CDH5.16+Flink1.11.0+zepplien初步踩坑
白斩鸡的博客:https://me.csdn.net/weixin_47482194
====================================================================================
经历了几天的折磨,在白斩鸡的帮助下完成集群任务提交运行:
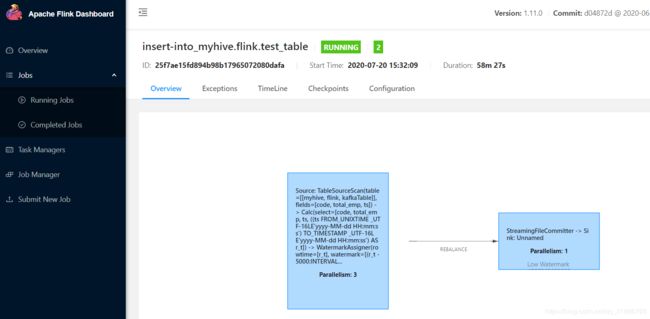
zeppelin提交任务运行:
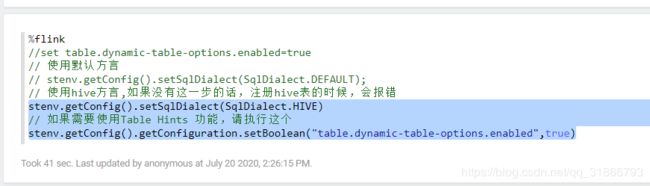
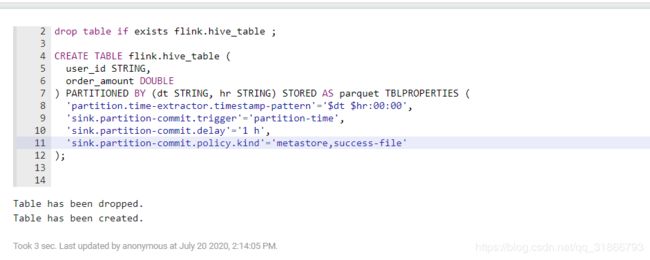
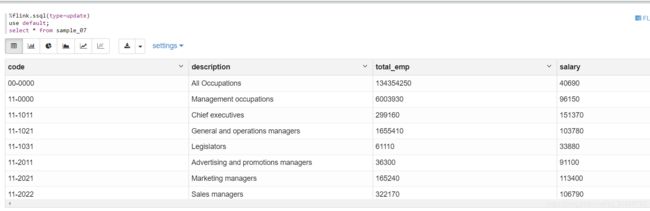 遇到了很多的坑,其中很多报错信息没有留下来或者截图,相对原生集群与CDH集群的不同之处,就在于依赖包的问题,和解决依赖冲突,可以先参考1篇文章。
遇到了很多的坑,其中很多报错信息没有留下来或者截图,相对原生集群与CDH集群的不同之处,就在于依赖包的问题,和解决依赖冲突,可以先参考1篇文章。
https://developer.aliyun.com/article/761469.
