李亚坤:Hadoop YARN在字节跳动的实践
【IT168 专稿】本文根据李亚坤老师在2018年10月17日【第十届中国系统架构师大会】现场演讲内容整理而成。
讲师简介:

李亚坤,哈工大硕士,目前从事分布式计算资源调度系统YARN的研发支持工作,支撑了包括今日头条、抖音短视频、火山小视频、西瓜视频等一系列产品的离线、流式计算任务。
摘要:
字节跳动公司的今日头条、抖音短视频、火山小视频、西瓜视频等一系列产品,在最近几年内数据量一直呈现出爆炸性增长趋势,数据基础架构部门在离线计算、流式计算等多个方向上遭遇到了一系列前所未有的挑战。本次演讲主要介绍从0到4万+计算结点的YARN集群管理,以及在调度优化、流式作业支持等多个方面的经验分享。
分享大纲:
1、IntroductiontoYARN
2、YARN@ByteDance Overview
3、Customization@ByteDance
4、Future Works
正文:
1、IntroductiontoYARN
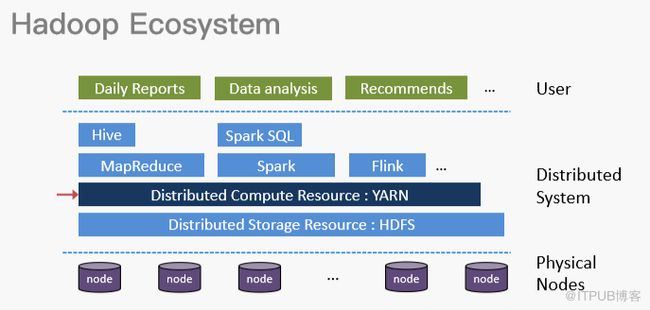
首先,我们将Hadoop生态圈分为三层,从底向上依次是物理层、分布式系统层和用户层。物理层由一系列标准X86服务器组成,这些服务器上跑着开源Linux或者Windows系统。中间是分布式系统层,分别由HDFS服务管理的分布式存储、Yarn管理的分布式计算资源,以及其上的一些计算框架,比如MapReduce、Storm和Flink等组成,这些都是为了方便用户使用并编写分布式应用。最上面是应用层,主要存放日报、进行数据分析,还有推荐模型等训练。本文将重点介绍Yarn所在的分布式计算资源管理层。
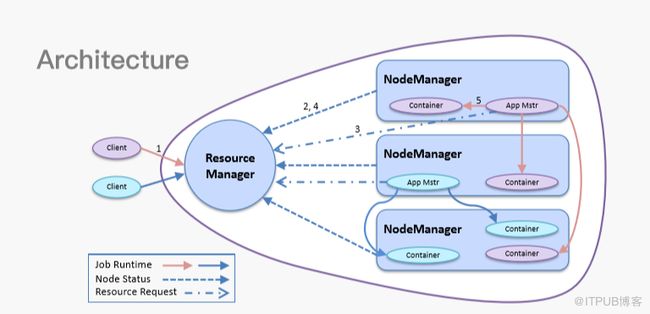
上图为Yarn架构图,Yarn中有两大概念需要普及:一是Resource Manager,这是Yarn的调度大脑。二是NodeManager,由很多Manager组成,是最基本的Yarn计算节点服务,负责执行并监控用户作业。无论是Spark、MapReduce还是Flink,都必须按照Yarn对作业的抽象进行编程,这样才能跑在Yarn之上。
2、YARN@ByteDance Overview
接下来,我将从不同视角向大家介绍Yarn在字节跳动的概览情况。从物理资源来看,所有计算节点全部由基础架构团队管理,目前的流式作业资源占比不到30%,但增长速度很快。今年9月份与去年3月份对比,集群总规模大概涨了15倍。从集群视角出发,我们现在有400左右队列,100左右Label,十个集群大概分布在五个数据中心。从作业视角出发,我们每天大概要完成34万作业,其中,MapReduce大概30万,Spark大概4万,Streaming作业大概2000个。从用户视角出发,我们目前日活用户2000左右(公司内部),月活用户3000左右(公司内部)。我们的用户可从两个维度看,从横向业务维度看,所有对外APP基本都在使用该服务,也有部分公司内部自研且仅为内部提供的基础工具软件。如果从职责上看,上层的推荐、广告和分析,下层的系统运维包括机房网络管理等,都在使用Yarn服务做运算。
3、Customization@ByteDance
