDDs:
一个RDD会依赖于其他多个RDD。
RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。(Spark的容错机制)
4.Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned):
Spark中的分区函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。
对于KV类型的RDD会有一个Partitioner函数,即RDD的分区函数(可选项)
只有对于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数决定了RDD本身的分区数量,也决定了parent RDD Shuffle输出时的分区数量。
5.Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file):
可选项,一个列表,存储每个Partition的位置(preferred location)。
对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照"移动数据不如移动计算"的理念,Spark在进行任务调度的时候,会尽可能选择那些存有数据的worker节点来进行任务计算。
●总结
RDD 是一个数据集,不仅表示了数据集,还表示了这个数据集从哪来,如何计算。
主要属性包括
1.多分区
2.计算函数
3.依赖关系
4.分区函数(默认是hash)
5.最佳位置
第二章 RDD-API
2.1. 创建RDD
1.由外部存储系统的数据集创建,包括本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、Cassandra、HBase等
val rdd1 = sc.textFile(“hdfs://node01:8020/wordcount/input/words.txt”)
2.通过已有的RDD经过算子转换生成新的RDD
val rdd2=rdd1.flatMap(_.split(" "))
3.由一个已经存在的Scala集合创建
val rdd3 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
或者
val rdd4 = sc.makeRDD(List(1,2,3,4,5,6,7,8))
makeRDD方法底层调用了parallelize方法

2.2. RDD的方法/算子分类
2.2.1分类
RDD的算子分为两类:
1.Transformation转换操作:返回一个新的RDD
2.Action动作操作:返回值不是RDD(无返回值或返回其他的)
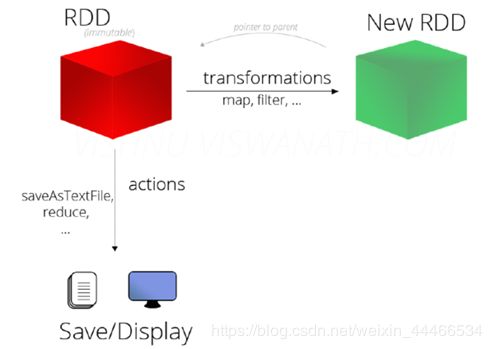
注意:
RDD不实际存储真正要计算的数据,而是记录了数据的位置在哪里,数据的转换关系(调用了什么方法,传入什么函数)
RDD中的所有转换都是惰性求值/延迟执行的,也就是说并不会直接计算。只有当发生一个要求返回结果给Driver的 Action动作时,这些转换才会真正运行。
| 之所以使用惰性求值/延迟执行,是因为这样可以在Action时对RDD操作形成DAG有向无环图进行Stage的划分和并行优化,这种设计让Spark更加有效率地运行。 |
|---|
2.2.2 Transformation转换算子
| 转换 | 含义 |
|---|---|
| map(func) | 返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成 |
| filter(func) | 返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成 |
| flatMap(func) | 类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素) |
| mapPartitions(func) | 类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U] |
| mapPartitionsWithIndex(func) | 类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是(Int, Interator[T]) => Iterator[U] |
| sample(withReplacement, fraction, seed) | 根据fraction指定的比例对数据进行采样,可以选择是否使用随机数进行替换,seed用于指定随机数生成器种子 |
| union(otherDataset) | 对源RDD和参数RDD求并集后返回一个新的RDD |
| intersection(otherDataset) | 对源RDD和参数RDD求交集后返回一个新的RDD |
| distinct([numTasks])) | 对源RDD进行去重后返回一个新的RDD |
| groupByKey([numTasks]) | 在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD |
| reduceByKey(func, [numTasks]) | 在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,与groupByKey类似,reduce任务的个数可以通过第二个可选的参数来设置 |
| aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) | |
| sortByKey([ascending], [numTasks]) | 在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD |
| sortBy(func,[ascending], [numTasks]) | 与sortByKey类似,但是更灵活 |
| join(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD |
| cogroup(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable,Iterable))类型的RDD |
| cartesian(otherDataset) | 笛卡尔积 |
| pipe(command, [envVars]) | 对rdd进行管道操作 |
| coalesce(numPartitions) | 减少 RDD 的分区数到指定值。在过滤大量数据之后,可以执行此操作 |
| repartition(numPartitions) | 重新给 RDD 分区 |
2.2.3 Action动作算子
| 动作 | 含义 |
|---|---|
| reduce(func) | 通过func函数聚集RDD中的所有元素,这个功能必须是可交换且可并联的 |
| collect() | 在驱动程序中,以数组的形式返回数据集的所有元素 |
| count() | 在驱动程序中,以数组的形式返回数据集的所有元素 |
| first() | 返回RDD的第一个元素(类似于take(1)) |
| take(n) | 返回一个由数据集的前n个元素组成的数组 |
| takeSample(withReplacement,num, [seed]) | 返回一个数组,该数组由从数据集中随机采样的num个元素组成,可以选择是否用随机数替换不足的部分,seed用于指定随机数生成器种子 |
| takeOrdered(n, [ordering]) | 返回自然顺序或者自定义顺序的前 n 个元素 |
| saveAsTextFile(path) | 将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本 |
| saveAsSequenceFile(path) | 将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。 |
| saveAsObjectFile(path) | 将数据集的元素,以 Java 序列化的方式保存到指定的目录下 |
| countByKey() | 针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。 |
| foreach(func) | 在数据集的每一个元素上,运行函数func进行更新。 |
| foreachPartition(func) | 在数据集的每一个分区上,运行函数func |
统计操作
| 算子 | 含义 |
|---|---|
| count | 个数 |
| mean | 均值 |
| sum | 求和 |
| max | 最大值 |
| min | 最小值 |
| variance | 方差 |
| sampleVariance | 从采样中计算方差 |
| stdev | 标准差:衡量数据的离散程度 |
| sampleStdev | 采样的标准差 |
| stats | 查看统计结果 |
2.3. 基础练习[快速演示]
2.3.1. 准备工作
●集群模式启动
启动Spark集群
| /export/servers/spark/sbin/start-all.sh |
|---|
启动spark-shell
/export/servers/spark/bin/spark-shell \
--master spark://node01:7077 \
--executor-memory 1g \
--total-executor-cores 2
●或本地模式启动
| /export/servers/spark/bin/spark-shell |
|---|
2.3.2. WordCount
val res = sc.textFile("hdfs://node01:8020/wordcount/input/words.txt")
.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
//上面的代码不会立即执行,因为都是Transformation转换操作
//下面的代码才会真正的提交并执行,因为是Action动作/行动操作
res.collect
2.3.3. 创建RDD
val rdd1 = sc.parallelize(List(5,6,4,7,3,8,2,9,1,10))
val rdd2 = sc.makeRDD(List(5,6,4,7,3,8,2,9,1,10))
2.3.4. 查看该RDD的分区数量
sc.parallelize(List(5,6,4,7,3,8,2,9,1,10)).partitions.length
//没有指定分区数,默认值是2
sc.parallelize(List(5,6,4,7,3,8,2,9,1,10),3).partitions.length
//指定了分区数为3
sc.textFile("hdfs://node01:8020/wordcount/input/words.txt").partitions.length
//2
RDD分区的数据取决于哪些因素?