之前不管怎么解决依赖冲突,或者放包最后都指向一个错误:
org.apache.flink.client.program.ProgramInvocationException: The main method caused an error: Failed to create Hive Metastore client
at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:302)
at org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:198)
at org.apache.flink.client.ClientUtils.executeProgram(ClientUtils.java:149)
at org.apache.flink.client.cli.CliFrontend.executeProgram(CliFrontend.java:699)
at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:232)
at org.apache.flink.client.cli.CliFrontend.parseParameters(CliFrontend.java:916)
at org.apache.flink.client.cli.CliFrontend.lambda$main$10(CliFrontend.java:992)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1924)
at org.apache.flink.runtime.security.contexts.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41)
at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:992)
Caused by: org.apache.flink.table.catalog.exceptions.CatalogException: Failed to create Hive Metastore client
at org.apache.flink.table.catalog.hive.client.HiveShimV120.getHiveMetastoreClient(HiveShimV120.java:58)
at org.apache.flink.table.catalog.hive.client.HiveMetastoreClientWrapper.createMetastoreClient(HiveMetastoreClientWrapper.java:240)
at org.apache.flink.table.catalog.hive.client.HiveMetastoreClientWrapper.(HiveMetastoreClientWrapper.java:71)
at org.apache.flink.table.catalog.hive.client.HiveMetastoreClientFactory.create(HiveMetastoreClientFactory.java:35)
at org.apache.flink.table.catalog.hive.HiveCatalog.open(HiveCatalog.java:223)
at org.apache.flink.table.catalog.CatalogManager.registerCatalog(CatalogManager.java:191)
at org.apache.flink.table.api.internal.TableEnvironmentImpl.registerCatalog(TableEnvironmentImpl.java:331)
at dataware.TestHive.main(TestHive.java:39)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:288)
... 11 more
Caused by: java.lang.NoSuchMethodException: org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(org.apache.hadoop.hive.conf.HiveConf)
at java.lang.Class.getMethod(Class.java:1786)
at org.apache.flink.table.catalog.hive.client.HiveShimV120.getHiveMetastoreClient(HiveShimV120.java:54)
... 23 more
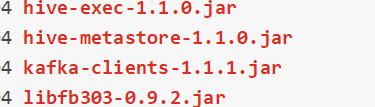
主要还是集群运行的依赖问题,有位同行说他用的CDH,在集群Flink lib下的依赖:
实际这是官网的推荐:
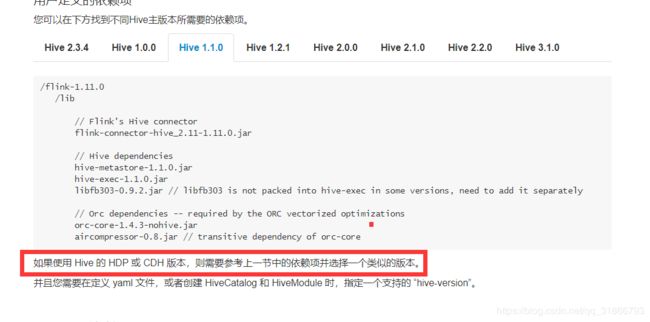
跟着官网走,下载
flink-sql-connector-hive-1.2.2_2.11-1.11.0.jar 包放入flink lib下
然后还有其余的包:
libfb303-0.9.3.jar
最重要的来了:
hive-exec-1.1.0-cdh5.16.2.jar
hive-metastore-1.1.0-cdh5.16.2.jar
这两个包在CDH 的/opt/cloudera/parcels/CDH/jars目录下拷贝过来。
如果启动之后还报错,比如下面的错误:
Caused by: org.apache.flink.util.FlinkException: Failed to execute job 'UnnamedTable__5'. at org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.executeAsync(StreamExecutionEnvironment.java:1823) at org.apache.flink.api.java.ScalaShellStreamEnvironment.executeAsync(ScalaShellStreamEnvironment.java:75) at org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.execute(StreamExecutionEnvironment.java:1713) at org.apache.flink.table.planner.delegation.ExecutorBase.execute(ExecutorBase.java:52) at org.apache.flink.table.api.internal.TableEnvironmentImpl.execute(TableEnvironmentImpl.java:1198) at org.apache.zeppelin.flink.sql.AbstractStreamSqlJob.run(AbstractStreamSqlJob.java:161) ... 