接下来,我将介绍定制化方面的事情。首先,我们在使用的Yarn基于社区2.6.0源码,我们大概用了三年多时间,这之中也发现了很多问题,比如在单机群5000台机器时,一个简单的切主就可能导致集群挂掉,比如Yarn原生抢占机制在该版本下有bug。在使用过程中,由于我们的规模较大,因此对稳定性要求更高。同时,由于用户较多,我们在易用性上也做了改进。
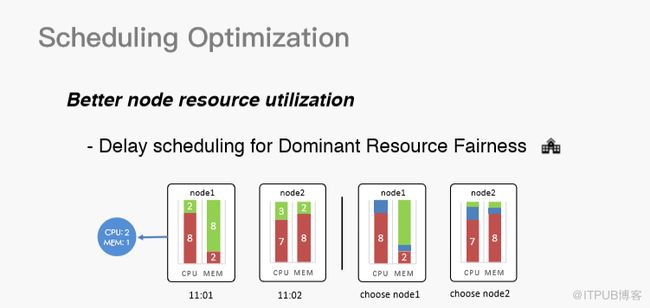
首先,我们来看在调度层面做的定制化。为了提高节点资源利用率而做的优化叫Delay scheduling for Dominant Resource Fairness,这是一个延迟调度。为了主资源的公平性,延迟调度与社区提到的Delay scheduling是完全不同的概念,社区提到的Delay scheduling是根据node的locality进行Delay,如果分配不满足locality就要等待,而我们则是为了节点资源等待。一台机器的计算资源其实有很多维度,CPU和内存是最常见的两个,还有网络IO、磁盘IO和GPU等。以CPU和内存为例,假设现在有一个container,需要申请两个CPU和1G内存,因为Yarn是一个心跳分配机制,如果在11:01时来了一个节点node1,现在闲置了两个CPU和8G内存,理论上是可以分配的,因为我只需要两个CPU和1G内存。如果分配,这台node1的机器就会完全用完CPU,而内存还剩下87%,这部分内存基本就不会有人使用了,这其实是一个非常严重的资源碎片。如果跳过node1,在一段时间之后,node2来了,node2需要1个CPU,2G内存,这也是可以匹配的,并且将资源分配到node2之后,CPU和内存都会有一些剩余,而这些剩余其实可以被用来调度其他作业,资源利用就会得到很大提升,碎片化会降低很多。这套机制也让我们的集群在高峰时段的资源碎片化小于10%,基本维持在5%左右。
但是,这类优化会带来一个问题,就是需要等待一段时间再进行调度。因为Yarn是一个非常重吞吐的调度引擎,等待就代表着牺牲了吞吐,这其实对Yarn来说是不可接受的,因此我们在吞吐上也做了一些优化。简单来说,我们将原生Yarn调度器的单线程改成了多线程版本。
我们把调度器拆分成了读锁和写锁,对要做的作业包括节点进行了合理分区。然后,我们启动了多个线程,让每个线程负责一部分node和作业,这样就可以达到多线程的效果。在测试环境中,我们的测试结果是在物理资源充裕的情况下,容器的吞吐效率比原来有大概一百倍的提升。
接下来,我将介绍抢占方面做的优化。Yarn的优势是更好的利用资源,比如当资源分配完成,A队列的资源没有用,而B队列需要的比较多,B队列就会把A的资源挪过去用。如果A在此时提交作业,就会发现队列已经没有资源了,而B作业没有运行完,也不会释放给A,这就需要强调抢占机制,比如把B作业的部分容器杀死从而释放资源给A。
Yarn 2.6.0本身自带抢占功能,但这基本不可用。举例说明,如果我要申请一个容器,而该容器需要两个核才能跑起来,但是Yarn自带的抢占机制可能会为我在两台机器上各抢占一个核,这基本上是不可用的,这在社区的2.8.0版本中做了重构。我们参考了社区2.8.0版本的代码,在实现重构的基础上做了一些优化,并降低了抢占成本,比如Yarn抢占要么全开,要么不开。 抢占一定会杀死容器,杀死容器肯定会带来集群的不稳定,我们定制了一些优化策略, 比如不针对AM,不杀运行时间过长的容器,一个作业只杀死一定比例以下的容器,一台机器只杀死一定比例以下的容器,以此来减少抢占带来的影响。