RDD分区的原则是使得分区的个数尽量等于集群中的CPU核心(core)数目,这样可以充分利用CPU的计算资源,但是在实际中为了更加充分的压榨CPU的计算资源,会把并行度设置为cpu核数的2~3倍。RDD分区数和启动时指定的核数、调用方法时指定的分区数、如文件本身分区数 有关系
分区原则
1.启动的时候指定的CPU核数确定了一个参数值:
spark.default.parallelism=指定的CPU核数(集群模式最小2)
2.对于Scala集合调用parallelize(集合,分区数)方法,
如果没有指定分区数,就使用spark.default.parallelism,
如果指定了就使用指定的分区数(不要指定大于spark.default.parallelism)
3.对于textFile(文件,分区数) defaultMinPartitions
如果没有指定分区数sc.defaultMinPartitions=min(defaultParallelism,2)
如果指定了就使用指定的分区数sc.defaultMinPartitions=指定的分区数
rdd的分区数
对于本地文件:
rdd的分区数 = max(本地file的分片数, sc.defaultMinPartitions)
对于HDFS文件:
rdd的分区数 = max(hdfs文件的block数目, sc.defaultMinPartitions)
所以如果分配的核数为多个,且从文件中读取数据创建RDD,即使hdfs文件只有1个切片,最后的Spark的RDD的partition数也有可能是2
2.3.5. 不同转换算子的意义以及应用
map
对RDD中的每一个元素进行操作并返回操作的结果
//通过并行化生成rdd
val rdd1 = sc.parallelize(List(5, 6, 4, 7, 3, 8, 2, 9, 1, 10))
//对rdd1里的每一个元素
rdd1.map(_ * 2).collect
//collect方法表示收集,是action操作
filter
注意:函数中返回True的被留下,返回False的被过滤掉
val rdd2 = sc.parallelize(List(5, 6, 4, 7, 3, 8, 2, 9, 1, 10))
val rdd3 = rdd2.filter(_ >= 10)
rdd3.collect
//10
flatmap
对RDD中的每一个元素进行先map再压扁,最后返回操作的结果
val rdd1 = sc.parallelize(Array(“a b c”, “d e f”, “h i j”))
//将rdd1里面的每一个元素先切分再压平
val rdd2 = rdd1.flatMap(_.split(’ '))
rdd2.collect
//Array[String] = Array(a, b, c, d, e, f, h, i, j)
sortBy
val rdd1 = sc.parallelize(List(5, 6, 4, 7, 3, 8, 2, 9, 1, 10))
val rdd2 = rdd1.sortBy(x=>x,true)
// x=>x 表示按照元素本身进行排序,True表示升序
rdd2.collect
//1,2,3,…
val rdd2 = rdd1.sortBy(x=>x+"",true)
//x=>x+""表示按照x的字符串形式排序变成了字符串,结果为字典顺序
rdd2.collect
//1,10,2,3…
交集、并集、差集、笛卡尔积
注意类型要一致
val rdd1 = sc.parallelize(List(5, 6, 4, 3))
val rdd2 = sc.parallelize(List(1, 2, 3, 4))
//union不会去重
val rdd3 = rdd1.union(rdd2)
rdd3.collect
//去重
rdd3.distinct.collect
//求交集
val rdd4 = rdd1.intersection(rdd2)
rdd4.collect
//求差集
val rdd5 = rdd1.subtract(rdd2)
rdd5.collect
//笛卡尔积
val rdd1 = sc.parallelize(List(“jack”, “tom”))//学生
val rdd2 = sc.parallelize(List(“java”, “python”, “scala”))//课程
val rdd3 = rdd1.cartesian(rdd2)//表示所有学生的所有选课情况
rdd3.collect
//Array[(String, String)] = Array((jack,java), (jack,python), (jack,scala), (tom,java), (tom,python), (tom,scala))
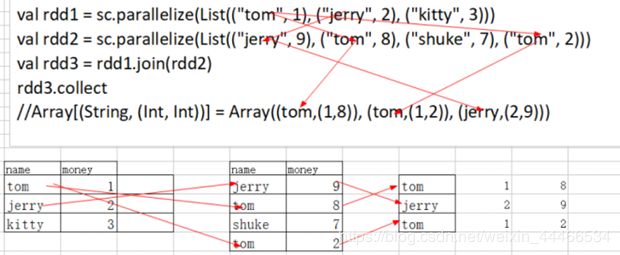
join
join(内连接)聚合具有相同key组成的value元组
val rdd1 = sc.parallelize(List((“tom”, 1), (“jerry”, 2), (“kitty”, 3)))
val rdd2 = sc.parallelize(List((“jerry”, 9), (“tom”, 8), (“shuke”, 7), (“tom”, 2)))
val rdd3 = rdd1.join(rdd2)
rdd3.collect
//Array[(String, (Int, Int))] = Array((tom,(1,8)), (tom,(1,2)), (jerry,(2,9)))
图解
val rdd4 = rdd1.leftOuterJoin(rdd2) //左外连接,左边的全留下,右边的满足条件的才留下
rdd4.collect
//Array[(String, (Int, Option[Int]))] = Array((tom,(1,Some(2))), (tom,(1,Some(8))), (jerry,(2,Some(9))), (kitty,(3,None)))
图解
 val rdd5 = rdd1.
val rdd5 = rdd1.rightOuterJoin(rdd2)
rdd5.collect
//Array[(String, (Option[Int], Int))] = Array((tom,(Some(1),2)), (tom,(Some(1),8)), (jerry,(Some(2),9)), (shuke,(None,7)))
val rdd6 = rdd1.union(rdd2)
rdd6.collect
//Array[(String, Int)] = Array((tom,1), (jerry,2), (kitty,3), (jerry,9), (tom,8), (shuke,7), (tom,2))
groupbykey
groupByKey()的功能是,对具有相同键的值进行分组。
比如,对四个键值对(“spark”,1)、(“spark”,2)、(“hadoop”,3)和(“hadoop”,5),
采用groupByKey()后得到的结果是:(“spark”,(1,2))和(“hadoop”,(3,5))。
//按key进行分组
val rdd6 = sc.parallelize(Array((“tom”,1), (“jerry”,2), (“kitty”,3), (“jerry”,9), (“tom”,8), (“shuke”,7), (“tom”,2)))
val rdd7=rdd6.groupByKey
rdd7.collect
//Array[(String, Iterable[Int])] = Array((tom,CompactBuffer(1, 8, 2)), (jerry,CompactBuffer(2, 9)), (shuke,CompactBuffer(7)), (kitty,CompactBuffer(3)))
cogroup[了解]
cogroup是先RDD内部分组,在RDD之间分组
val rdd1 = sc.parallelize(List((“tom”, 1), (“tom”, 2), (“jerry”, 3), (“kitty”, 2)))
val rdd2 = sc.parallelize(List((“jerry”, 2), (“tom”, 1), (“shuke”, 2)))
val rdd3 = rdd1.cogroup(rdd2)
rdd3.collect
// Array((tom,(CompactBuffer(1, 2),CompactBuffer(1))), (jerry,(CompactBuffer(3),CompactBuffer(2))), (shuke,(CompactBuffer(),CompactBuffer(2))), (kitty,(CompactBuffer(2),CompactBuffer())))
groupBy