15 more Caused by: org.apache.flink.runtime.client.JobSubmissionException: Failed to submit JobGraph. at org.apache.flink.client.program.rest.RestClusterClient.lambda$submitJob$7(RestClusterClient.java:366) at java.util.concurrent.CompletableFuture.uniExceptionally(CompletableFuture.java:870) at java.util.concurrent.CompletableFuture$UniExceptionally.tryFire(CompletableFuture.java:852) at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:474) at java.util.concurrent.CompletableFuture.completeExceptionally(CompletableFuture.java:1977) at org.apache.flink.runtime.concurrent.FutureUtils.lambda$retryOperationWithDelay$8(FutureUtils.java:292) at java.util.concurrent.CompletableFuture.uniWhenComplete(CompletableFuture.java:760) at java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(CompletableFuture.java:736) at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:474) at java.util.concurrent.CompletableFuture.postFire(CompletableFuture.java:561) at java.util.concurrent.CompletableFuture$UniCompose.tryFire(CompletableFuture.java:929) at java.util.concurrent.CompletableFuture$Completion.run(CompletableFuture.java:442) ... 3 more Caused by: org.apache.flink.runtime.rest.util.RestClientException: [Internal server error.,
SinkConversionToTuple2 -> Sink: Zeppelin Flink Sql Stream Collect Sink bab9134d-8f8f-4184-919e-fbf10718225e': Loading the input/output formats failed: at org.apache.flink.runtime.executiongraph.ExecutionGraphBuilder.buildGraph(ExecutionGraphBuilder.java:216) at org.apache.flink.runtime.scheduler.SchedulerBase.createExecutionGraph(SchedulerBase.java:269) at org.apache.flink.runtime.scheduler.SchedulerBase.createAndRestoreExecutionGraph(SchedulerBase.java:242) at org.apache.flink.runtime.scheduler.SchedulerBase. (SchedulerBase.java:229) at org.apache.flink.runtime.scheduler.DefaultScheduler. (DefaultScheduler.java:119) at org.apache.flink.runtime.scheduler.DefaultSchedulerFactory.createInstance(DefaultSchedulerFactory.java:103) at org.apache.flink.runtime.jobmaster.JobMaster.createScheduler(JobMaster.java:284) at org.apache.flink.runtime.jobmaster.JobMaster. (JobMaster.java:272) at org.apache.flink.runtime.jobmaster.factories.DefaultJobMasterServiceFactory.createJobMasterService(DefaultJobMasterServiceFactory.java:98) at org.apache.flink.runtime.jobmaster.factories.DefaultJobMasterServiceFactory.createJobMasterService(DefaultJobMasterServiceFactory.java:40) at org.apache.flink.runtime.jobmaster.JobManagerRunnerImpl. (JobManagerRunnerImpl.java:140) at org.apache.flink.runtime.dispatcher.DefaultJobManagerRunnerFactory.createJobManagerRunner(DefaultJobManagerRunnerFactory.java:84) at org.apache.flink.runtime.dispatcher.Dispatcher.lambda$createJobManagerRunner$6(Dispatcher.java:388) ... 7 more Caused by: java.lang.Exception: Loading the input/output formats failed: at org.apache.flink.runtime.jobgraph.InputOutputFormatVertex.initInputOutputformatContainer(InputOutputFormatVertex.java:155) at org.apache.flink.runtime.jobgraph.InputOutputFormatVertex.initializeOnMaster(InputOutputFormatVertex.java:59) at org.apache.flink.runtime.executiongraph.ExecutionGraphBuilder.buildGraph(ExecutionGraphBuilder.java:212) ... 19 more Caused by: java.lang.RuntimeException: Deserializing the input/output formats failed: Could not read the user code wrapper: invalid type code: 05 at org.apache.flink.runtime.jobgraph.InputOutputFormatContainer. (InputOutputFormatContainer.java:68) at org.apache.flink.runtime.jobgraph.InputOutputFormatVertex.initInputOutputformatContainer(InputOutputFormatVertex.java:152) ... 21 more Caused by: org.apache.flink.runtime.operators.util.CorruptConfigurationException: Could not read the user code wrapper: invalid type code: 05 at org.apache.flink.runtime.operators.util.TaskConfig.getStubWrapper(TaskConfig.java:290) at org.apache.flink.runtime.jobgraph.InputOutputFormatContainer. (InputOutputFormatContainer.java:66) ... 