除此之外,社区版本的Yarn在节点达到5000台时,如果发生一次切主,这个集群很可能就会挂掉。对此,我们主要做了两件事情,一是设置安全模式,保证其在稳定之后再进行调度;二是分析找到所有不必要事件并直接切掉,这让我们的事件总量下降了800倍左右。 以上措施让集群可以轻松应对万台机器。
在实际生产环境中,我们很多地方都需要考虑高稳定性。对此,我们做得第一件事是动态 Reservation for Fair Scheduler ,因为一个突然之间需要特别大资源的应用很可能会把整个集群卡住,导致其他应用没有资源可用。我们的解决方案是能够Reservation一个上限,并与应用存活时间进行绑定,这可以有效避免整个集群资源被某一个应用全部用掉,而导致其他应用程序没有资源可用。
此处,我们同样进行了优化,我们将label信息存储到了 ZKRMStateStore 中。ZKRMStateStore是原生Yarn用来存放application信息的地方。在Yarn切主时,ZKRMStateStore会把application读出来,但是原生Yarn会把label放到HDFS之上,这就会让Yarn对HDFS产生强依赖,当HDFS服务不可用,Yarn一定会挂掉。为了解除强依赖,我们把label信息存放到ZKRMStateStore 中。当切主时,load应用信息的同时会把label信息也load得出来,降低切主时间总长度。并彻底摆脱对HDFS的强依赖,即便HDFS服务挂了,也不会影响Yarn框架的使用。另外,我们修改了容器log的部分策略,比如上传策略,主要目的是增强功能稳定性,同时降低对HDFS服务的压力。
当集群规模较大时,用户上传的作业、容器log等信息会把HDFS目录打满,因为HDFS目录有默认的存储上限。针对该情况,我们做了一个哈希希望可以分得更均匀。此外,我们会根据Resource Manager里的压力负载将NodeManager心跳设置为动态, 如果Resource Manager负载较大,它会自动地把Node Manager的心跳时间设置得更大一些,这样可以减少一些事件,并减少对Resource Manager的影响。当集群规模较大时,经常会出现Yarn集群与HDFS集群不匹配的情况,比如Yarn集群是ABCD,HDFS集群是BCDE。当按照本地性策略申请资源时,由于没有版本的计算结点,会等待直到超时退出,我们提前把这些信息保存下来,如果申请的资源在集群内一开始就不存在,我们直接降级成any任何节点都可以。
接下来,我将介绍资源隔离相关操作。更好得资源隔离可以提高在一台机器上同时运行多个作业的效率,我们使用了一种叫NUMA awareness 的技术来做节点内的资源隔离。传统的资源隔离主要通过Cgroup限制使用率。当多个作业同时运行在一台机器上时,虽然作业跑在不同的CPU和内存上,但要共用系统总线带宽和CPU缓存,作业交替运行刷缓存,导致CPU缓存基本就是不可用的状态。
NUMA是一种感知架构,对CPU和内存进行绑定,他们之间有独立的带宽,如果一个CPU访问自己的内存,速度会很快,反之访问其他CPU的内存,速度会很慢。Node Manager起作业时,会直接对作业的CPU和内存进行绑定,这样会有更好的隔离性。最终,我们的生产环境在实测中实现了部分场景15%的效率提升。