根据指定的函数中的规则/key进行分组
val intRdd = sc.parallelize(List(1,2,3,4,5,6))
val result = intRdd.groupBy(x=>{if(x%2 == 0)“even” else “odd”}).collect
//Array[(String, Iterable[Int])] = Array((even,CompactBuffer(2, 4, 6)), (odd,CompactBuffer(1, 3, 5)))
reduce
val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5))
//reduce聚合
val result = rdd1.reduce(_ + )
// 第一 上次一个运算的结果,第二个_ 这一次进来的元素
★面试题
reduceByKey是Transformation还是Action? --Transformation
reduce是Transformation还是Action? --Action
reducebykey
注意reducebykey是转换算子
reduceByKey(func)的功能是,使用func函数合并具有相同键的值。
比如,reduceByKey((a,b) => a+b),有四个键值对(“spark”,1)、(“spark”,2)、(“hadoop”,3)和(“hadoop”,5)
对具有相同key的键值对进行合并后的结果就是:(“spark”,3)、(“hadoop”,8)。
可以看出,(a,b) => a+b这个Lamda表达式中,a和b都是指value,
比如,对于两个具有相同key的键值对(“spark”,1)、(“spark”,2),a就是1,b就是2。
val rdd1 = sc.parallelize(List((“tom”, 1), (“jerry”, 3), (“kitty”, 2), (“shuke”, 1)))
val rdd2 = sc.parallelize(List((“jerry”, 2), (“tom”, 3), (“shuke”, 2), (“kitty”, 5)))
val rdd3 = rdd1.union(rdd2) //并集
rdd3.collect
//Array[(String, Int)] = Array((tom,1), (jerry,3), (kitty,2), (shuke,1), (jerry,2), (tom,3), (shuke,2), (kitty,5))
//按key进行聚合
val rdd4 = rdd3.reduceByKey(_ + _)
rdd4.collect
//Array[(String, Int)] = Array((tom,4), (jerry,5), (shuke,3), (kitty,7))
repartition
改变分区数
val rdd1 = sc.parallelize(1 to 10,3) //指定3个分区
//利用repartition改变rdd1分区数
//减少分区
rdd1.repartition(2).partitions.length //新生成的rdd分区数为2
rdd1.partitions.length //3 //注意:原来的rdd分区数不变
//增加分区
rdd1.repartition(4).partitions.length
//减少分区
rdd1.repartition(3).partitions.length
//利用coalesce改变rdd1分区数
//减少分区
rdd1.coalesce(2).partitions.size
rdd1.coalesce(4).partitions.size
★注意:
repartition可以增加和减少rdd中的分区数,
coalesce默认减少rdd分区数,增加rdd分区数不会生效。
不管增加还是减少分区数原rdd分区数不变,变的是新生成的rdd的分区数
★应用场景:
在把处理结果保存到hdfs上之前可以减少分区数(合并小文件)
sc.textFile(“hdfs://node01:8020/wordcount/input/words.txt”)
.flatMap(.split(" ")).map((,1)).reduceByKey(+)
.repartition(1)
//在保存到HDFS之前进行重分区为1,那么保存在HDFS上的结果文件只有1个
.saveAsTextFile(“hdfs://node01:8020/wordcount/output5”)
collect
val rdd1 = sc.parallelize(List(6,1,2,3,4,5), 2)
rdd1.collect
count
count统计集合中元素的个数
rdd1.count //6
求RDD中最外层集合里面的元素的个数
val rdd3 = sc.parallelize(List(List(“a b c”, “a b b”),List(“e f g”, “a f g”), List(“h i j”, “a a b”)))
rdd3.count //3
distinct
val rdd = sc.parallelize(Array(1,2,3,4,5,5,6,7,8,1,2,3,4), 3)
rdd.distinct.collect
top
//取出最大的前N个
val rdd1 = sc.parallelize(List(3,6,1,2,4,5))
rdd1.top(2)
take
//按照原来的顺序取前N个
rdd1.take(2) //3 6
//需求:取出最小的2个
rdd1.sortBy(x=>x,true).take(2)
first
//按照原来的顺序取前第一个
rdd1.first
keys、values
val rdd1 = sc.parallelize(List(“dog”, “tiger”, “lion”, “cat”, “panther”, “eagle”), 2)
val rdd2 = rdd1.map(x => (x.length, x))
rdd2.collect
//Array[(Int, String)] = Array((3,dog), (5,tiger), (4,lion), (3,cat), (7,panther), (5,eagle))
rdd2.keys.collect
//Array[Int] = Array(3, 5, 4, 3, 7, 5)
rdd2.values.collect
//Array[String] = Array(dog, tiger, lion, cat, panther, eagle)
mapValues
mapValues表示对RDD中的元素进行操作,Key不变,Value变为操作之后
val rdd1 = sc.parallelize(List((1,10),(2,20),(3,30)))
val rdd2 = rdd1.mapValues(_*2).collect //_表示每一个value ,key不变,将函数作用于value
//(1,20),(2,40),(3,60)
collectAsMap
转换成Map
val rdd = sc.parallelize(List((“a”, 1), (“b”, 2)))
rdd.collectAsMap
//scala.collection.Map[String,Int] = Map(b -> 2, a -> 1)
面试题:foreach和foreachPartition
val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7, 8, 9), 3)
rdd1.foreach(x => println(x*100)) //x是每一个元素
rdd1.foreachPartition(x => println(x.reduce(_ + _))) //x是每个分区
注意:foreach和foreachPartition都是Action操作,但是以上代码在spark-shell中执行看不到输出结果,
原因是传给foreach和foreachPartition的计算函数是在各个分区执行的,即在集群中的各个Worker上执行的
应用场景:
比如在函数中要将RDD中的元素保存到数据库
foreach:会将函数作用到RDD中的每一条数据,那么有多少条数据,操作数据库连接的开启关闭就得执行多少次
foreachPartition:将函数作用到每一个分区,那么每一个分区执行一次数据库连接的开启关闭,有几个分区就会执行数据库连接开启关闭
import org.apache.spark.{SparkConf, SparkContext}
object Test {
def main(args: Array[String]): Unit = {
val config = new SparkConf().setMaster("local[*]").setAppName("WordCount")