22 more Caused by: java.io.StreamCorruptedException: invalid type code: 05 at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1601) at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2287) at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:2167) at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2069) at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1573) at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2287) at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:2211) at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2069) at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1573) at java.io.ObjectInputStream.readObject(ObjectInputStream.java:431) at java.util.HashMap.readObject(HashMap.java:1412) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at java.io.ObjectStreamClass.invokeReadObject(ObjectStreamClass.java:1170) at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:2178) at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2069) at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1573) at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2287) at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:2211) at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2069) at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1573) at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2287) at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:2211) at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2069) at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1573) at java.io.ObjectInputStream.readObject(ObjectInputStream.java:431) at org.apache.flink.util.InstantiationUtil.deserializeObject(InstantiationUtil.java:576) at org.apache.flink.util.InstantiationUtil.deserializeObject(InstantiationUtil.java:562) at org.apache.flink.util.InstantiationUtil.deserializeObject(InstantiationUtil.java:550) at org.apache.flink.util.InstantiationUtil.readObjectFromConfig(InstantiationUtil.java:511) at org.apache.flink.runtime.operators.util.TaskConfig.getStubWrapper(TaskConfig.java:288) ... 23 more End of exception on server side>] at org.apache.flink.runtime.rest.RestClient.parseResponse(RestClient.java:390) at org.apache.flink.runtime.rest.RestClient.lambda$submitRequest$3(RestClient.java:374) at java.util.concurrent.CompletableFuture.uniCompose(CompletableFuture.java:952) at java.util.concurrent.CompletableFuture$UniCompose.tryFire(CompletableFuture.java:926) ... 4 more
看到这种错误信息,估计又是一头包了。我们看官网怎么说的:
https://ci.apache.org/projects/flink/flink-docs-release-1.11/zh/dev/table/hive/#ddl
所以要么依赖冲突,要么依赖缺失。

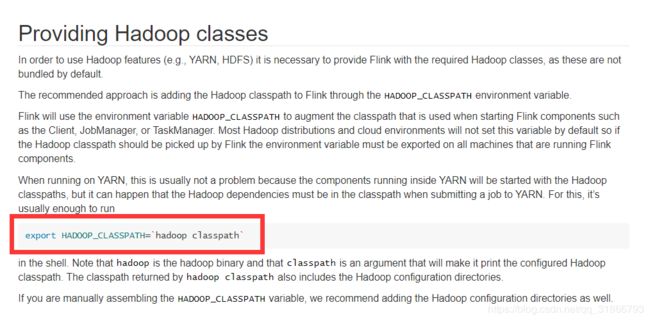
我们在CDH环境把HADOOP_CLASSPATH的路径配置到环境变量,或者 手动来
执行命令: hadoop classpath

拷贝下面的内容:
放在任务执行命令之前:
export HADOOP_CLASSPATH='/etc/hadoop/conf:/opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/hadoop/libexec/../../hadoop/lib/*:/opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/hadoop/libexec/../../hadoop/.//*:/opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/hadoop/libexec/../../hadoop-hdfs/./:/opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/hadoop/libexec/../../hadoop-hdfs/lib/*:/opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/hadoop/libexec/../../hadoop-hdfs/.//*:/opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/hadoop/libexec/../../hadoop-yarn/lib/*:/opt/cloudera/parcels/CDH-5.16.2-1.cdh5.16.2.p0.8/lib/hadoop/libexec/../../hadoop-yarn/.//*:/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/lib/*:/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/.//*:/opt/cloudera/parcels/CDH/jars';./bin/flink run -c dataware.TestHive /wyyt/software/flink-1.11.0/test-1.0-SNAPSHOT.jar