接下来,我将介绍对流式作业的支持。因为Yarn起初设计是为了批处理作业,为了更高的吞吐而设计的,虽然后期也可以支持流式作业,但是Yarn天生并不适合跑流式作业。前文提到,我们公司目前有30%的机器在运行流式作业,因此,我们在这方面做了很多努力,我主要分享两个事情:一是端口危机,因为流式作业经常与在线服务交互,期间会频繁建立或断开连接。受限于TCP连接断开机制,如果发生意外中断,系统会等待一段时间才彻底把端口释放,这样可以保证它的完备性,比如经常在Node Manager里重启时会发现端口被占用,经验证又发现端口未被占用。要想解决该问题,一开始就需要考虑特定服务的端口需提前做好预留。因为流式作业需要长时间运行,因此对外部运行时环境依赖是很苛刻的,比如Yarn的Linux container Executor等脚本运行时都需要依赖外部文件,一旦这些文件出问题,就会导致Manager不正常,甚至其上的所有流式容器全部挂掉。
我们还做了容器log的实时查看功能。 在Yarn的设计里,日志聚合在作业结束后才开始,但流式作业可以认为是不结束的,因此就永远不会记录容器log,这也导致用户查看log不是很方便,我们让用户在作业运行过程中通过配置实时把日志打到Kafka,再到ES进行索引,索引完之后,用户可以实时在Kibana页面对作业进行检索。
接下来,我将介绍我们针对多区域、多数据中心和多集群场景做的事情。首先,我们设计了统一UI,包含用户所有集群的Job、label和队列,同时还进行了一些队列管理,换句话说,所有集群队列都可以在UI进行管理。其次,我们做了统一hadoop client,这与社区的区别是什么呢?用户可以在配置中写一个简单的conf,指明集群的名字,这个作业就会被提交到特定集群。
在Yarn的使用过程中,用户申请资源是一个很头疼的问题,一般用户都会提的比较大,这会造成很多资源浪费,这些资源并没有被真实使用。我们针对这个问题做了两方面努力。首先,我们使用了Dtop,Dtop会实时收集所有容器的物理资源使用情况。
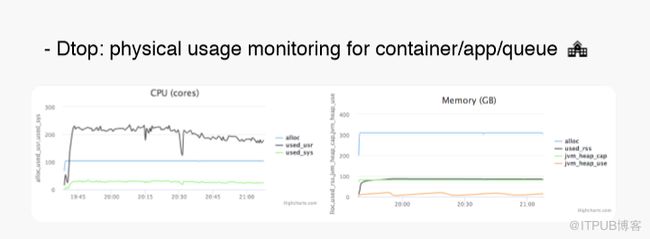
当然,物理资源不仅局限于CPU和内存,还有磁盘IO、网络IO等。统计完之后,我们会有一个流式作业把这些信息实时聚合。之后,用户可以在web界面上看到自己应用的资源使用情况,也可以查看单个容器的资源情况,或者整个队列的资源情况。
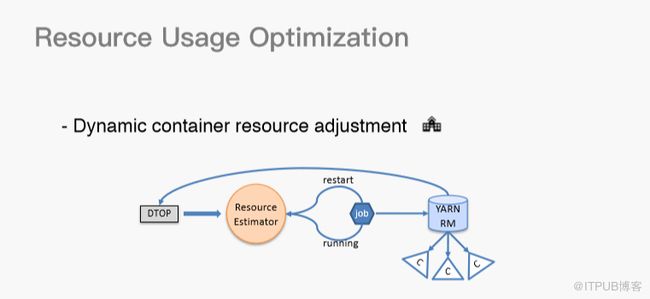
在数据的基础上,我们做了更进一步的实现——动态容器资源调整。首先,我们在Yarn上做了一些开发,因为社区最新版其实已经支持容器动态调整,也就是运行时。我们对这部分功能进行了改进,做了一个比较简单实用的版本。我们通过Dtop对数据进行实时处理,通过Resource预估器对所有应用信息进行实时聚合。如果用户提交一个作业,重启时,Resource预估器可以表明现在需要申请的资源数。在作业运行过程中,它也可以调整流式作业在不同时段,比如高峰期的资源分配。