val sc = new SparkContext(config)
//设置日志输出级别
sc.setLogLevel("WARN")
val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7, 8, 9), 3)
//Applies a function f to all elements of this RDD.
//将函数f应用于此RDD的所有元素
rdd1.foreach(x => println(x*100))
//把函数传给各个分区,在分区内循环遍历该分区中的元素
//x每个元素,即一个一个的数字
println("==========================")
//Applies a function f to each partition of this RDD.
//将函数f应用于此RDD的每个分区
rdd1.foreachPartition(x => println(x.reduce(_ + _)))
//把各个分区传递给函数执行
//x是每个分区
}
}
面试题:map和mapPartitions
将每一个分区传递给函数
val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7, 8, 9), 3)
rdd1.mapPartitions(x=>x.map(y=>y*2)).collect
//x是每一个分区,y是分区中的元素
扩展:mapPartitionsWithIndex(同时获取分区号)
功能:取分区中对应的数据时,还可以将分区的编号取出来,这样就可以知道数据是属于哪个分区的
val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9), 3)
//该函数的功能是将对应分区中的数据取出来,并且带上分区编号
// 一个index 分区编号
// 一个iter分区内的数据
val func = (index: Int, iter: Iterator[Int]) => {
iter.map(x => “[partID:” + index + ", val: " + x + “]”)
}
rdd1.mapPartitionsWithIndex(func).collect
//Array[String] = Array(
[partID:0, val: 1], [partID:0, val: 2], [partID:0, val: 3],
[partID:1, val: 4], [partID:1, val: 5], [partID:1, val: 6],
[partID:2, val: 7], [partID:2, val: 8], [partID:2, val: 9]
)
扩展:aggregate
val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9), 3)
//0表示初始值
//第一个_+,表示区内聚合,第一个_表示历史值,第二个_表示当前值
//第二个+_,表示区间聚合,第一个_表示历史值,第二个_表示当前值
val result1: Int = rdd1.aggregate(0)( _ + _ , _ + _) //45 ==> 6 + 15 + 24 = 45
//10表示初始值,每个分区有初始值,区间聚合的时候也有初始值
val result2: Int = rdd1.aggregate(10)( _ + _ , _ + _) //85 ==> 10+ (10+6 + 10+15 + 10+24)=85
扩展:combineByKey
val rdd1 = sc.textFile(“hdfs://node01:8020/wordcount/input/words.txt”).flatMap(.split(" ")).map((, 1))
//Array((hello,1), (me,1), (hello,1), (you,1), (hello,1), (her,1))
//x => x,表示key不变
//(a: Int, b: Int) => a + b:表示区内聚合
//(m: Int, n: Int) => m + n:表示区间聚合
val rdd2 = rdd1.combineByKey(x => x, (a: Int, b: Int) => a + b, (m: Int, n: Int) => m + n)
//val rdd2 = rdd1.combineByKey(x => x, _ + _ , _ + _ )//注意这里简写错误,原则:能省则省,不能省则不要偷懒
rdd2.collect
//Array[(String, Int)] = Array((hello,3), (me,1), (you,1), (her,1))
val rddData1: RDD[(String, Float)] = sc.parallelize(
Array(
(“班级1”, 95f),
(“班级2”, 80f),
(“班级1”, 75f),
(“班级3”, 97f),
(“班级2”, 88f)),
2)
val rddData2 = rddData1.combineByKey(
grade => (grade, 1),
(gc: (Float, Int), grade) => (gc._1 + grade, gc._2 + 1),
(gc1: (Float, Int), gc2: (Float, Int)) => (gc1._1 + gc2._1, gc1._2 + gc2._2)
)
val rddData3 = rddData2.map(t => (t._1, t._2._1 / t._2._2))
rddData3.collect
扩展:aggregateByKey
val pairRDD = sc.parallelize(List( (“cat”,2), (“cat”, 5), (“mouse”, 4),(“cat”, 12), (“dog”, 12), (“mouse”, 2)), 2)
def func(index: Int, iter: Iterator[(String, Int)]) : Iterator[String] = {
iter.map(x => “[partID:” + index + ", val: " + x + “]”)
}
pairRDD.mapPartitionsWithIndex(func).collect
//Array(
[partID:0, val: (cat,2)], [partID:0, val: (cat,5)], [partID:0, val: (mouse,4)],
[partID:1, val: (cat,12)], [partID:1, val: (dog,12)], [partID:1, val: (mouse,2)]
)
pairRDD.aggregateByKey(0)(math.max( _ , _ ), _ + _ ).collect
// Array[(String, Int)] = Array((dog,12), (cat,17), (mouse,6))
//100表示区内初始值,区间聚合没有
pairRDD.aggregateByKey(100)(math.max(_, _), _ + _).collect
//Array[(String, Int)] = Array((dog,100), (cat,200), (mouse,200))
pairRDD.aggregateByKey(5)(math.max(_, _), _ + _).collect
//Array[(String, Int)] = Array((dog,12), (cat,17), (mouse,10))
pairRDD.aggregateByKey(10)(math.max(_, _), _ + _).collect
//Array[(String, Int)] = Array((dog,12), (cat,22), (mouse,20))
val rddData1 = sc.parallelize(
Array(
(“用户1”, “接口1”),
(“用户2”, “接口1”),
(“用户1”, “接口1”),
(“用户1”, “接口2”),
(“用户2”, “接口3”)),
2)
val rddData2 = rddData1.aggregateByKey(collection.mutable.SetString)(
(urlSet, url) => urlSet += url,
(urlSet1, urlSet2) => urlSet1 ++= urlSet2)
rddData2.collect
小练习
●需求
给定一个键值对RDD
val rdd = sc.parallelize(Array((“spark”,2),(“hadoop”,6),(“hadoop”,4),(“spark”,6)))
key表示图书名称,
value表示某天图书销量,