如果还是不行,报缺包啥的,直接修改Flink启动脚本,在集群启动的时候直接加载hadoop的环境:
vim start-cluster.sh
// 加入hadoop classPath
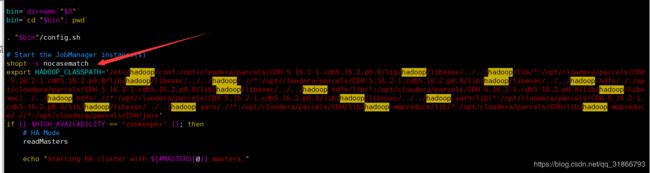
其他几个版本也可以加入。
现在写的有点乱,有点简单。如果遇到这种问题的人多了,我会完善这个文档的。
不过好像用Flink 1.11.0的人很少啊。。
忘记了测试代码很简单:
public class StreamingWriteHive { private static final String KAFKA_SQL = "CREATE TABLE kafkaTable (\n" + " code STRING," + " total_emp INT ," + " ts bigint ," + " r_t AS TO_TIMESTAMP(FROM_UNIXTIME(ts,'yyyy-MM-dd HH:mm:ss'),'yyyy-MM-dd HH:mm:ss'),\n" + " WATERMARK FOR r_t AS r_t - INTERVAL '5' SECOND " + ") WITH (" + " 'connector' = 'kafka'," + " 'topic' = 'flink_dwd_test7'," + " 'properties.bootstrap.servers' = 'dev-ct6-dc-worker01:9092,dev-ct6-dc-worker02:9092,dev-ct6-dc-worker03:9092'," + " 'properties.group.id' = 'test1'," + " 'format' = 'json'," + " 'scan.startup.mode' = 'earliest-offset'" + ")"; public static void main(String[] args) throws Exception { StreamExecutionEnvironment bsEnv = StreamExecutionEnvironment.getExecutionEnvironment(); EnvironmentSettings bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build(); StreamTableEnvironment tEnv = StreamTableEnvironment.create(bsEnv, bsSettings); bsEnv.enableCheckpointing(5000); bsEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); String name = "myhive"; String defaultDatabase = "flink"; String hiveConfDir = "/wyyt/software/flink-1.11.0"; String version = "1.1.0"; HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir, version); tEnv.registerCatalog("myhive", hive); tEnv.useCatalog("myhive"); tEnv.getConfig().setSqlDialect(SqlDialect.DEFAULT); tEnv.executeSql("drop table if exists kafkaTable"); tEnv.executeSql(KAFKA_SQL); tEnv.getConfig().setSqlDialect(SqlDialect.HIVE); tEnv.executeSql("drop table if exists test_table"); // 如果hive中已经存在了相应的表,则这段代码省略 String hiveSql = "CREATE TABLE test_table (\n" + " f_random_str STRING,\n" + " f_sequence INT" + ") partitioned by (dt string,hr string) " + "stored as PARQUET " + "TBLPROPERTIES (\n" + " 'partition.time-extractor.timestamp-pattern'='$dt $hr:00:00',\n" + " 'sink.partition-commit.delay'='5 s',\n" + " 'sink.partition-commit.trigger'='partition-time',\n" + // " 'sink.partition-commit.delay'='1 m',\n" + " 'sink.partition-commit.policy.kind'='metastore'" + ")"; tEnv.executeSql(hiveSql); String insertSql = "insert into test_table SELECT code, total_emp, " + " DATE_FORMAT(r_t, 'yyyy-MM-dd'), DATE_FORMAT(r_t, 'HH') FROM kafkaTable"; tEnv.executeSql(insertSql).print(); } }
pom文件:
org.apache.flink flink-json ${flink.version} org.apache.flink flink-core ${flink.version} provided org.apache.flink flink-table-api-java-bridge_${scala.binary.version} ${flink.version} provided org.apache.flink flink-table-api-scala-bridge_${scala.binary.version} ${flink.version} provided org.apache.flink flink-table-planner_${scala.binary.version} ${flink.version} provided org.apache.flink flink-table-planner-blink_${scala.binary.version} ${flink.version} provided org.apache.flink flink-table-common 1.11.0 provided org.apache.flink flink-streaming-scala_${scala.binary.version} ${flink.version} provided org.apache.flink flink-clients_${scala.binary.version} ${flink.version} provided org.apache.flink flink-connector-kafka_2.11 1.11.0 org.apache.flink flink-connector-hive_2.11 1.11.0 provided org.apache.hive hive-exec 1.1.0 provided org.apache.hadoop hadoop-client 2.7.3 provided
要记录把hive-site.xml的配置文件放在代码写的集群路径下。