在易用性层面,我们做了三件事情。首先,我们做了default队列,用户可以配置默认队列,之后提交作业时默认到该队列。其次,我们做了异常情况通知,当用户作业或者运行时出现问题,我们都可以通过内部通讯软件实时把信息反馈给用户。我们重新设计了Yarn UI,聚合了全球所有集群label、job等信息,用户可以非常方便的通过一个入口查看所有信息。最后,Troubleshooting支持在易用性里也是一个非常重要的点。由于每天的作业量很大,作业运行失败的情况时有发生,我们需要快速定位并解决问题。
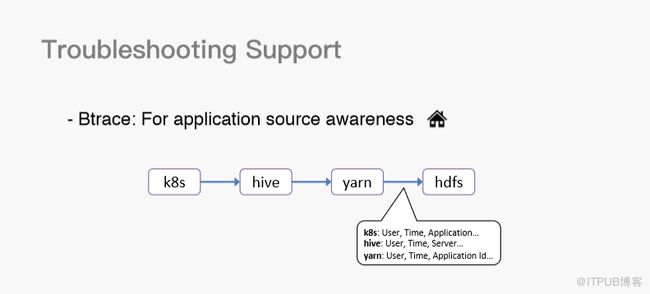
首先,我介绍一下Btrace工具。该工具主要为了应用源追踪。比如,我在K8S里起一个在线服务,这在特定场景下会提交一个Hive的SQL语句,该语句又会被翻译成MapReduce的job提交到Yarn之上,Yarn上的MapReduce的job又会访问HDFS服务,访问HDFS服务很可能会把离线带宽打满,此时,通过Btrace工具,我们可以在HDFS中快速定位访问用户的信息。
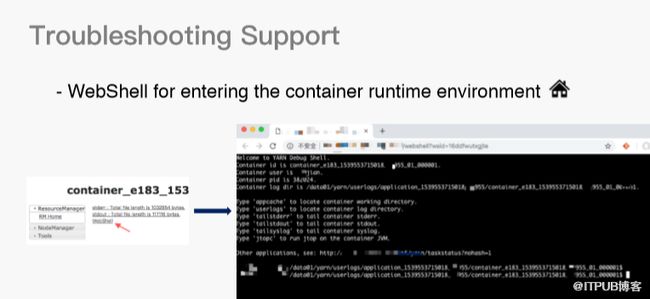
接下来是WebShell 工具,该工具主要是为了快速进入容器运行时环境。在原生Yarn容器界面,我们加了一个按钮叫WebShell,用户点击该按钮就会打开一个浏览器页面,该页面显示容器的本地运行环境。这样,用户就可以快速在该环境中检查本地文件信息状态是否正常。
关于Troubleshooting,还有两件事情,其一是Reservation可视化,可以让队列非常清楚是否因为Reservation而导致资源不足;其二是History Server ,因为Yarn原生History Server 受限于ZK中Znode的大小,一般可存最近的一万个作业,这对于我们集群而言是远远不够的。为了解决该问题,我们把作业信息实时拉到外部存储,我们能够为用户提供七天的历史作业查看情况。
除此之外,我们还开发了一些非常有意思的工具,比如Truman。Truman的目标是使用真实的RM,在其它机器上虚构出NM和应用,并且这些NM跟应用表现的与真实环境一样,只是资源使用非常少,甚至基本不占用资源。这样,我们就可以较低成本测试RM的性能。另一个工具是ClusterManager,可中心化服务管理节点上声明的计算资源和label信息,该功能在社区有实现,但会把权力下放给Node Manager。
另一个是LogIndexService,可以实时抓取用户作业的容器log,并传递到Kafka和ES,最后通过Kibana页面展示。我们的运维平台工具叫YAOP,这是一个全球多机房统一运维管理平台,负责管理所有用户的job、队列、label和节点信息。
4、Future Works
未来,我们需要做两件事情。 一是Federation机制,我们需要通过该机制对多个同一IDC 集群进行联合,为用户提供统一视图,并提高跨集群资源利用率;二是Docker on yarn ,为了更好地实现一台物理机之内的资源隔离。
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/31545816/viewspace-2221199/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/31545816/viewspace-2221199/