请计算每个键对应的平均值,也就是计算每种图书的每天平均销量。
最终结果:(“spark”,4),(“hadoop”,5)
val rdd1 = rdd.==groupByKey ==
rdd1.collect
//Array((spark,CompactBuffer(6, 2)), (hadoop,CompactBuffer(4, 6)))
val rdd2 = rdd1.mapValues(v => v.sum / v.size)
rdd2.collect
●答案
val rdd = sc.parallelize(Array((“spark”,2),(“hadoop”,6),(“hadoop”,4),(“spark”,6)))
val rdd2 = rdd.groupByKey()
rdd2.collect
//Array[(String, Iterable[Int])] = Array((spark,CompactBuffer(2, 6)), (hadoop,CompactBuffer(6, 4)))
val rdd3 = rdd2.map(t=>(t._1,t._2.sum /t._2.size))
rdd3.collect
//Array[(String, Int)] = Array((spark,4), (hadoop,5))
总结
●分类
RDD的算子分为两类,一类是Transformation转换操作,一类是Action动作操作
●如何区分Transformation和Action
返回值是RDD的为Transformation转换操作,延迟执行/懒执行/惰性执行
返回值不是RDD(如Unit、Array、Int)的为Action动作操作
●面试题:
1.Transformation操作的API有哪些? --map/flatMap/filter…
2.Action操作的API有哪些? --collect/reduce/saveAsTextFile…
3.reduceByKey是Transformation还是Action? --Transformation
4.reduce是Transformation还是Action? – Action
5.foreach和foreachPartition的区别? foreach作用于每个元素,foreachPartition作用于每个分区
●注意:
RDD不实际存储真正要计算的数据,而只是记录了RDD的转换关系(调用了什么方法,传入什么函数,依赖哪些RDD,分区器是什么,数量块来源机器列表)
RDD中的所有转换操作都是延迟执行(懒执行)的,也就是说并不会直接计算。只有当发生Action操作的时候,这些转换才会真正运行。
第三章 RDD的持久化/缓存
3.1 引入
在实际开发中某些RDD的计算或转换可能会比较耗费时间,如果这些RDD后续还会频繁的被使用到,那么可以将这些RDD进行持久化/缓存,这样下次再使用到的时候就不用再重新计算了,提高了程序运行的效率
3.2 持久化/缓存API详解
●persist方法和cache方法
RDD通过persist或cache方法可以将前面的计算结果缓存,但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用。
通过查看RDD的源码发现cache最终也是调用了persist无参方法(默认存储只存在内存中)

3.3 代码演示
●启动集群和spark-shell
/export/servers/spark/sbin/start-all.sh
/export/servers/spark/bin/spark-shell \
--master spark://node01:7077,node02:7077 \
--executor-memory 1g \
--total-executor-cores 2
●将一个RDD持久化,后续操作该RDD就可以直接从缓存中拿
val rdd1 = sc.textFile("hdfs://node01:8020/wordcount/input/words.txt")
val rdd2 = rdd1.flatMap(x=>x.split(" ")).map((_,1)).reduceByKey(_+_)
rdd2.cache //缓存/持久化
rdd2.sortBy(_._2,false).collect//触发action,会去读取HDFS的文件,rdd2会真正执行持久化
rdd2.sortBy(_._2,false).collect//触发action,会去读缓存中的数据,执行速度会比之前快,因为rdd2已经持久化到内存中了
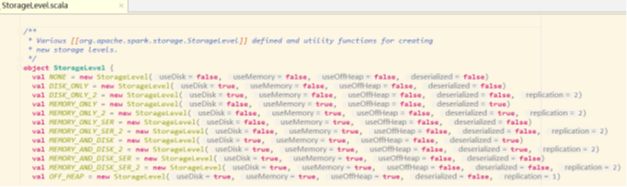
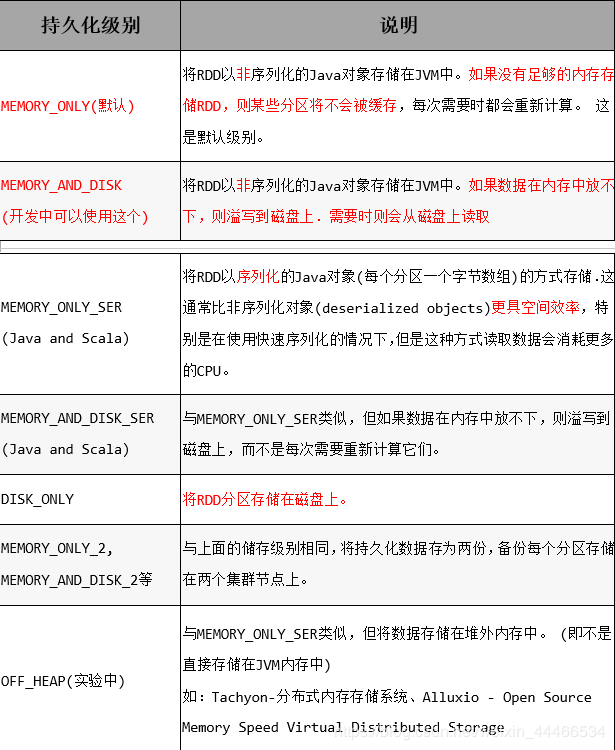
●存储级别
默认的存储级别都是仅在内存存储一份,Spark的存储级别还有好多种,存储级别在object StorageLevel中定义的
总结
3.4 总结
1.RDD持久化/缓存的目的是为了提高后续操作的速度
2.缓存的级别有很多,默认只存在内存中,开发中使用memory_and_disk
3.只有执行action操作的时候才会真正将RDD数据进行持久化/缓存
4.实际开发中如果某一个RDD后续会被频繁的使用,可以将该RDD进行持久化/缓存
第四章 RDD容错机制Checkpoint
4.1 引入
●持久化的局限
持久化/缓存可以把数据放在内存中,虽然是快速的,但是也是最不可靠的;也可以把数据放在磁盘上,也不是完全可靠的!例如磁盘会损坏等。
●问题解决
Checkpoint的产生就是为了更加可靠的数据持久化,在Checkpoint的时候一般把数据放在在HDFS上,这就天然的借助了HDFS天生的高容错、高可靠来实现数据最大程度上的安全,实现了RDD的容错和高可用
●使用步骤
1.SparkContext.setCheckpointDir("目录") //HDFS的目录
2.RDD.checkpoint()
4.2 代码演示
==sc.setCheckpointDir(“hdfs://node01:8020/ckpdir”) ==
//设置检查点目录,会立即在HDFS上创建一个空目录
val rdd1 = sc.textFile(“hdfs://node01:8020/wordcount/input/words.txt”).flatMap(.split(" ")).map(( _ , 1)).reduceByKey( _ +)
rdd1.checkpoint() //对rdd1进行检查点保存
rdd1.collect //Action操作才会真正执行checkpoint
//后续如果要使用到rdd1可以从checkpoint中读取
●查看结果:
hdfs dfs -ls /
或者通过web界面查看
http://192.168.1.101:50070/dfshealth.html#tab-overview
4.3. 总结
●开发中如何保证数据的安全性性及读取效率
可以对频繁使用且重要的数据,先做缓存/持久化,再做checkpint操作
●持久化和Checkpoint的区别
1.位置
Persist 和 Cache 只能保存在本地的磁盘和内存中(或者堆外内存–实验中)
Checkpoint 可以保存数据到 HDFS 这类可靠的存储上
2.生命周期
Cache和Persist的RDD会在程序结束后会被清除或者手动调用unpersist方法
Checkpoint的RDD在程序结束后依然存在,不会被删除
3.Lineage(血统、依赖链–其实就是依赖关系)
Persist和Cache,不会丢掉RDD间的依赖链/依赖关系,因为这种缓存是不可靠的,如果出现了一些错误(例如 Executor 宕机),需要通过回溯依赖链重新计算出来
Checkpoint会斩断依赖链,因为Checkpoint会把结果保存在HDFS这类存储中,更加的安全可靠,一般不需要回溯依赖链
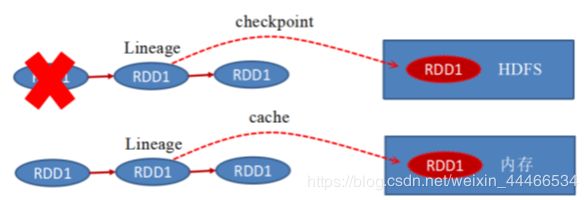
●补充:Lineage
RDD的Lineage(血统、依赖链)会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
在进行故障恢复时,Spark会对读取Checkpoint的开销和重新计算RDD分区的开销进行比较,从而自动选择最优的恢复策略。
第五章 RDD依赖关系
5.1. 宽窄依赖
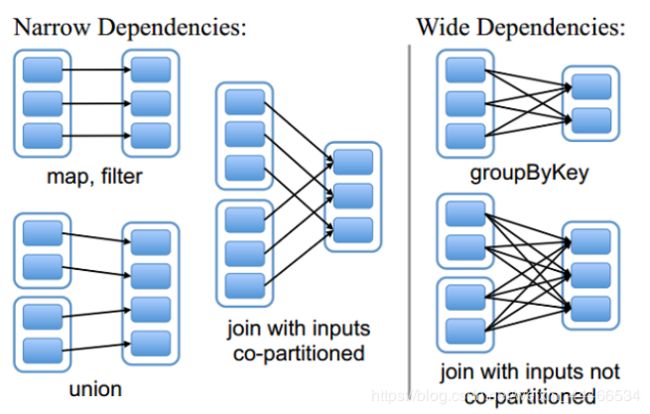
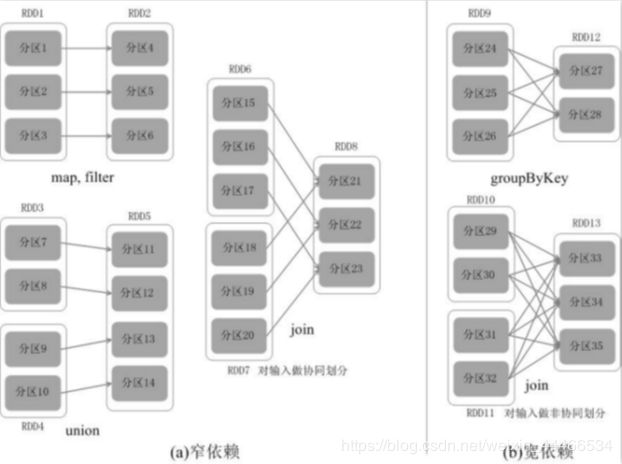
●两种依赖关系类型
RDD和它依赖的父RDD的关系有两种不同的类型,即
宽依赖(wide dependency/shuffle dependency)
窄依赖(narrow dependency)
●图解
●如何区分宽窄依赖
窄依赖:父RDD的一个分区只会被子RDD的一个分区依赖
宽依赖:父RDD的一个分区会被子RDD的多个分区依赖(涉及到shuffle)
●面试题:
子RDD的一个分区依赖多个父RDD是宽依赖还是窄依赖?
不能确定,也就是宽窄依赖的划分依据是父RDD的一个分区是否被子RDD的多个分区所依赖,是,就是宽依赖,或者从shuffle的角度去判断,有shuffle就是宽依赖
5.2. 为什么要设计宽窄依赖
1.对于窄依赖
Spark可以并行计算
如果有一个分区数据丢失,只需要从父RDD的对应1个分区重新计算即可,不需要重新计算整个任务,提高容错。
2.对于宽依赖
是划分Stage的依据
第六章 DAG的生成和划分Stage
6.1. DAG介绍
●DAG是什么
DAG(Directed Acyclic Graph有向无环图)指的是数据转换执行的过程,有方向,无闭环(其实就是RDD执行的流程)
原始的RDD通过一系列的转换操作就形成了DAG有向无环图,任务执行时,可以按照DAG的描述,执行真正的计算(数据被操作的一个过程)
●DAG的边界
开始:通过SparkContext创建的RDD
结束:触发Action,一旦触发Action就形成了一个完整的DAG
●注意:
一个Spark应用中可以有一到多个DAG,取决于触发了多少次Action
一个DAG中会有不同的阶段/stage,划分阶段/stage的依据就是宽依赖
一个阶段/stage中可以有多个Task,一个分区对应一个Task
6.2. DAG划分Stage
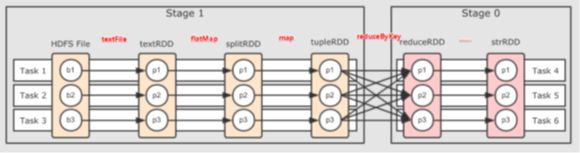
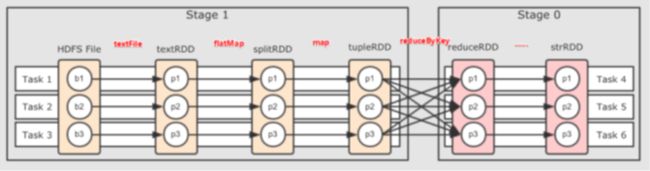
●为什么要划分Stage? --并行计算
一个复杂的业务逻辑如果有shuffle,那么就意味着前面阶段产生结果后,才能执行下一个阶段,即下一个阶段的计算要依赖上一个阶段的数据。那么我们按照shuffle进行划分(也就是按照宽依赖就行划分),就可以将一个DAG划分成多个Stage/阶段,在同一个Stage中,会有多个算子操作,可以形成一个pipeline流水线,流水线内的多个平行的分区可以并行执行
●如何划分DAG的stage
对于窄依赖,partition的转换处理在stage中完成计算,不划分(将窄依赖尽量放在在同一个stage中,可以实现流水线计算)
对于宽依赖,由于有shuffle的存在,只能在父RDD处理完成后,才能开始接下来的计算,也就是说需要要划分stage(出现宽依赖即拆分)
●总结
Spark会根据shuffle/宽依赖使用回溯算法来对DAG进行Stage划分,从后往前,遇到宽依赖就断开,遇到窄依赖就把当前的RDD加入到当前的stage/阶段中
具体的划分算法请参见AMP实验室发表的论文
《Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing》
http://xueshu.baidu.com/usercenter/paper/show?paperid=b33564e60f0a7e7a1889a9da10963461&site=xueshu_se
第七章 Spark原理初探
7.1. 基本概念
http://spark.apache.org/docs/latest/cluster-overview.html

●名词解释
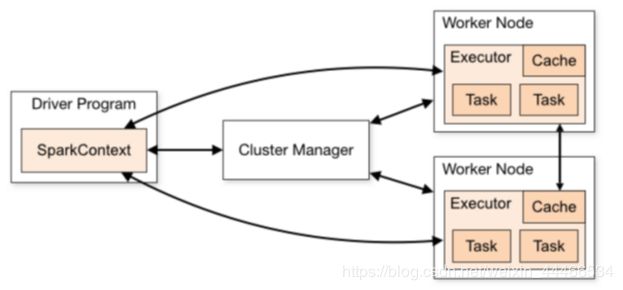
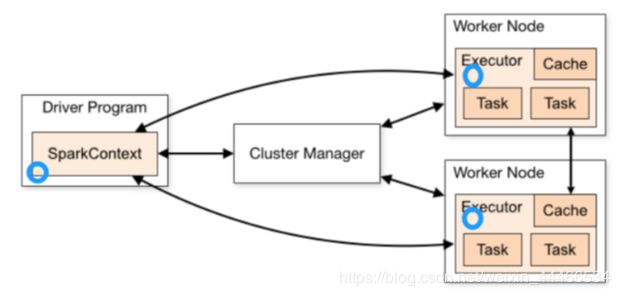
1.Application:指的是用户编写的Spark应用程序/代码,包含了Driver功能代码和分布在集群中多个节点上运行的Executor代码。
2.Driver:Spark中的Driver即运行上述Application的Main()函数并且创建SparkContext,SparkContext负责和ClusterManager通信,进行资源的申请、任务的分配和监控等
3.Cluster Manager:指的是在集群上获取资源的外部服务,Standalone模式下由Master负责,Yarn模式下ResourceManager负责;
4.Executor:是运行在工作节点Worker上的进程,负责运行任务,并为应用程序存储数据,是执行分区计算任务的进程;
5.RDD:Resilient Distributed Dataset弹性分布式数据集,是分布式内存的一个抽象概念;
6.DAG:Directed Acyclic Graph有向无环图,反映RDD之间的依赖关系和执行流程;
7.Job:作业,按照DAG执行就是一个作业;Job==DAG
8.Stage:阶段,是作业的基本调度单位,同一个Stage中的Task可以并行执行,多个Task组成TaskSet任务集
9.Task:任务,运行在Executor上的工作单元,一个Task计算一个分区,包括pipline上的一系列操作
7.2. 基本流程
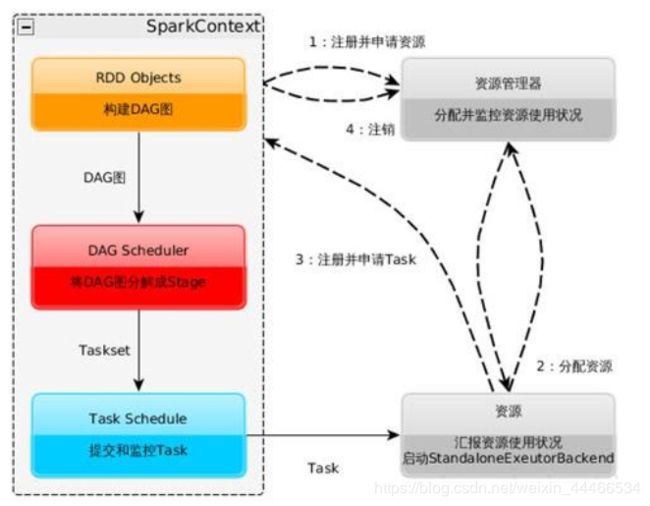
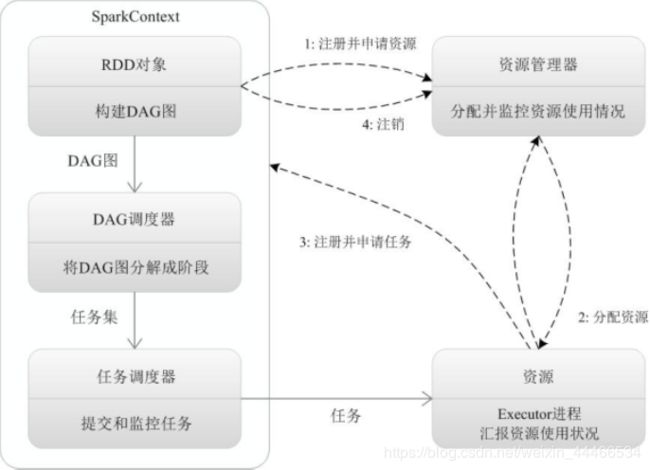
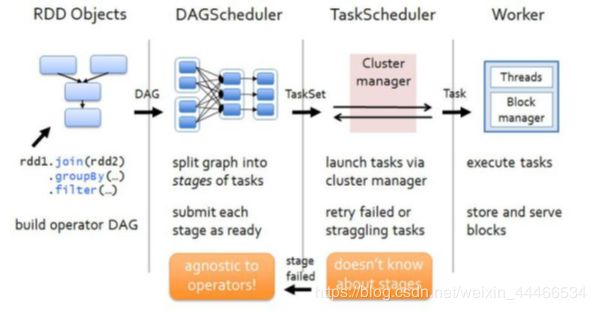
●Spark运行基本流程
1.当一个Spark应用被提交时,首先需要为这个Spark Application构建基本的运行环境,即由任务控制节点(Driver)创建一个SparkContext,
2.SparkContext向资源管理器注册并申请运行Executor资源;
3.资源管理器为Executor分配资源并启动Executor进程,Executor运行情况将随着心跳发送到资源管理器上;
4.SparkContext根据RDD的依赖关系构建成DAG图,并提交给DAGScheduler进行解析划分成Stage,并把该Stage中的Task组成Taskset发送给TaskScheduler。
5.TaskScheduler将Task发放给Executor运行,同时SparkContext将应用程序代码发放给Executor。
6.Executor将Task丢入到线程池中执行,把执行结果反馈给任务调度器,然后反馈给DAG调度器,运行完毕后写入数据并释放所有资源。
7.3. 流程图解
7.4. 总结
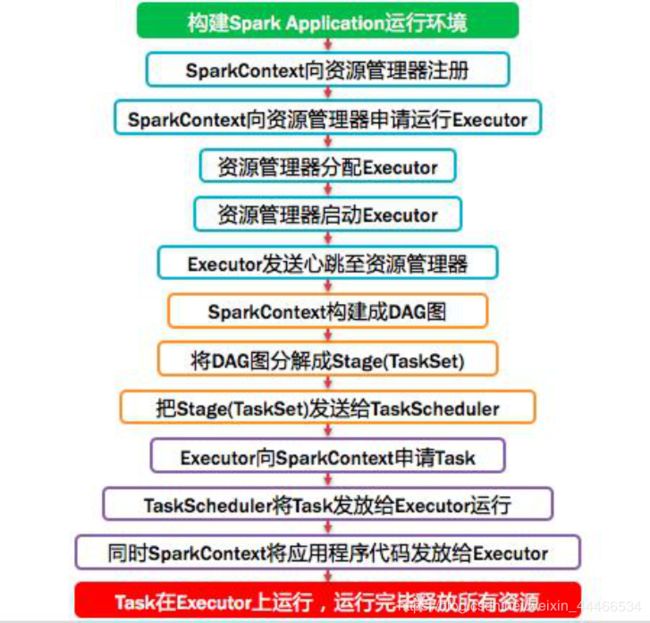
1.Spark应用被提交–>SparkContext向资源管理器注册并申请资源–>启动Executor
2.RDD–>构建DAG–>DAGScheduler划分Stage形成TaskSet–>TaskScheduler提交Task–>Worker上的Executor执行Task
第八章 RDD累加器和广播变量
在默认情况下,当Spark在集群的多个不同节点的多个任务上并行运行一个函数时,它会把函数中涉及到的每个变量,在每个任务上都生成一个副本。但是,有时候需要在多个任务之间共享变量,或者在任务(Task)和任务控制节点(Driver Program)之间共享变量。
为了满足这种需求,Spark提供了两种类型的变量:
1.累加器accumulators:累加器支持在所有不同节点之间进行累加计算(比如计数或者求和)
2.广播变量broadcast variables:广播变量用来把变量在所有节点的内存之间进行共享,在每个机器上缓存一个只读的变量,而不是为机器上的每个任务都生成一个副本。
8.1. 累加器
8.1.1. 不使用累加器

8.1.2. 使用累加器
通常在向 Spark 传递函数时,比如使用 map() 函数或者用 filter() 传条件时,可以使用驱动器程序中定义的变量,但是集群中运行的每个任务都会得到这些变量的一份新的副本,更新这些副本的值也不会影响驱动器中的对应变量。这时使用累加器就可以实现我们想要的效果。
val xx: Accumulator[Int] = sc.accumulator(0)
8.1.3. 代码演示
package cn.itcast.core
import org.apache.spark.rdd.RDD
import org.apache.spark.{Accumulator, SparkConf, SparkContext}
object AccumulatorTest {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
sc.setLogLevel("WARN")
//使用scala集合完成累加
var counter1: Int = 0;
var data = Seq(1,2,3)
data.foreach(x => counter1 += x )
println(counter1)//6
println("+++++++++++++++++++++++++")
//使用RDD进行累加
var counter2: Int = 0;
val dataRDD: RDD[Int] = sc.parallelize(data) //分布式集合的[1,2,3]
dataRDD.foreach(x => counter2 += x)
println(counter2)//0
//注意:上面的RDD操作运行结果是0
//因为foreach中的函数是传递给Worker中的Executor执行,用到了counter2变量
//而counter2变量在Driver端定义的,在传递给Executor的时候,各个Executor都有了一份counter2
//最后各个Executor将各自个x加到自己的counter2上面了,和Driver端的counter2没有关系
//那这个问题得解决啊!不能因为使用了Spark连累加都做不了了啊!
//如果解决?---使用累加器
val counter3: Accumulator[Int] = sc.accumulator(0)
dataRDD.foreach(x => counter3 += x)
println(counter3)//6
}
}
8.2. 广播变量
8.2.1. 不使用广播变量
8.2.2. 使用广播变量
8.2.3. 代码演示
package cn.itcast.core
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object BroadcastVariablesTest {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
sc.setLogLevel("WARN")
//不使用广播变量
val kvFruit: RDD[(Int, String)] = sc.parallelize(List((1,"apple"),(2,"orange"),(3,"banana"),(4,"grape")))
val fruitMap: collection.Map[Int, String] =kvFruit.collectAsMap
//scala.collection.Map[Int,String] = Map(2 -> orange, 4 -> grape, 1 -> apple, 3 -> banana)
val fruitIds: RDD[Int] = sc.parallelize(List(2,4,1,3))
//根据水果编号取水果名称
val fruitNames: RDD[String] = fruitIds.map(x=>fruitMap(x))
fruitNames.foreach(println)
//注意:以上代码看似一点问题没有,但是考虑到数据量如果较大,且Task数较多,
//那么会导致,被各个Task共用到的fruitMap会被多次传输
//应该要减少fruitMap的传输,一台机器上一个,被该台机器中的Task共用即可
//如何做到?---使用广播变量
println("=====================")
val BroadcastFruitMap: Broadcast[collection.Map[Int, String]] = sc.broadcast(fruitMap)
val fruitNames2: RDD[String] = fruitIds.map(x=>BroadcastFruitMap.value(x))
fruitNames2.foreach(println)
}
}
第九章 RDD数据源
9.1. 普通文本文件
sc.textFile("./dir/*.txt")
如果传递目录,则将目录下的所有文件读取作为RDD。文件路径支持通配符。
但是这样对于大量的小文件读取效率并不高,应该使用wholeTextFiles
def wholeTextFiles(path: String, minPartitions: Int = defaultMinPartitions): RDD[(String, String)])
返回值RDD[(String, String)],其中Key是文件的名称,Value是文件的内容。
9.2. JDBC[掌握]
Spark支持通过Java JDBC访问关系型数据库。需要使用JdbcRDD
代码演示
package cn.itcast.core
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.spark.rdd.{JdbcRDD, RDD}
import org.apache.spark.{SparkConf, SparkContext}
/**
* Desc 演示使用Spark操作JDBC-API实现将数据存入到MySQL并读取出来
*/
object JDBCDataSourceTest {
def main(args: Array[String]): Unit = {
//1.创建SparkContext
val config = new SparkConf().setAppName("JDBCDataSourceTest").setMaster("local[*]")
val sc = new SparkContext(config)
sc.setLogLevel("WARN")
//2.插入数据
val data: RDD[(String, Int)] = sc.parallelize(List(("jack", 18), ("tom", 19), ("rose", 20)))
//调用foreachPartition针对每一个分区进行操作
//data.foreachPartition(saveToMySQL)
//3.读取数据
def getConn():Connection={
DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8", "root", "root")
}
val studentRDD: JdbcRDD[(Int, String, Int)] = new JdbcRDD(sc,
getConn,
"select * from t_student where id >= ? and id <= ? ",
4,
6,
2,
rs => {
val id: Int = rs.getInt("id")
val name: String = rs.getString("name")
val age: Int = rs.getInt("age")
(id, name, age)
}
)
println(studentRDD.collect().toBuffer)
}
/*
CREATE TABLE `t_student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
*/
def saveToMySQL(partitionData:Iterator[(String, Int)] ):Unit = {
//将数据存入到MySQL
//获取连接
val conn: Connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8", "root", "root")
partitionData.foreach(data=>{
//将每一条数据存入到MySQL
val sql = "INSERT INTO `t_student` (`id`, `name`, `age`) VALUES (NULL, ?, ?);"
val ps: PreparedStatement = conn.prepareStatement(sql)
ps.setString(1,data._1)
ps.setInt(2,data._2)
ps.execute()//preparedStatement.addBatch()
})
//ps.executeBatch()
conn.close()
}
}
9.3. HadoopAPI[了解]
https://blog.csdn.net/leen0304/article/details/78854530
Spark的整个生态系统与Hadoop是完全兼容的,所以对于Hadoop所支持的文件类型或者数据库类型,Spark也同样支持。
HadoopRDD、newAPIHadoopRDD、saveAsHadoopFile、saveAsNewAPIHadoopFile 是底层API
其他的API接口都是为了方便最终的Spark程序开发者而设置的,是这两个接口的高效实现版本.
9.4. SequenceFile文件[了解]
SequenceFile文件是Hadoop用来存储二进制形式的key-value对而设计的一种平面文件(Flat File)。
https://blog.csdn.net/bitcarmanlee/article/details/78111289
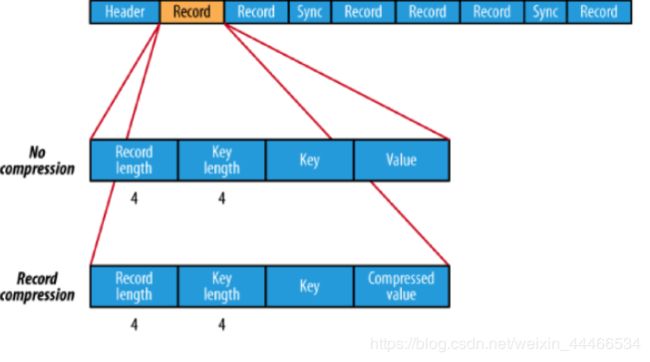
读sc.sequenceFile keyClass, valueClass
写RDD.saveAsSequenceFile(path)
要求键和值能够自动转为Writable类型。

9.5. 对象文件[了解]
对象文件是将对象序列化后保存的文件
读sc.objectFilek,v //因为是序列化所以要指定类型
写RDD.saveAsObjectFile()
9.6. HBase[了解]
由于 org.apache.hadoop.hbase.mapreduce.TableInputFormat 类的实现,Spark 可以通过Hadoop输入格式访问HBase。
这个输入格式会返回键值对数据,
其中键的类型为org. apache.hadoop.hbase.io.ImmutableBytesWritable,
而值的类型为org.apache.hadoop.hbase.client.Result。
https://github.com/teeyog/blog/issues/22
9.7. 扩展阅读
package cn.itcast.core
import org.apache.hadoop.io.{LongWritable, Text}
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object DataSourceTest {
def main(args: Array[String]): Unit = {
val config = new SparkConf().setAppName("DataSourceTest").setMaster("local[*]")
val sc = new SparkContext(config)
sc.setLogLevel("WARN")
System.setProperty("HADOOP_USER_NAME", "root")
//1.HadoopAPI
println("HadoopAPI")
val dataRDD = sc.parallelize(Array((1,"hadoop"), (2,"hive"), (3,"spark")))
dataRDD.saveAsNewAPIHadoopFile("hdfs://node01:8020/spark_hadoop/",
classOf[LongWritable],
classOf[Text],
classOf[TextOutputFormat[LongWritable, Text]])
val inputRDD: RDD[(LongWritable, Text)] = sc.newAPIHadoopFile(
"hdfs://node01:8020/spark_hadoop/*",
classOf[TextInputFormat],
classOf[LongWritable],
classOf[Text],
conf = sc.hadoopConfiguration
)
inputRDD.map(_._2.toString).foreach(println)
//2.读取小文件
println("读取小文件")
val filesRDD: RDD[(String, String)] = sc.wholeTextFiles("D:\\data\\spark\\files", minPartitions = 3)
val linesRDD: RDD[String] = filesRDD.flatMap(_._2.split("\\r\\n"))
val wordsRDD: RDD[String] = linesRDD.flatMap(_.split(" "))
wordsRDD.map((_, 1)).reduceByKey(_ + _).collect().foreach(println)
//3.操作SequenceFile
println("SequenceFile")
val dataRDD2: RDD[(Int, String)] = sc.parallelize(List((2, "aa"), (3, "bb"), (4, "cc"), (5, "dd"), (6, "ee")))
dataRDD2.saveAsSequenceFile("D:\\data\\spark\\SequenceFile")
val sdata: RDD[(Int, String)] = sc.sequenceFile[Int, String]("D:\\data\\spark\\SequenceFile\\*")
sdata.collect().foreach(println)
//4.操作ObjectFile
println("ObjectFile")
val dataRDD3 = sc.parallelize(List((2, "aa"), (3, "bb"), (4, "cc"), (5, "dd"), (6, "ee")))
dataRDD3.saveAsObjectFile("D:\\data\\spark\\ObjectFile")
val objRDD = sc.objectFile[(Int, String)]("D:\\data\\spark\\ObjectFile\\*")
objRDD.collect().foreach(println)
sc.stop()
}
}
package cn.itcast.core
import org.apache.hadoop.hbase.client.{HBaseAdmin, Put, Result}
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.{HBaseConfiguration, HColumnDescriptor, HTableDescriptor, TableName}
import org.apache.hadoop.hbase.mapred.TableOutputFormat
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.mapred.JobConf
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object DataSourceTest2 {
def main(args: Array[String]): Unit = {
val config = new SparkConf().setAppName("DataSourceTest").setMaster("local[*]")
val sc = new SparkContext(config)
sc.setLogLevel("WARN")
val conf = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum", "node01:2181,node02:2181,node03:2181")
val fruitTable = TableName.valueOf("fruit")
val tableDescr = new HTableDescriptor(fruitTable)
tableDescr.addFamily(new HColumnDescriptor("info".getBytes))
val admin = new HBaseAdmin(conf)
if (admin.tableExists(fruitTable)) {
admin.disableTable(fruitTable)
admin.deleteTable(fruitTable)
}
admin.createTable(tableDescr)
def convert(triple: (String, String, String)) = {
val put = new Put(Bytes.toBytes(triple._1))
put.addImmutable(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes(triple._2))
put.addImmutable(Bytes.toBytes("info"), Bytes.toBytes("price"), Bytes.toBytes(triple._3))
(new ImmutableBytesWritable, put)
}
val dataRDD: RDD[(String, String, String)] = sc.parallelize(List(("1","apple","11"), ("2","banana","12"), ("3","pear","13")))
val targetRDD: RDD[(ImmutableBytesWritable, Put)] = dataRDD.map(convert)
val jobConf = new JobConf(conf)
jobConf.setOutputFormat(classOf[TableOutputFormat])
jobConf.set(TableOutputFormat.OUTPUT_TABLE, "fruit")
//写入数据
targetRDD.saveAsHadoopDataset(jobConf)
println("写入数据成功")
//读取数据
conf.set(TableInputFormat.INPUT_TABLE, "fruit")
val hbaseRDD: RDD[(ImmutableBytesWritable, Result)] = sc.newAPIHadoopRDD(conf, classOf[TableInputFormat],
classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable],
classOf[org.apache.hadoop.hbase.client.Result])
val count: Long = hbaseRDD.count()
println("hBaseRDD RDD Count:"+ count)
hbaseRDD.foreach {
case (_, result) =>
val key = Bytes.toString(result.getRow)
val name = Bytes.toString(result.getValue("info".getBytes, "name".getBytes))
val color = Bytes.toString(result.getValue("info".getBytes, "price".getBytes))
println("Row key:" + key + " Name:" + name + " Color:" + color)
}
sc.stop()
}
}
铁子们上班之余终于给你们更新完了,太不容易了。
SparkCore也是Spark中重要的一章,又不懂的可以私信我哦!
下一章给大家更新SparkSQL!!!!

创作不易,点个赞吧!!!!